What It Is: Understanding the current state of IT within an organization requires a thoughtful process for evaluating how it is structured, aligned, and operating in concert with business needs and expectations. That process is typically referred to as an “IT Assessment”, where an outside reviewer or firm provides perspective on how an IT organization is performing and recommended actions to drive improvement.
Why It Matters: One of the benefits and challenges of working within technology has always been the continuous change and complexity that comes with trying to deliver advanced capabilities to meet business needs and drive competitive advantage, while doing so at speed, securely and reliably, and with quality. Even the most performant organization has opportunities to improve, and the value in IT Assessment is to provide a line of sight to where the organization is and opportunities to improve in the interest of continuing to drive excellence in the value and quality of service delivered.
Key Concepts
There are three fundamental pillars around which IT excellence should be evaluated, they are:
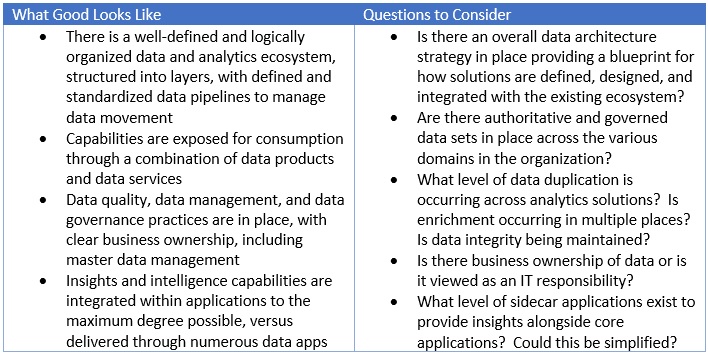
Business Enablement – how well IT capabilities align and support business needs
Delivery Excellence – how well the IT organization delivers and manages the technology footprint in place to support and enable the business
Operational Excellence – how healthy and well-managed the IT organization is from an operating perspective, irrespective of delivery execution and the technology footprint itself
The remainder of this article will be focused on nineteen dimensions across these three pillars, in the interest of both defining “What Good Looks Like” in each dimension (in a perfect world) and some key “Questions to Consider” in each case, as a means to explore the current situation.
It is worth noting that there are and will be industry-specific considerations that come into play beyond what is identified below, but “IT is IT” to a degree, regardless of industry, and I would argue that most or all of what is listed below should apply to the vast majority of technology organizations. The model can and should be extended where appropriate to address an such considerations where it is important to do so.
The considerations themselves are also top-of-mind items, but not meant to be exhaustive, as secondary areas of exploration would tend to surface through the process of understanding and discussing the dimensions below. Hopefully this is a good start… feedback is certainly welcome where something significant may have been missed.
There are many elements that influence achieving excellence with IT and it is a given that no environment would match up to the “perfect world” that is described across the dimensions above and that’s completely fine. The point is to aspire to achieve excellence, then have a strategy and plan to continuously head in the right direction. Where we don’t have a plan or aren’t focused on improving what we do on a day-to-day basis, the odds are that we won’t do it or won’t achieve sustainable improvements over time. I hope the information was helpful and thought-provoking.
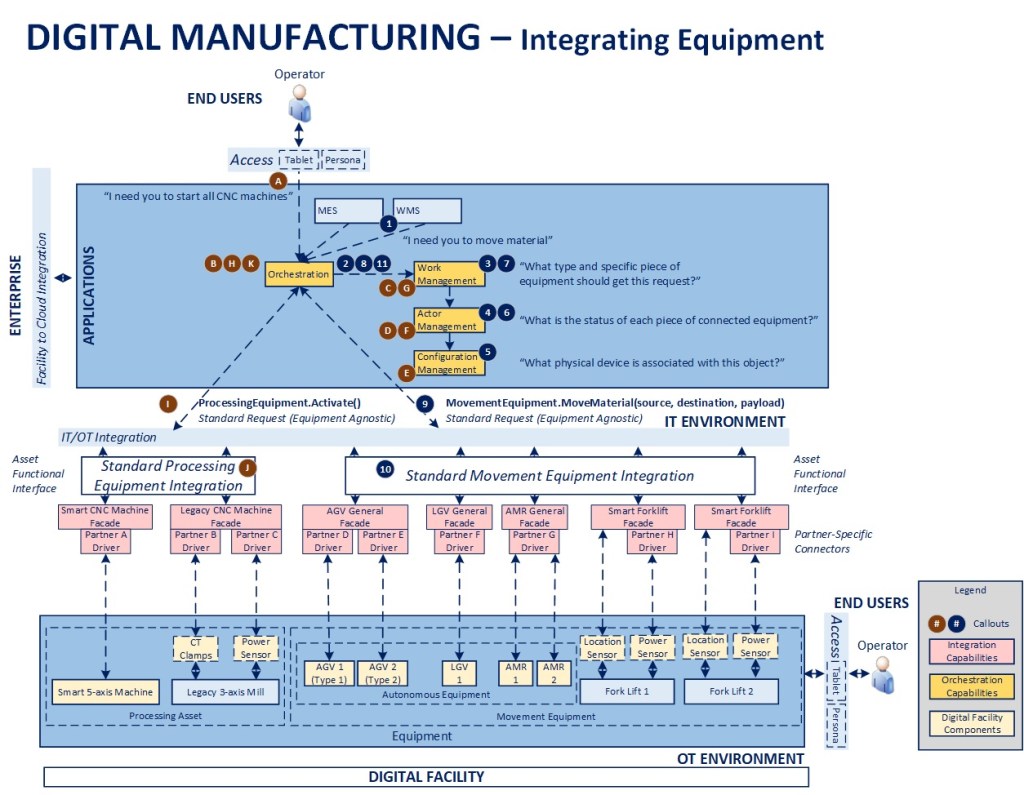
What It Is: Creating a digitally connected manufacturing environment that enables modernization and optimization requires a clear integration strategy that can align, leverage, and synthesize new and existing elements in a thoughtful and deliberate way
Why It Matters: It is often the case that we are in a “brownfield” environment where we don’t have the opportunity to “start from scratch” when it comes to modernization because of the sunk cost that exists in facilities across an enterprise. By leveraging strategic integration, we maximize existing investments, provide resiliency, and create agility that will more rapidly generate ROI on new investments over time
Key Concepts
The above diagram will be used as a reference for the remainder of this article. I have specifically left out facility data and enterprise components to focus largely on configuration management and integration. To understand the blueprint overall and concepts related to orchestration, please see the links at the bottom of this article. As there are many levels to this topic, I will focus on the main points in the interest of communicating the concepts overall.
Framework-Driven Design – The foundation of the overall blueprint is the premise that manufacturing facilities can be treated as a configuration of logical components that can be managed through orchestration as part of a digitally connected ecosystem
Building the right bridges – Considerable integration is built on a point-to-point basis, hard-wiring one component to the next, making things brittle, adding maintenance cost, and making change extremely difficult. The goal in this approach is to identify processes where value can be created, selectively moving from a hard-wired to a model-driven integration approach that maximizes existing investments, increasing resiliency, and promotes longer-term agility
Wrap existing assets – To the maximum extent possible, accelerate the modernization process by instrumenting and adding a digital wrapper around legacy equipment to allow it to integrate seamlessly with more modern digital capabilities and equipment
Standardize integration – Create an Asset Functional Interface (AFI) that establishes a “manage-by-contract” environment where APIs and data exchanged are standardized to insulate the central orchestration framework from the underlying equipment executing the instructions. These standards then enable a much more plug-and-play and “certified” environment where partner components can be aligned to the specs, deemed compliant, and integrated more rapidly and seamlessly over time
Leveraging a Unified Namespace (UNS) – Pivoting from a hard-wired to a more standardized integration architecture also creates the opportunity to shift relevant transactions towards a more modern, event-driven architecture that is more resilient and plug-and-play, where messaging and data standards can evolve over time, leveraging a topic structure that is partner-neutral and allows for ongoing modernization
Layered integration – Equipment integration itself is accomplished first through a set offaçades that are configured to expose and subscribe to the relevant portions of the AFI for a specific piece of connected equipment. There is then a secondary layer of partner-specificdrivers that provide for any additional data transformation required across various partner-specific devices or versions of devices that may be in place over time. One important point to note from an implementation standpoint is to consider the latency involved in data publication across equipment, as downstream analytics will need a relatively consistent baseline to benchmark operating metrics. Overall, the goal would be to have streaming data available as close to “near-real-time” regardless of the integration pattern as possible
Providing standardization in a non-standard world – By decoupling, integrating, and orchestrating high value processes between core systems and across critical assets, we create a strategic, reusable set of infrastructure assets that can work with new and old equipment, across facilities, and that can also be integrated with one or more ERP, MES, WMS, EAM, and other systems that may be in place across a heterogeneous facilities environment. The speed-to-market for delivering new capabilities and ROI on investments associated with this level of reusable infrastructure is considerably higher over time than working within the highly constrained, tightly coupled and diverse environments in place across many manufacturing organizations today
Enabling agentic integration – Moving to an API-centric environment that supports orchestration for critical, high value operations sets the stage for agentic integration for operators and end users. Agents can only initiate and orchestrate processes and transactions that are exposed, and putting this core infrastructure in place would be a stepping stone towards an enterprise-ready agentic infrastructure environment within manufacturing facilities
Key Components
While the previous article on the power of orchestration covers the conceptual role of these components, I wanted to review these four in the interest of setting up the two example scenarios that will follow:
Configuration Management – Foundational to the model is the concept that each facility will have an asset registry that serves as the single source of truth on all connected components and key characteristics that are necessary to leverage them as part of a digitally connected and orchestrated ecosystem. This asset registry then acts as a conceptual facility DNS that helps map the logical entities to the physical environment for the purposes of enabling orchestration. Example attributes would be the logical component type, specific type of underlying equipment, product manufacturer and associated version (as appropriate), any connected devices (e.g., a legacy forklift may have multiple smart devices connected to it), etc.
