Overview
Growing Up in Manufacturing
My father ran his own business when I was growing up. His business had two components: first, he manufactured pinion wire (steel or brass rods of various diameters with teeth from which gears are cut) and, second, as a producer of specialty gears that were used in various applications (e.g., the timing mechanism of an oil pump). It was something he used to raise and support a large Italian family and it was pretty much a one-man show, with help from his kids as needed, whether that was counting and quality testing gears with mating parts or cutting, packing, and shipping material to various customers across North America. He acquired and learned how to operate screw machines to produce pinion wire but eventually shifted to a distribution business, where he would buy finished material in quantity and then distribute to middle market customers at lower volumes at a markup.
His business was as low tech as you could get, with a little card file he maintained that had every order by customer written out on an index card, tracking the specific item/part, volume, and pricing so he had a way to understand history as new requests for quotes and orders came in and also understand purchase patterns over time. It was largely a relationship business, and he took his customer commitments to heart at a level that dinner conversation could easily deflect into a worry about a disruption in his supply chain (e.g., something not making it to the electroplater on time) and whether he might miss his promised delivery date. Integrity and accountability were things that mattered and it was very clear his customers knew it. He had a note pad on which he’d jot things down to keep some subset of information on customer / prospect follow ups, active orders, pending quotes, and so on, but to say there was a system outside what he kept in his head would be unfair to his mental capacity, which was substantial.
It was a highly manual business and, as a person who taught myself how to write software in the third grade, I was always curious what he could do to make things a little easier, more structured, and less manual, even though that was an inescapable part of running his business on the whole. That isn’t to say he had that issue or concern, given he’d developed a system and way of operating over many years, knew exactly how it worked, and was entirely comfortable with it. There was also a small point of my father being relatively stubborn, but that didn’t necessarily deter me from suggesting things could be improved. I do like a challenge, after all…
As it happened, when I was in high school, we got our first home computer (somewhere in the mid-1980s) and, despite its relatively limited capacity, I thought it would be a good idea to figure out a way to make something about running his business a little easier with technology. To that end, I wrote a piece of software that would take all of his order management off of the paper index cards and put it into an application. The ability to look up customer history, enter new orders, look at pricing differences across customers, etc. were all things I figured would make life a lot easier, not mention reducing the need to maintain this overstuffed card file that seemed highly inefficient to me.
By this point, I suspect it’s clear to the reader what happened… which is that, while my father appreciated the good intentions and concept, there was no interest in changing the way he’d been doing business for decades in favor of using technology he found a lot more confusing and intimidating than what he already knew (and that worked to his level of satisfaction). I ended up relatively disappointed, but learned a valuable lesson, which is that, the first challenge in transformation is changing mindsets… without that, the best vision in the world will fail, no matter what value it may create.
It Starts with Mindset
I wanted to start this article with the above story because, despite nearly forty years having passed since I tried to introduce a little bit of automation to my father’s business, manufacturing in today’s environment can be just as antiquated and resistant to change as it was then, seeing technology as an afterthought, a bolt on, or cost of doing business rather than the means to unlock the potential that exists to transform a digital business in even the most “low tech” of operating environments.
While there is an inevitable and essential dependence on people, equipment, and processes, my belief is that we have a long way to go on understanding the critical role technology plays in unlocking the potential of all of those things to optimize capacity, improve quality, ensure safety, and increase performance in a production setting.
The Criticality of Discipline
Having spent a number of years understanding various approaches to digital manufacturing, one point that I wanted to raise prior to going into more of the particulars is the importance of operating with a holistic vision and striking the balance between agility and long-term value creation. As I addressed in my article Fast and Cheap Isn’t Good, too much speed without quality can lead to complexity, uncontrolled and inflated TCO, and an inability to integrate and scale digital capabilities over time. Wanting something “right now” isn’t an excuse not to do things the right way and eventually there is a price to pay for tactical thinking when solutions don’t scale or produce more than incremental gains.