Actor Management – Once assets are registered and connected via Configuration Management, this component keeps the active state of all equipment, whether it is in service, requires maintenance, is awaiting work, its current workload/request queue, telemetry data, etc.
Work Management – This component acts as an intelligent dispatcher, defining rules for what equipment should be used to accomplish different tasks based on status provided by Actor Management and various operating conditions associated with the request. For example, only forklifts are used to service requests for certain zones in a warehouse, or in the event that no AMRs are available in a given zone to process requests, a forklift is automatically dispatched as a secondary approach to minimize production downtime
Orchestration – This is the “brains” of the facility, driving and coordinating critical processes, ensuring service-level assumptions are met, and that desired outcomes are achieved, leveraging work management to assign tasks that are part of configured workflows
Two Examples
In the interest of showing the relationships across components from a process standpoint, here are two simplified examples (I’m not trying to call out all the technical detail or steps, just the base concepts).
Start Up
First, assume that there are two CNC machines in a facility, one older piece of equipment and one smart CNC machine. The legacy machine is fitted with a “digital backpack” of sensors and a gateway and registered, along with the smart CNC machine, so that they appear as two devices in the facility configuration. Their state is tracked in the Actor Management component on a continual basis.
Scenario 1 – There was a recent shutdown and an operator wants to restart all connected CNC equipment (STEPS A-K in the diagram)
The operator initiates a request though their connected device (assuming their persona has the necessary permissions)
The request is published and received by the Orchestration component, which initiates a start up process. The first step is to publish a request for all stopped CNC machines
Work Management receives the request and publishes a request for a list of all stopped CNC machines
Actor Management receives the request and publishes a request for all registered CNC machines that is received by Configuration Management
Configuration Management receives the request, interrogates its data store and publishes the list of connected machines back to the facility message bus
Actor Management receives the message and checks the list against those machines presently represented in its facility model, creating new objects as required for missing items, and publishing the list of machines showing a status of “stopped” back to the queue
Work Management receives the list, checks for any safety interlocks or other operating conditions present that would prevent starting up each item in the list, then publishes the resulting set of items back to the queue
The Orchestrator receives the list and then sequentially processes each item
The Orchestrator sends a standard Activate message
The message is processed by the Façade for each piece of equipment and a result is provided in response to the request. If the machine doesn’t have the capability for an automated restart, a message is sent to the appropriate Operator via the connected worker environment to perform the activity manually
The Orchestrator checks for any error conditions, notifies an operator and/or supervisor if required, then moves to the next piece of equipment until the process is complete. When the process is completed successfully, the transactional performance data is recorded and the workflow is completed
In an agentic future, the entire process above could be issued via voice command through a connected worker solution, including potentially remotely (depending on the infrastructure in place).
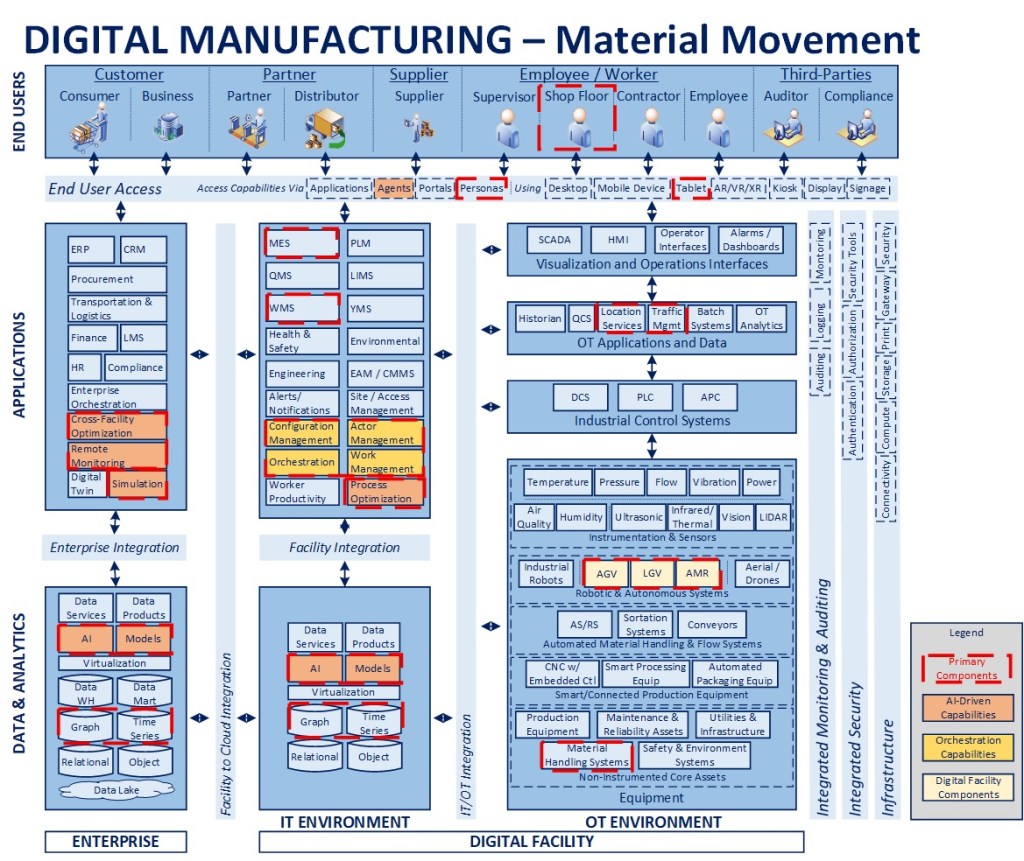
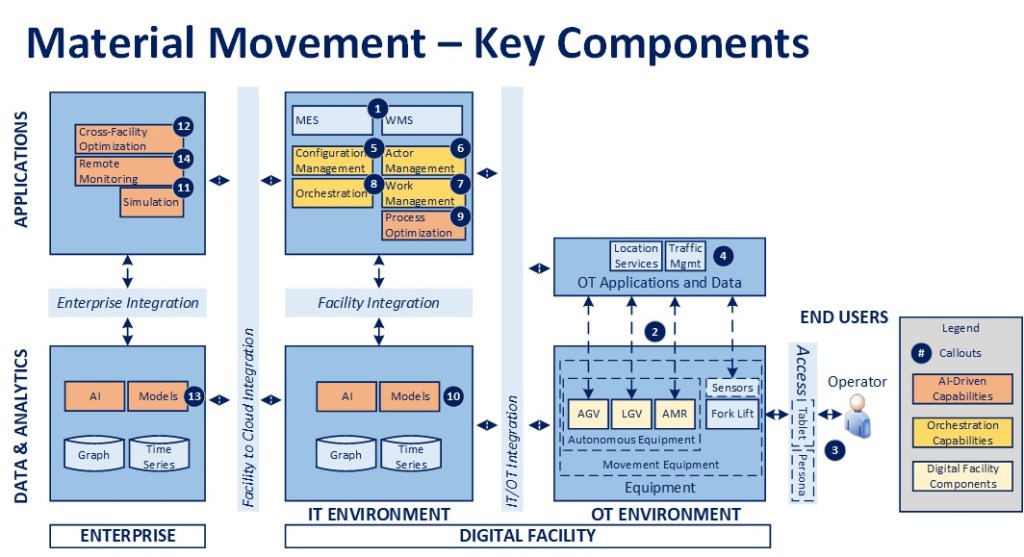
Material Movement
Second, assume that there is a fleet of material movement equipment in a facility, from 20-year-old forklifts to modern AMRs. The legacy forklifts are fitted with a “digital backpack” of sensors and a gateway and registered, along with the rest of the autonomous equipment, so that they appear as active devices in the facility configuration. Their state is tracked in the Actor Management component on a continual basis.
Scenario 2 – There is a need to move materials in the facility (STEPS 1-11)
The MES or WMS system publishes a MoveMaterial request
The Orchestrator receives the request, initiates a material move workflow, and publishes a request to identify the appropriate piece of equipment to service it
Work Management receives the request, evaluates any associated conditions (e.g., location, work zone) and publishes a request to identify all equipment of the correct type (could be one or more), along with their present status, to perform the activity
Actor Management receives the request and publishes a request for a list of all registered equipment of the specified type(s)
Configuration Management receives the request, interrogates its data store and publishes the list of connected equipment back to the facility message bus
Actor Management receives the message and checks the list against the equipment presently represented in its model, creating new objects as required for missing items, and publishing the list of movement equipment along with their individual status back to the message bus
Work Management receives the list and, based on configured dispatching rules, publishes an ordered list of equipment to service the request
Orchestration receives the list and starts with the first piece of equipment provided in the list
Orchestration sends a standard MoveMaterial request to initiate action
The message is processed by the Façade for the appropriate piece of equipment and a result is provided in response to the request. If the work was directed at a forklift, a message is sent to the appropriate Operator via the connected worker environment to perform the activity
The Orchestrator checks for any error conditions. If the task assignment wasn’t completed or wasn’t taken up within a pre-defined OLA, it cancels that request, moves to the next piece of equipment in the list, and sends a new request, until the process is complete. If the task is completed successfully, the transactional performance data is recorded and material move workflow is completed
Wrapping Up
Hopefully, the above examples provide a reasonable understanding of the nature of the interactions across the core framework for orchestration and value of having a decoupled and abstracted approach to integration. Simply said: the orchestrator manages the SLAs and high value outcomes, but it isn’t concerned with the physical equipment used to support its workflows. That separation of concerns creates an incredible amount of flexibility and resiliency, particularly in the mixed environment that exists across many manufacturing organizations today.
What It Is: Simply said, orchestration is the means by which a process is managed across a set of entities in a connected ecosystem
Why It Matters: From a digital manufacturing standpoint, thinking of a facility as a connected ecosystem of digital elements creates a framework by which we can manage, coordinate, analyze, and optimize processes for the purposes of improving operating performance
The above diagram highlights the elements of the blueprint from the previous article on Digital Manufacturing (link below) that will be discussed below
Key Concepts
Fundamental to leveraging the blueprint is the concept oftreating a facility as a collection of digital entities that are part of a dynamic, integrated ecosystem
Because equipment can and likely will vary facility-to-facility (or even within a facility itself), there is a benefit to defining the architecture at a logical and abstract level, and then mapping to into individual physical elements present in the production environment. This allows for significant flexibility in the execution layer, while providing a common, reusable design that can be leveraged across facilities for the purposes of enabling analytics and optimization that otherwise would be much more expensive and complex to deliver at scale
For the purposes of illustrating the concept, I will describe the base assumptions related to different components at each layer of the blueprint, using material movement as an example
The example is not meant to be exhaustive, but rather to highlight some key assumptions to help highlight how the layers of the blueprint are meant to interact and interoperate at the macro-level. There are definitely more components involved at an implementation-level (e.g., choices of whether to use OPC UA or MQTT for IT/OT integration at a facility)
The intention is not to suggest that the model in this example would be implemented in a big bang approach, but rather through a sequence of incremental steps as will be outlined below
The basis for how the model is intended to operate is fundamentally rooted in Object-Oriented Analysis and Design (OOA/OOD), so some familiarity with those concepts may be helpful when reviewing the next set of assumptions
The diagram above represents the subset of components that are relevant for this more detailed illustration of how the blueprint is intended to work. I will break this down into three parts: how the model fits together overall, providing some clarity on the role of each of the components that are called out (using the numbers above as a guide), and finally how this could be approached from an incremental standpoint over time.
Overall Concepts
The blueprint assumes a base framework for organizing, tracking, and managing work across a set of digital components in a connected factory environment
The means for coordinating work is largely about orchestration, which assumes business rules and workflow that govern how processes in the facility work, and for which performance data would be collected for the purposes of performing analytics
The more than the infrastructure is extended to include additional processes, devices, and capabilities, the more optimization opportunities could be surfaced within and across facilities over time
Key Elements of the Model
MES and WMS – The base assumption is that most or all of the material movement requests will originate in one of these two applications
Movement Equipment – The assumption is the integration for the various types of material movement equipment will be done so that there is as much standard data exchanged as possible to facility cross-device analytics and process and performance optimization
End User Access – For the purposes of making a forklift “appear” relatively equivalent to its autonomous counterparts, the assumption is that the operator will both be provided work assignment through a mobile device and that the device itself will be digitally “visible” through a set of sensors that are added to provide location and other available telemetry data
Traffic Management and Location Services – It is assumed, given the near real-time nature of the devices, that location tracking and some level of traffic management will occur in the OT environment itself. There is assumed to be a sufficient level of secure and reliable wireless connectivity available at a facility to enable this capability
Configuration Management – At an overall level, from a modeling standpoint, the goal is to enable the framework by designing each of the individual components as an “actor” (an entity capable of interacting with the rest of the digital ecosystem) with a set of associated capabilities and operating characteristics that ultimately help to track and evaluate its function and performance within a given facility. This is the core area where the object-oriented analysis and design of various components of the digital facility environment would be defined and built out over time. Managing by configuration allows for an abstraction of the operating model from the physical equipment and actors at a given location
Actor Management – As individual components are identified and integrated into the digital facility environment, there needs to be a mechanism to identify and assign the logical entities of the design to physical assets, along with tracking basic information about their state (for example a specific type of actor would exist for each derived type of autonomous vehicle, but that would need to be actively mapped to each physical device that is in place, so there is a way to translate the logical to the physical, and track things like battery status, whether the actor is presently addressing a task, awaiting work, completed a task successfully, etc.)
Work Management – With various types of connected components identified and being managed, there needs to be a capability to establish rules for what kind of work should be served by which kinds of devices. Having a separate component that is aware of both the existing configuration and types of actors available creates a dynamic way to analyze, adjust, and optimize that distribution of work as needed without needing to change any of the integration in place
Orchestration – Having a configuration defined, a way to map logical entities to physical assets, and assign work to one or more components in a digitally connected ecosystem, the orchestration capability can provide a dynamic mechanism to manage material movement across connected actors, while tracking process and task performance
Process Optimization – This capability would specifically look at data collected via the above components and look for optimization opportunities that could be fed back into work management and orchestration
Facility Data & Analytics – This set of components is highlighted simply to note that data would be gathered at the edge in multiple formats to support local tracking and optimization, as well as model integration and execution
Simulation – With data being published to the enterprise from individual facilities, the simulation component would be tasked with modeling various scenarios to identify performance improvement or cost optimization opportunities that could be fed back to the facility level
Cross-Facility Optimization – Given the results of various simulation scenarios, a level of cross-facility optimization should be possible, whether that involves fleet composition, work assignment, or some other dimension surfaced through the simulation process
Enterprise Data & Analytics – Different than the facility data environment, the enterprise solutions would have a broader focus across facilities for model development and process improvement identification
Remote Monitoring – This capability is somewhat separate from those involving orchestration and optimization, but the point is that, once you have a standard for connecting and exposing telemetry and other data associated with digital components, a level of remote monitoring and support is possible that could provide efficiencies at scale
Phasing in Capabilities Over Time
As was stated in the overview above, the blueprint is meant to serve as a reference architecture to guide implementation efforts over time and promote long-term, sustainable value creation. As such, it can be implemented in an incremental fashion, as long as certain steps are taken along the way to promote interoperability and extensibility of the design
This may not be how the implementation flow works in practice, but provides a way to conceptualize one way to build out the model in parts that create incremental value over time
Step 1: Model the Framework and Endpoints: This is arguably one of the most difficult steps, because it requires a level of understanding in terms of the longer-term workings of the model overall. In this case, that means designing to expose and capture telemetry, route, and process performance data across a set of material movement devices
Step 2: Standardize Integration: Once the model is developed, integration should be standardized to allow abstraction of the various material movement devices so that, from a process standpoint, the means by which material movement is decoupled from the activity itself. This provides longer-term flexibility in changing the makeup of the fleet without having to redesign the infrastructure for how material movement is accomplished in a given facility (or for a specific product setup)
Step 3: Incrementally Implement and Gather Data: The assumption is that one type of device could be brought online at a time to test and prove out the infrastructure (including route, task completion, and process performance data), then incrementally add more devices types until all are digitally integrated and collected
Step 4: Expose to the Enterprise: Once the digital integration is accomplished within a facility (either at an individual or collective level depending on the business need), it can then be exposed to the enterprise to provide visibility on the behavior of the fleet at each location
Step 5: Add Remote Monitoring: Depending on the operating model, once the devices are digitally integrated, it should be possible to add a layer of remote monitoring to support ongoing maintenance and reliability activities across facilities
Step 6: Add Orchestration: With multiple types of connected devices, orchestration can be added to provide more of a dynamic capability for assigning directed work, whether that is to forklift operators or autonomous equipment
Step 7: Analyze and Optimize at a Facility-Level: Having gathered performance data and established a more dynamic means to assign and manage work, facility-level optimization can be done to improve material handling across all connected devices (individually and collectively)
Step 8: Integrate at the Enterprise-Level: With data gathered and analyzed across device types, it can be published to the enterprise data solutions to provide visibility into operating characteristics across individual facilities
Step 9: Analyze and Simulate at the Enterprise-Level: Given data gathered across multiple device types and locations, it becomes possible to run simulations to model different scenarios for fleet composition and the relative impact of changing the makeup of devices and assignments by facility
Step 10: Optimize Across Facilities: With the output of various simulation scenarios having been generated, a level of cross-facility optimization could be performed to further optimize enterprise-level operating performance
Wrapping Up
Hopefully, providing a more concrete example sheds more light on the power of managing a digital facility as a digitally connected ecosystem. The manufacturing environment itself is fundamentally layered and complex, so the elegance and layering of the solution, along with how complexity is insulated and abstracted is important in building out a resilient infrastructure that can operate and optimize across a variety of production settings that leverage highly varied pieces of equipment.
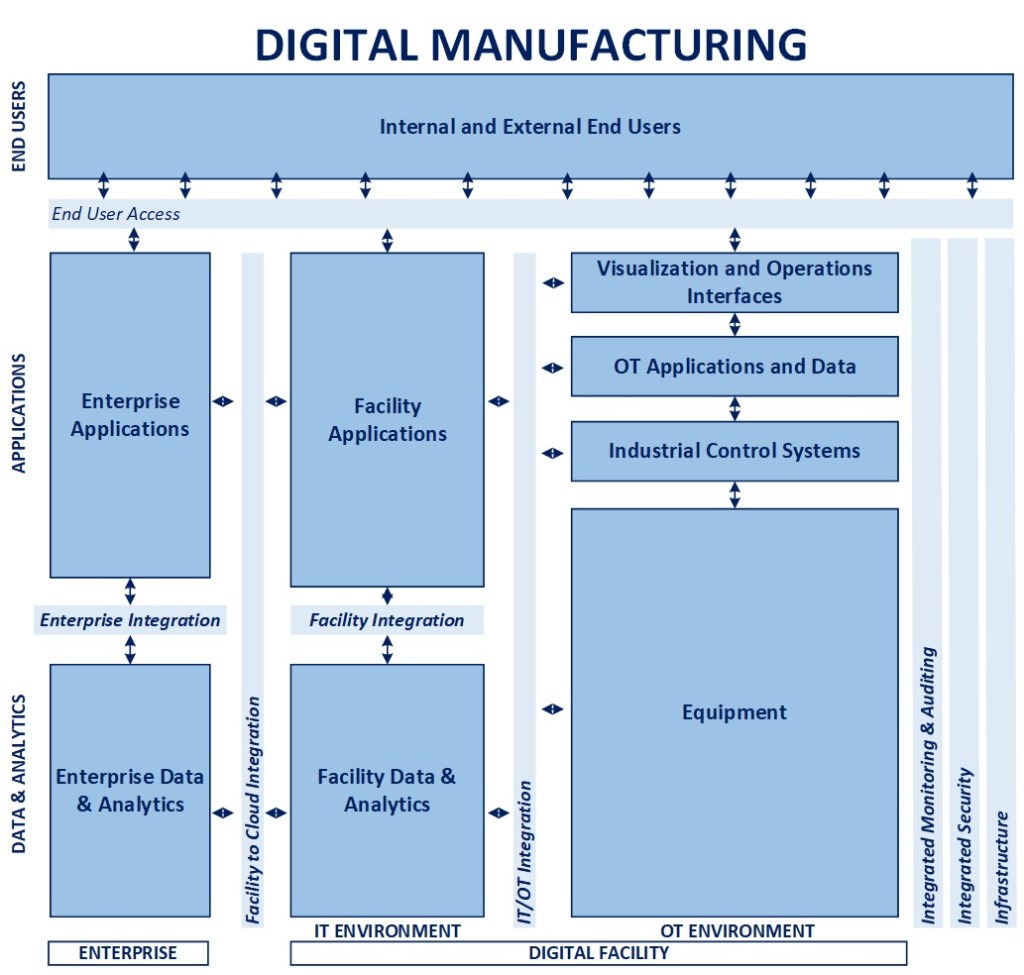
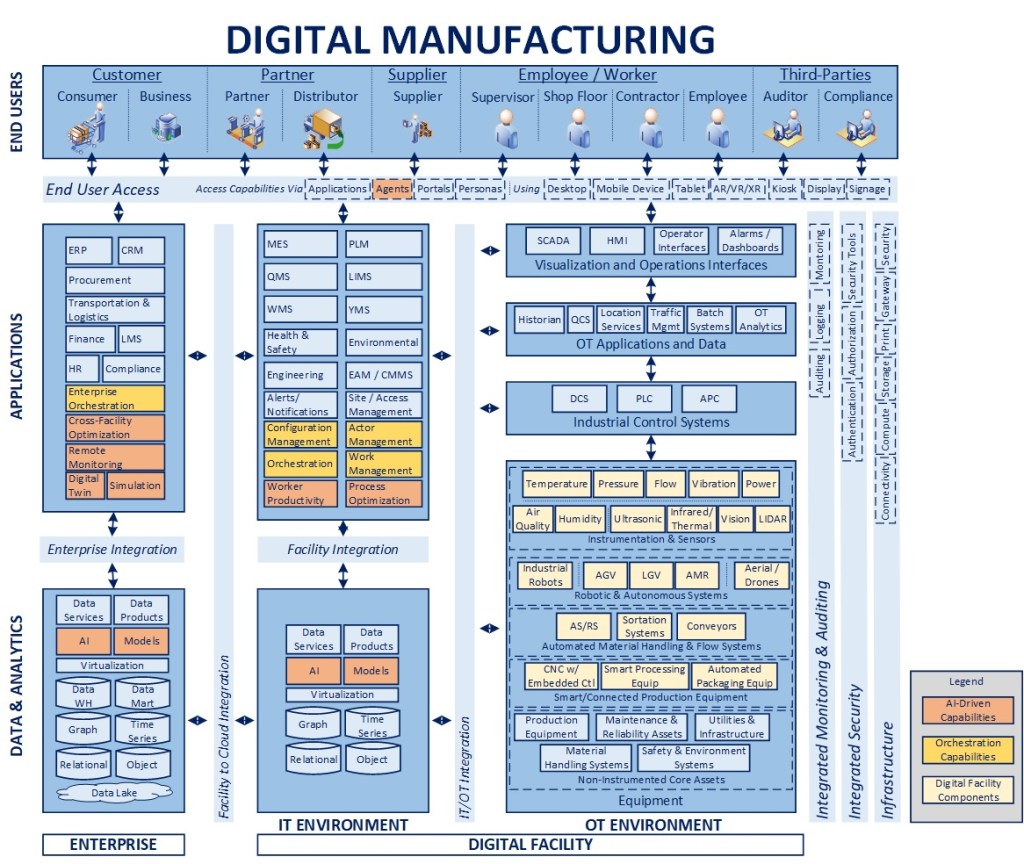
What It Is: This manufacturing blueprint is intended to serve as the overarching conceptual design for a future state digital factory environment. It is meant to help inform and guide design decisions, adjusting as new capabilities are available, and allow for incremental evolution over time that conforms to an overall, integrated design.
Why It Matters: Designing a future state manufacturing environment is a complex activity for multiple reasons, the layering of technical and non-technical components, the interaction of human and machine elements, layers of processes (some or all of which may not be standardized), safety and failure points in the production process, operating conditions and constraints, limitations of technology infrastructure at physical locations, and so on. Having a blueprint creates a “north star” concept that can inform individual implementation efforts in the interest of guiding investments, capturing the cumulative value of those efforts, and ultimately optimizing worker productivity, improving safety, reducing unplanned events, limiting waste, improving quality, and optimizing production over time in an intentional and disciplined way, driven by a combination of architecture and engineering.
Summary View – Concepts
Designing a connected ecosystem requires a broader view of the model itself, with a mindset geared towards reality, not an ivory tower that doesn’t and may never exist
That being said, the “building blocks” need to be identified so the future state model is architected and elements of the design can be leveraged in a way that components will “fit” and interoperate seamlessly, even if they are built through incremental efforts over time (if at all)
The above diagram is an evolution of the Purdue (ISA-95 Standard) model, meant to show the various connected groupings of elements that will comprise the future manufacturing environment, from the IT/OT environments within a facility to the enterprise elements and those that serve digital workers, customer, suppliers, and partners
The facility OT environment mimics Levels 0-2 of the Purdue model, with a separation of concerns between equipment (digital and non-digital), industrial control systems, the applications and data solutions, and ultimately the visibility layer that interact directly and provides visibility into that equipment. It is a foregone conclusion that for many manufacturers where more than one facility is in operation, the machinery and composition of this environment will vary, especially as the footprint increases
The facility IT environment represents the applications and data solutions, some connected, some standalone, that operate at a facility at a logical level (i.e., there may be cloud-based applications utilized, but that are facility-focused), running on edge computing resources. The separation of concerns between the application and data layers reflects the conceptual architecture I discuss further in my Intelligent Enterprise 2.0 article (linked below)
The enterprise level supports the applications and data solutions that provide capabilities that span facilities, serve broader needs (e.g., ERP, Finance, Procurement), and enabling computing capabilities that would not make economic sense at each facility (e.g., model development)
All of these environments are supported by a common set of infrastructure elements that are secured and enabled to provide integrated monitoring and auditing, along with standard integration methods, between the IT/OT environments, the facility and cloud, and these internal capabilities and end users who need to access and consume the services
The end user layer is meant to represent and include all the stakeholders, internal and external to the organization (including contractors at a facility, as an example) who need secure, role-based access to the technologies across all three layers of the environment
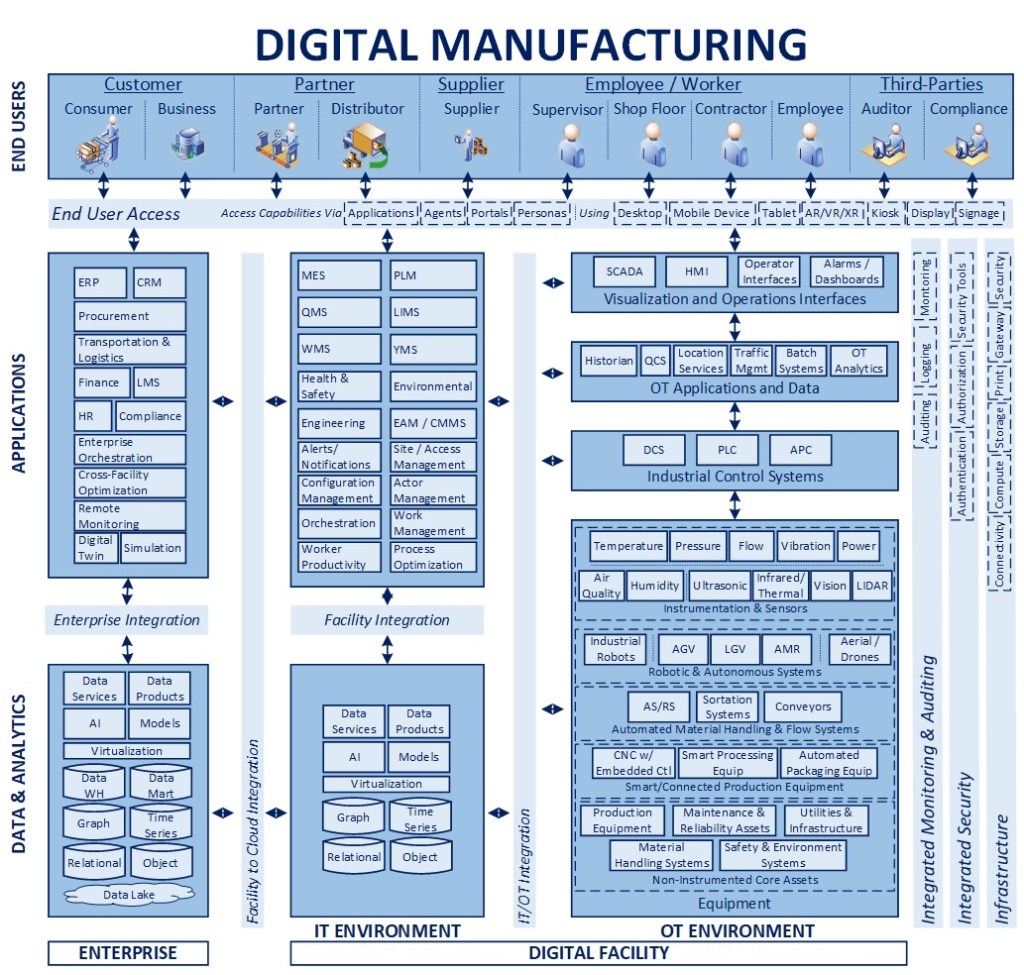
Blueprint View – Concepts
The next level of elaboration of the model above includes a representative set of solution components in each category of the larger model. Given the differences across types of manufacturing (discrete, process, etc.) and wide variety of equipment that can come into play, the first step of applying this concept in a “real world” situation would be to tailor and adjust it to the right components that can and would apply (present or future state) to a facility of set of facilities.
Facility – OT Environment
As was mentioned in the introduction above, the variability in equipment itself can be very significant, so there is a representative set included for the purpose of illustration, but it would need to be modified as appropriate to a specific organization
The primary concepts are the sub-groupings within the equipment category, from entire standalone, non-digital core assets to digitally enabled equipment, sensors, and robotics that can work in concert with those items
The supporting layers, from industrial controls, applications, and interfaces are largely consistent with the Purdue model, with additional elements for some more advanced capabilities that come into play as we evolve the broader model
The overall assumption with the OT environment remains that it is focused on execution of the manufacturing process, real-time data and decision-making that enables workers on the shop floor
Facility – IT Environment
The facility IT environment brings in the data solutions and applications that provide a means to analyze, manage, and orchestrate the underlying shop floor activities
Data solutions need to be able to manage multiple types of data, from time series data coming via sensors and equipment to graph-oriented representation of equipment hierarchies and video files from computer vision systems
The application layer has traditional applications for manufacturing execution (MES), warehouse management (WMS), and so on, but with some additional capabilities that I will highlight in the next section of the article
Again, not all applications identified in the “facility” layer may necessarily be running in the facility environment on edge computing resources, but logically, the assumption is that some or all of those identified are likely being utilized
Enterprise Environment
The enterprise environment can and will include more applications than those listed, but the ones listed as for the purposes of reflecting ones that have a connection into the manufacturing ecosystem in one way or another
The data solutions would process larger volumes of data, for purposes like model development (via a data lake), broader cross-facility analytics, simulation and so on
Part of the role of the enterprise applications would also provide a means to connect the activity and execution from any individual facility to its associated supply chain, other facilities, and so on
Supporting Layers
The Infrastructure layer, as represented, would provide connectivity and capabilities, from the individual facility to the enterprise, that provides a secure, reliable, and performant environment for other capabilities to be provided
The Security layer would provide capabilities to enable end user access control and identity management, vulnerability management, and zero trust to the appropriate level from the OT layer to the enterprise
The Intelligent Monitoring capability is aligned to my recent article on this topic (link below)
End User Access
The end user layer is elaborated to include a representative set of end consumers of technology capabilities, from the shop floor worker and supervisors to customers, partners, and suppliers
The assumption is that technology capabilities would be delivered through a defined set of mechanisms and devices for which standards can be developed to promote a consistent experience, regardless of delivery channel
From here, I’ll highlight some key components that are part of the evolution of the model itself.
Looking Forward – Concepts
The above diagram highlights three dimensions that are part of the evolutionary story of the digital facility, moving from the physical to the digital, from an “engineered” towards a more “architected” environment. I will write additional articles to elaborate the concept of the execution model and each of these areas in more detail, so this is meant to provide a summary of the core concepts only
Digital Equipment
The general premise is to evolve from a set of largely disconnected and non-instrumented core assets in a facility to a digital world of connected, intelligent assets that support and enable optimization and reliability
A large number of organizations have digital equipment today, and sensors of various types. The key aspect in the blueprint is how they are defined, modeled, and integrated into the larger ecosystem to enable other capabilities described below
Given reality is and always will be a blend of the new and the existing, I am planning to write a specific article on how I think about the blending of the two from an architecture standpoint in the interest of maximizing the value of assets across facilities in a heterogenous environment
Artificial Intelligence
While the term AI is thrown around more now than ever, understanding and identifying the touchpoints where it creates value in the manufacturing environment requires far more discipline and thought to obtain the most value for the investment
The core concept in relation to AI (beyond basic AI/ML capabilities) is that it plays five fundamental roles in the future manufacturing environment: optimizing performance of equipment (via asset health), optimizing performance of a facility (via process optimization), optimizing performance across a set of facilities and a broader application ecosystem involving manufacturing processes, optimizing product and facility investments (via digital twin and simulation capabilities), and optimizing digital worker safety, efficiency, and efficacy (via agents and orchestration capabilities)
Individual components related to the delivery of these capabilities are highlighted in the model above that will be explored in a future article on the future of distributed intelligence in manufacturing
Orchestration
The final component in a digital manufacturing future is the most critical, which is creating the capability to digitally orchestrate activity between human and machine elements, within and across facilities, in a way that is monitored, analyzed and optimized over time
There are various components identified on the diagram that will be part of a third future article on the overall model for execution and orchestration, but the key element is that there will be facility and enterprise elements to how the value is created over time, with the ability to scale these capabilities as new technologies and components are available within the broader, connected digital ecosystem
Wrapping Up
In drawing out the concepts associated with this blueprint, the overarching concept is that the future world of manufacturing needs to be more connected, insight-driven, and orchestrated in the interest of optimizing performance, safety, quality, and efficiency. I hope the concepts were thought provoking. Feedback is always welcome.
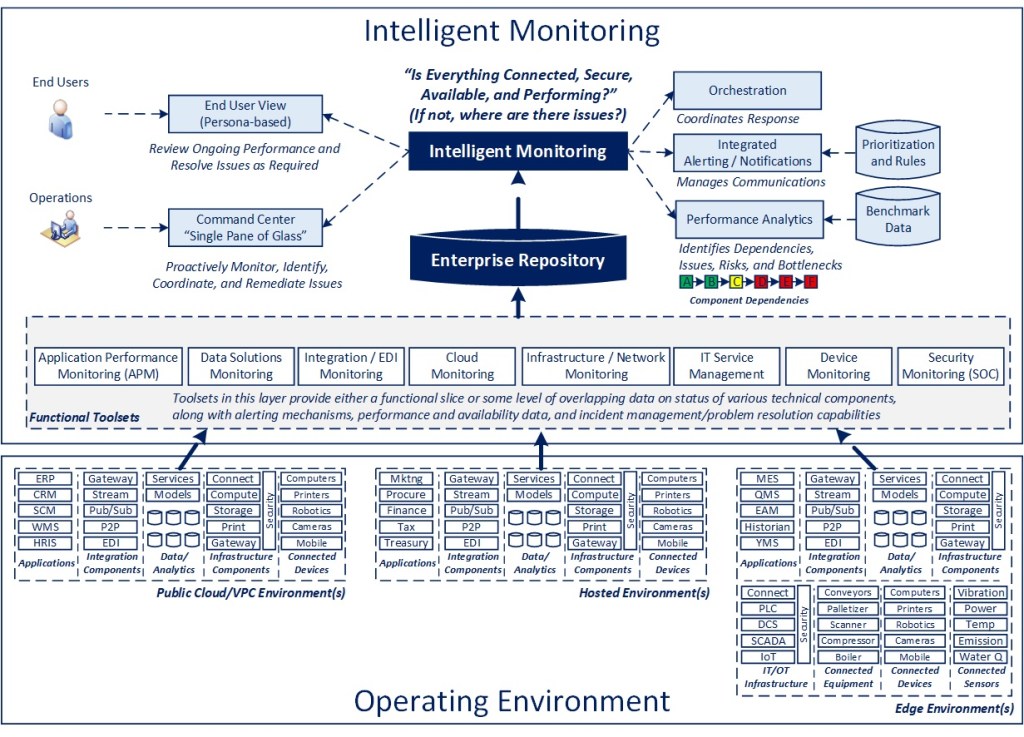
What It Is: There is an opportunity to rethink how we approach monitoring of operations, to better understand dependencies across components, proactively surface risks to avoid issues, and more effectively manage incidents when they occur
Why It Matters: The complexity of operations, particularly in Manufacturing, has increased substantially, both due to the introduction of digital capabilities and automation at facilities, as well as movement to a hybrid cloud environment. That complexity makes the effective identification of issues time consuming, which can cause significant and costly disruption to production and operating efficiency
Key Concepts
Define a conceptual framework for how your environment is organized first, along with what elements are important to monitor in an integrated fashion
Review existing toolsets in the market (cloud, APM, infrastructure monitoring) to determine whether they provide adequate capability to identify and manage issues effectively. If so, there may be no business reason to look any further
If the complexity of the environment is such that there are a considerable number of critical components involved, the tools available don’t provide sufficient capability, and the cost of extended outages or inadequate operating performance is material… THEN it may make sense to explore a more integrated and intelligent solution
It is important to note that this is not an either/or proposition. Even when pursuing a more elegant and integrated solution, for certain roles (e.g., security monitoring), existing tools likely should be leveraged in parallel with more advanced tools, so as not to need to replicate capabilities available across other tools that may be in place
The goal is to aggregate data from across existing monitoring platforms (or from source components themselves), run analytics to determine dependencies across operating components, and then apply that understanding to both monitor and triage issues more effectively at the time of an incident, as well as to handle the resolution process more effectively by having a streamlined process for notification and problem resolution
Once the infrastructure is established to perform the base capabilities described herein, additional components and data setscould be added over time to enrich the capability overall
Key Dimensions of the Solution
Enterprise Repository – Aggregated availability, connectivity, performance, and security data
Intelligent Monitoring – An AI-informed process that identifies risks and accelerates resolution
Performance Analytics –AI capability that identifies dependencies and evaluates benchmarks
Integrated Alerting / Notifications – Process to reduce duplication and manage communication
Orchestration – Workflow rules for incident management depending on the existing conditions
Command Center – A holistic view of operations across connected solution components
End-User View – A subset of enterprise data, specific to the end user relevant to their need/role
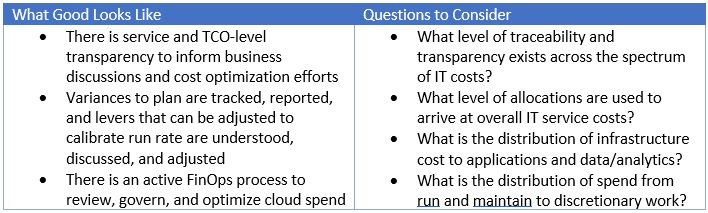
What It Is: Managing internally hosted infrastructure can be expensive and burdensome, which is one of the reasons that migrating workloads to the cloud has seen a significant surge over the last decade or so
Why It Matters: While the financial argument of shifting from “capex to opex” sounds favorable at first, a significant number of costs will be introduced when pivoting to a hybrid or cloud-native environment. A structured approach provides a more predictable outcome, while also unlocking new cloud capabilities
Key Concepts
Cloud strategy isn’t “one size fits all” – A thoughtful approach should be taken to evaluate where cloud migration creates value or competitive advantage versus going “all in”
It’s also never just a “Lift and Shift” – The minute workloads move outside an internally hosted environment, the technical complexity of a footprint and cyber risk materially increase and additional consideration needs to be given to the impact those changes will have to manage exposure
Plan to govern from Day One – Moving quickly in the case of the cloud can lead to immediate issues of orphaned assets and spiraling, unexpected costs. Having a migration plan is crucial
Establish roles and accountability – While the concept of enabling a broader set of delivery stakeholders to provision assets via a console is attractive and responsive at one level, it also introduces considerable risk of things being handled improperly. Thinking through the operating model, expectations of various roles in relation to things like provisioning, managing, and utilizing cloud-based assets is critical
Key Dimensions
Educate
With any cloud migration, it is important to have the necessary expertise and educate anyone involved in the provisioning and utilization of cloud-based assets to ensure they do so properly
Plan
Like any other component of an enterprise footprint, cloud strategy should be thoughtful and integrated with the overall technology strategy and not implemented on an ad-hoc basis
Financial planning should allow for contingency cost until a disciplined FinOps process is in place
Secure
Cloud migration introduces considerable complexity to vulnerability management, securing transactions and data, managing identities, etc. Additional tooling and monitoring capabilities will be needed for environments, as well as changes to DevSecOps processes across teams
Tag
An effective tagging strategy (ideally automated) is crucial to establish ownership, provide transparency into asset utilization, manage cost allocation, and maintain the footprint over time
Monitor
It is critical to establish a FinOps process for monitoring and managing spend to avoid waste
Cloud migration adds significant complexity to integrated monitoring across hosted, cloud, and edge-based computing environments. Incident management processes will need to be updated
Govern
Establish ownership for monitoring and governance of cloud-based assets to promote consistent use and standards across an organization, even if assets are provisioned in a federated manner
What It Is: Architecture provides the structure, standards, and framework for how technology strategy should be manifested and governed, including its alignment to business strategy, capabilities, and priorities. It should ideally be aligned at every level, from the enterprise to individual delivery projects
Why It Matters: Technology is a significant enabler and competitive differentiator in most organizations. Architecture provides a mental model and structure to ensure that technology delivery is aligned to overall strategies that create value. Having a lack of architecture discipline is like building a house without a blueprint… it will cost more to build, not be structurally sound, and expensive to maintain
Key Dimensions
Operating Model – How you organize around and enable the capability
Enable Innovation – How you allow for rapid experimentation and introduction of capabilities
Accelerating Outcomes – How you promote speed-to-market through structured delivery
Optimizing Value/Cost – How you manage complexity, minimize waste, and modernize
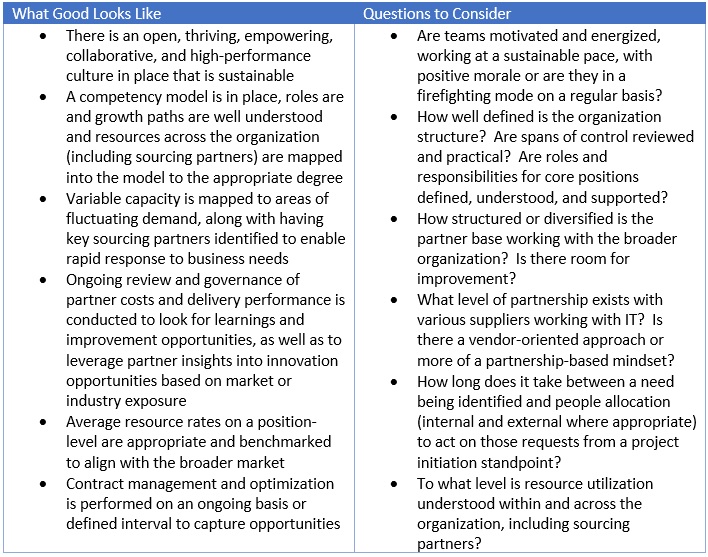
Inspiring Practitioners – How you identify skills, motivate, enable, and retain a diverse workforce
Performing in Production – How you promote ongoing reliability, performance, and security
Operating Model
Design the model to provide both enterprise oversight and integrated support with delivery
Ensure there is two-way collaboration, so delivery informs strategy and standards and vice versa
Foster a “healthy” tension between doing things “rapidly” and doing things “right”
Innovate
Identify and thoughtfully evaluate emerging technologies that can provide new capabilities that promote competitive advantage
Engage in experimentation to ensure new capabilities can be productionized and scaled
Accelerate
Develop standards, promote reuse, avoid silos, and reduce complexity to enable rapid delivery
Ensure governance processes promote engagement while not gating or limiting delivery efficacy
Optimize
Identify approaches to enable simplification and modernization to promote cost efficiency
Support benchmarking where appropriate to ensure cost and quality of service is competitive
Inspire
Inform talent strategy ensuring the right skills to support ongoing innovation and modernization
Provide growth paths to enable fair and thoughtful movement across roles in the organization
Perform
Integrate cyber security throughout delivery processes and ensure integrated monitoring for reliability and performance in production, across hosted and cloud-based environments
What It Is: Governance (in a delivery context) is the process for reviewing a portfolio of ongoing work in the interest of enabling risk management, containing avoidable cost, and increasing on-time delivery. PMOs (Project/Program Management Offices) are the mechanism through which governance is typically implemented in many organizations.Why It Matters: As the volume, risk, and complexity in a portfolio increase, there is typically a disproportionate increase in issues that come about, leading to cost overruns, missed expectations on scope or schedule (or both), and reduced productivity. PMOs, meant to be a mechanism to mitigate these issues, are often set up or executed poorly, becoming largely administrative and not value-generating capabilities, which furthers or amplifies any underlying execution issues. In an environment where organizations want to transform while managing a high level of value/cost efficiency, a disciplined and effective governance environment is critical to promoting IT excellence
Key Concepts
There are countless ways to set up an operating model in relation to PMOs and governance, but the culture and intent have to be right, or the rest of what follows will be more difficult
There is a significant difference between a “governing” and an “enabling” PMO in how people perceive the capability itself. While PMOs are meant to accomplish both ends, the priority is enabling successful, on-time, quality delivery, not establishing a “police state”
Where the focus of a PMO becomes “governance” that doesn’t drive engagement and risk management it can easily become an administrative entity that drives cost and doesn’t create value and ultimately undermines the credibility of the work as a whole
The structure of the overall operating model should align to the portfolio of work, scale of the organization, and alignment of customers to ongoing projects and programs
It can easily be the case that the execution of the governance model can adapt and change year-over-year but, if designed properly, the structure and infrastructure should be leverageable, regardless of those adjustments
The remainder of this article with introduce a concept for how to think about portfolio composition and then various dimensions to consider in creating an operating model for governance
Framing the Portfolio
In chalking out an approach to this article, I had to consider how to frame the problem in a way that could account for the different ways that IT portfolios are constructed. Certainly, the makeup of work in a small- to medium-size organization is vastly different than a global, diversified organization. It would also be different when there are a large number of “enterprise” projects versus a set of highly siloed, customer-specific efforts. To that end, I’m going to introduce a way of thinking about the types of projects that typically make up an IT project portfolio, then an example governance model, the dimensions of which will be discussed in the next section.
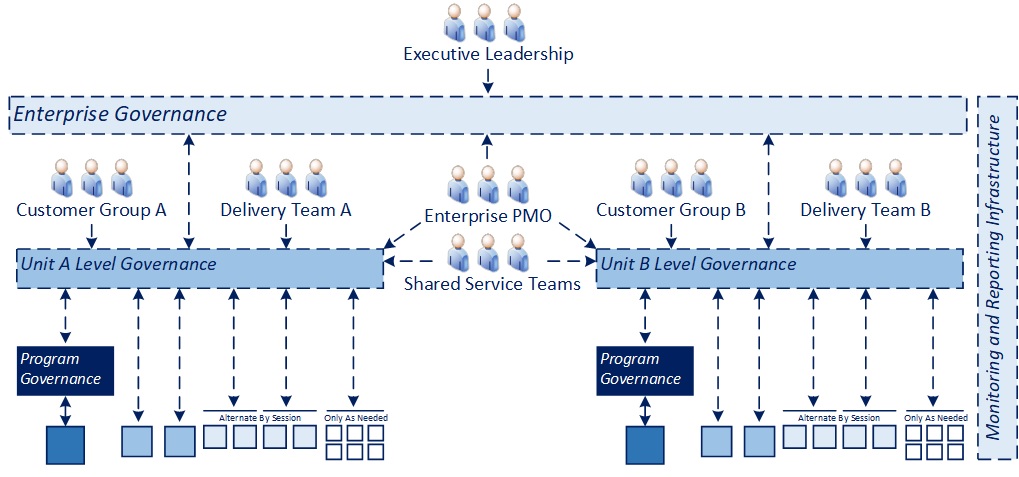
The above graphic provides a conceptual way to organize delivery efforts, using the rocks, pebbles, and sand in a jar metaphor that is relatively well known, and also happens to apply to organizing technology delivery.
To establish effective governance, you generally first want to examine and classify delivery projects/programs based on scale (in effort and budget), risk, timeframe, and so on. This is important so as not to apply a “one size fits all” approach to how you track and govern projects that encumbers lower complexity efforts with the same level of reporting that you would typically have on larger-scale, transformation programs.
In the model above, I went with a simple structure of four project types:
Sand – very low risk projects that can be something like a rate change in Insurance or data change in analytics
Pebbles – medium complexity work like incremental enhancements or an Agile sprint
Rocks – something material, like a package implementation, new technology introduction, product upgrade, or new business or technology capability delivery
Boulders – high complexity, multi-year transformation programs, like an ERP implementation where there are multiple material, related projects under one larger delivery umbrella
The characteristics of these projects and metrics you would ideally like to gather, along with the level of “review” needed on an ongoing basis would vary greatly, which will be explored in the next section.
In a real-world scenario, it is possible that you might want to identify additional sub-categories to the degree it helps inform architecture or delivery governance processes (e.g., security, compliance, modernization, AI-related projects), most of which would likely be specialized kinds of “Pebbles” and “Rocks” in the above model. It is very easy to become bloated quickly in terms of a governance process, so I am generally a proponent of tuning the model to the work and asking only questions relevant to the type of project being discussed.
What about Agile/SAFe and Product team-oriented environments? In my experience, it is beneficial to segment delivery efforts because, even in product-based environments, there are normally a mix of projects that are more monolithic in nature (i.e., that would align to “Rocks” and “Boulders”). Sprints within iterative projects (for a given product team) would likely align to “Pebbles” in the above model and the question would be how to align the outcome of retrospectives into the overall governance model, which will be addressed below.
So, coming back to the diagram, for the purposes of illustration, the assumption we will use is that the portfolio we’re supporting is a mix of all four project types (the “Portfolio Makeup” at right above), so that we can discuss how the governance can be layered and integrated across the different categories expressed in the model itself.
For the remainder of this article, we will assume the work in the delivery portfolio is divided equally between two business customer groups (A and B), with delivery teams supporting each as represented in the below diagram.
If your individual scenario involved a common customer, the model below could be simplified to one branch of the two represented. If there were multiple groups, it could be scaled horizontally (adding branches for each additional organization) or if there were multiple groups across various geographies, it could be scaled by replicating and sizing the entire structure by entity (e.g., work organized by country in a global organization or by operating company in a conglomerate with multiple OpCos) and then adding one additional later for enterprise or global governance.
Key Dimensions
There are many dimensions to consider in establishing an enterprise delivery governance model. The following breakdown is not intended to be exhaustive, but rather to highlight some key concepts that I believe are important to consider when designing the operating model for an IT organization.
General Design Principles
The goal is to enable decisions as close to the delivery as possible to improve efficiency and minimize the amount of “intervention” needed, unless it is a matter of securing additional resources (labor, funding, etc.) or addressing change control issues
The model should leverage a common operating infrastructure to the extent possible, to enable transparency and benchmarking across projects and portfolios. The more consistency and the more “plug and play” the infrastructure for monitoring and governance is, the faster (and more cost-effectively) projects and programs can typically be kicked off and accelerated into execution without having to define these processes independently
Metrics should move from summarized to more detailed as you move from oversight to execution, but the ability to “’drill down” should ideally be supported, so there is traceability
Business and IT PMOs versus “One” consolidated model
There is a proverbial question as to whether it is better to have “one”, integrated PMO construct, or an IT PMO separate from one that manages business dependencies (whether centralized or distributed)
From my perspective, this is a matter of scale and complexity. For smaller organizations, it may be efficient and practical to run everything through the same process, but as work scales, my inclination would be to separate concerns to keep the process from becoming too cumbersome and leverage the issue and risk management infrastructure to track and manage items relevant to the technology aspects of delivery. There should be linkage and coordination to the extent that parallel organizations exist, but I would generally operate them independently so they can focus on their scope of concerns and be as effective as possible
Portfolio Management Integration
I’m assuming that portfolio management processes would operate “upstream” of the governance process and inform which projects are being slotted, address overall resource management and utilization, and release strategy
To the extent that change control in the course of delivery affects a planned release, a reverse dependency exists from the governance process back to the portfolio management process to see if schedule changes necessitate any bumping or reprioritization because of resource contention or deployment issues
IT Operations Integration
The infrastructure used to track and monitor delivery should come via the IT Operations capability, theoretically connecting at the IT Scorecard for executive level delivery metrics to portfolio and project metrics tracked at the execution level
IT Operations should own (or minimally help establish) the standards for reporting across the entire operating model
Participation
IT Operations should facilitate centralized governance processes as represented in the “Unit-level” and “Enterprise” governance processes in the diagram above. Program-level governance for “Boulders” would likely be best run by the delivery leadership accountable for those efforts
Participation should include whoever is needed to engage and resolve 80% (anecdotally) of the issues and risks that could be raised, but be limited to only people who need to be there
Governance processes should never be a “visibility” or “me too” exercise, they are a risk management and issue resolution activity, meant to drive engagement and support for delivery. Notes and decisions can and should be distributed to a broader audience as appropriate so additional stakeholders are informed
In the context of a RACI model (Responsible, Accountable, Consulted, Informed), meetings should include only “R” and “A” parties, who can reach out to extended stakeholders as needed (“C”), but very rarely anyone who would be defined as an “I” only
It is very easy to either overload a meeting to the point it becomes ineffective or not include the right participants to the extent it doesn’t accomplish anything, so this is a critical consideration for making a governance model effective
Session Scope and Scheduling
I’ve already addressed participation, but scheduling should consider the pace and criticality of interventions. Said differently, a frequent, recurring process may make sense when there is a significant volume of work, but something more episodic if there are a limited number of major milestones over the course of time where it makes sense to review progress and check in at specific points in time
Where an ongoing process is intended, “Boulders” and “Rocks” should have a standing spot on the agenda given the criticality and risk profiles of those efforts likely would be high. For “Pebbles”, some form of rotational involvement might make sense, such as including two of the four projects in the example above in every other meeting, or prioritizing any projects that are showing a Yellow or Red overall project health. In the case of the “Sand”, those projects likely are so low risk that, beyond reporting some very basic operating metrics, they should only be included in a governance process when there is an issue that requires intervention or a schedule change that involves potential downstream impacts
Governance Processes
I mentioned this in concert with the example portfolio structure above, but it is important to consider tailoring the governance approach to the type of work so as not to create a cumbersome or bureaucratic environment for delivery teams where they focus on reporting and not managing and delivering their work
Compliance and security projects, as an example, are different than AI, modernization, or other types of efforts and should be reviewed with that in mind. To the extent a team is asked to provide a set of information as input to a governance process that doesn’t align cleanly to what they are doing, it becomes a distraction that creates no value. That being said, there should be some core indicators and metrics that are collected regardless of the project type and reviewed consistently (as will be discussed in the next dimension)
The process should be designed and managed by IT Operations so it can be leveraged across an organization. While individual nuances can be applied that are specific to a particular delivery organization, it is important to have consistency to enable enterprise-level benchmarking and avoid the potential biases that can come from teams defining their own standards that could limit transparency and hinder effective risk management
Delivery Health and Metrics
I’ve written separately on Health and Transparency, but minimally every project should maintain a Red, Yellow, Green on Overall Health, and a second-level indicator on Schedule, Scope, Cost, Quality, and Resourcing that a project/program manager could supply very easily on an ongoing basis. That data should be collected at a defined interval to enable monitoring and inform governance processes on an ongoing basis, regardless of other quantitative metrics gather
Metrics on financials, resourcing, quality, issues, risks, and schedule can vary, but to the extent they can be drawn automatically from defined system(s) of record (e.g., MS Project, financial systems, a time tracking system with defined project coding, defect or incident management tools), the level of manual intervention required to enable governance should ideally be limited to data teams should be utilizing on an ongoing basis
In the event that there are multiple systems in place to track ongoing work, the IT Operations team should work with the delivery stakeholders to identify any enterprise-levels standards required to normalize them for reporting and governance purposes. To give a specific example, I encountered a situation once where there were five different defect management systems in place across a highly diversified IT organization. In that case, the team developed a standard definition of how defects would be tracked and reported and the individual systems of record were mapped to that definition so that reporting was consistent across the organization
Change Control
Change is a critical area to monitor in any governance process because of the potential impact it has to resource consumption (labor, financials), customer delivery commitments, and schedule conflicts with other initiatives
Ideally a governance process should have the right information available to understand the implications of change as and when it is being reviewed as well as the right stakeholders present to make decisions with that information having been provided
To the extent that schedule, financial, or resource considerations change, information would need to be sent back to the IT Portfolio Management process to remedy any potential issues or disruptions that have been caused through decisions made. This is consistently missed in my experience in large delivery portfolios
Issue and Risk Management
Leveraging a common issue and risk management infrastructure both promotes a consistent way to track and report on these things across delivery efforts, but also creates a repository of “learnings” that could be reviewed and harvested in the interest of evaluating the efficacy of different approaches taken for similar issues/risks and promoting delivery health over time
Dependency/Integrated Plan Management
There are two dimensions to consider when it comes to dependencies. First is whether they exist within a project/program or are a dependency from that effort to others in the portfolio or downstream of it. Second is whether the dependency is during the course of effort or connected to the delivery/deployment of the project
In my experience, teams are very good at covering project- or program-driven dependencies, but there can be major gaps in looking across delivery efforts to account for risks caused when things change. To that end, some level of dependency-related matrix should exist to identify and track dependencies across delivery efforts separate from a release calendar that focuses solely on deployment and “T-minus” milestones as projects near deployment
Once these dependencies are being tracked, changes that surface through the governance process can be escalated back to the IT Portfolio Management process and other delivery teams to understand and coordinate any adjustments required
This can include situations where there are sequential dependencies, as an example, where a schedule overrun requires additional resource commitment from a critical resource needed to kick off or participate in another delivery effort. Without a means to identify these dependencies, the downstream effort may be delayed or not have time to explore alternate resourcing options without having a ripple effect to that downstream delivery. This is part of the argument for leveraging named resource planning (versus exclusively FTE-/role-based) for critical resources when slotting during the portfolio management process
Partner/Vendor Management
The IT Operations function should ideally help ensure that partners leverage internal reporting mechanisms or minimally conform to reporting standards and plug into existing governance processes where appropriate to do so
In the case of “Rocks” and “Boulders” that are largely partner-driven they likely will have a standalone governance process that leverages whatever process the partner has in place, but the goal should be to integrate and leverage whatever enterprise tools and standards are in place so that work can be benchmarked across delivery partners and also to compare the service delivery to internally-led efforts as well
It is very tempting to treat sourced work differently than projects delivered internal to IT, but who delivers a project should be secondary to whether the project is delivered on time, with quality and meets its objectives. The standards of excellence should apply regardless of who does the work
Learnings and Best Practices
Part of the potential benefit for having a shared infrastructure for executing governance discussions by comparison with distributing the work is that it enables you to see patterns in delivery, consistent bottlenecks, risks, and delays, and to leverage those learnings over time to improve delivery quality and predictability
Part of the governance process itself can also include having teams provide a post-mortem on their delivery efforts upon completion (successful or otherwise) so that other teams that participate in the governance process and the broader governance team can leverage those insights as appropriate
Change Management
While change management isn’t an explicit focus of a PMO/governance model, the dependency management surrounding deployment and learnings coming from various deployments should be coordinated with larger change management efforts and inform them on an ongoing basis in the interest of promoting more effective integration of new capabilities
Some Notes on Product Teams/Agile/SAFe Integration
It is tempting to treat product teams as isolated, independent, and discrete pieces of delivery. The issue with moving fully to that concept is that it becomes easy to lose transparency and benchmarking across delivery efforts that surface opportunities to more effectively manage risks and issues outside a given product/delivery team
To that end, part of the design process for the overall governance model should look at how to leverage and/or integrate the tooling for Agile projects with other enterprise project tracking tools as needed, along with integrating learnings from retrospectives with overall delivery improvement processes
Wrapping Up
Overall, there are many considerations that go into establishing an operating model for PMOs and delivery governance at end enterprise level. The most important takeaway is to be deliberate and intentional about what you put in place, keep it light, do everything you can to leverage data that is already available, and keep the balance between the project and the portfolio in mind at all times.The more project-centric you become, the more likely you will end up siloed and inefficient overall, and that will translate into missed dates, increased costs, and wasted utilization.
What It Is: An overall IT Strategy sets direction for an organization, providing a framework for the services IT provides, along with key dimensions and objectives, with flexibility to evolve over time
Why It Matters: With the ever-increasing demand for innovation in a competitive, but cost-conscious environment, a thoughtful strategy accelerates results, reduces cost and risk, and enables sustainability
Key Concepts
Technology strategy always needs to be rooted in a business-enabling approach
It is tempting to over-index on one dimension (e.g., cost management) and sacrifice capability
Excellence in IT is rooted in having business aligned objectives, with a disciplined approach
This model is organized around five key dimensions, which should be defined and prioritized
A simple IT scorecard could be created using how business partners evaluate each dimension
This article focuses on delivering IT objectives, IT Excellence focuses on “how to operate” in IT
Key Dimensions
Innovate – Promote Competitive Advantage
Map to business goals, establish a disciplined innovation process aligned to architecture strategy
What It Is: Excellence is core to creating sustainable value through technology in any organization
Why It Matters: Technology advances so rapidly that most organizations can’t keep up. The balance of agility and discipline, speed and quality are essential to optimizing the value of IT at the right cost
Key Dimensions
Courageous Leadership
Excellence requires tenacity, agility, flexibility, risk appetite, humility, and discipline
Given leadership sets the tone and direction for everything else, this is critical to get right
Need to be an advocate, champion, and business partner, knowing when to say “no” if needed
Transformative Culture
Remaining competitive in a continually evolving world requires a culture that enables change
Culture is expressed in what people see as much or more than anything they hear in speeches
Core values need to be consistently demonstrated from leaders to individual contributors
Relentless Innovation
Consider what happens in the technology strategy if core solutions are obsolete in 18-24 months
Make disciplined innovation part of the ongoing portfolio strategy to maintain competitive edge
Plan for “urban” renewal so there is minimal need for large scale, disruptive modernization
Operating with Agility
Establish strong business partnerships to respond to changes in portfolio composition/priorities
Create a minimally invasive, highly transparent operating infrastructure to drive efficiencies
Leverage workforce and sourcing strategy to provide the right capabilities at the right cost
Framework-Centric Design
Leverage enterprise architecture to establish a connected enterprise of intelligent ecosystems
Develop standards to enable ongoing integration of best-of-breed technology capabilities
Integrate artificial intelligence in thoughtful ways that scale and provide sustainable value
Delivering at Speed
Create a disciplined and repeatable environment for delivering solutions that can scale
Design with architecture, quality, and security in mind, not as an afterthought
Understand that total cost of ownership is as important as speed-to-market most of the time