This is also related to “Framework-Driven Design” that I talk about in my article on Excellence by Design. It is rarely the case that there is an opportunity to start from scratch in modernizing a manufacturing facility, but I do believe there is substantial value in making sure that investments are guided by an overall operating concept, technology strategy, and evolving standards that will, over time, transform the manufacturing environment as a whole and unlock a level of value that isn’t possible where incremental gains are always the goal. Sustainable change takes time.
The remainder of this article will focus on a set of areas that I believe form the core of the future digital manufacturing environment. Given this is a substantial topic, I will focus on the breadth of the subject versus going too deep into any one area. Those can be follow-up articles as appropriate over time.
Leveraging Data Effectively
The Criticality of Standards
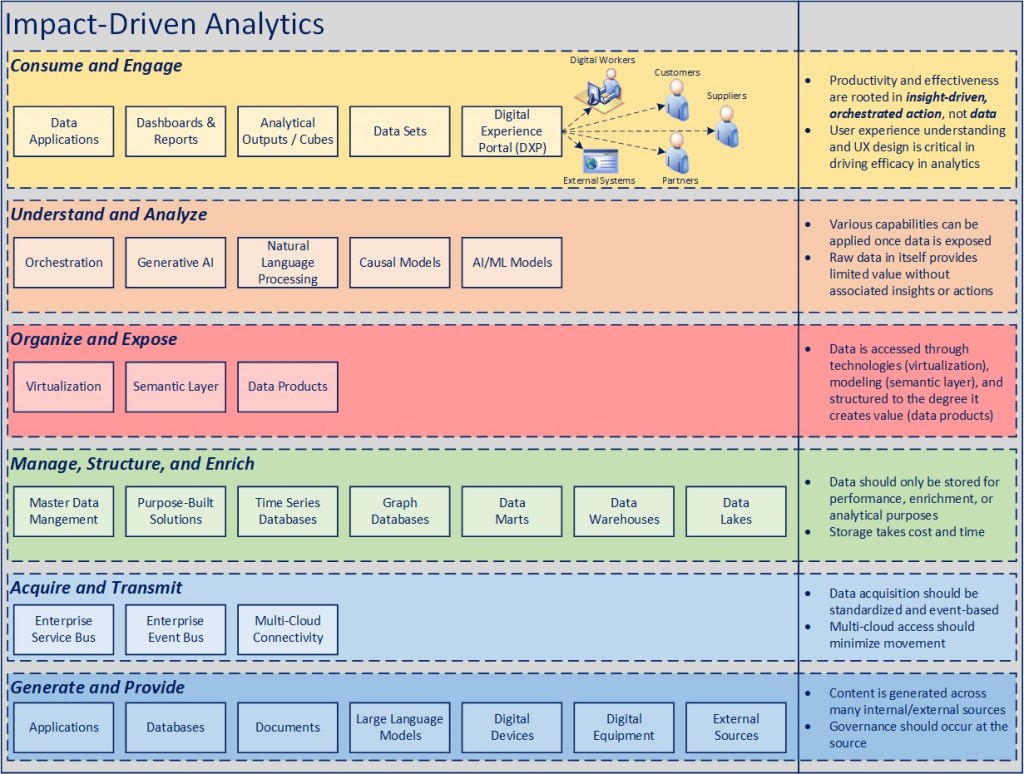
It is a foregone conclusion that you can’t optimize what you can’t track, measure, and analyze in real-time. To that end, starting with data and standards is critical in transforming to a digital manufacturing environment. Without standards, the ability to benchmark, correlate, and analyze performance will be severely compromised. This can be a basic as how a camera system, autonomous vehicle, drone, conveyor, or digital sensor is integrated within a facility, to the representation of equipment hierarchies, or how operator roles and processes are tracked across a set of similar facilities. Where standards for these things don’t exist, value will be constrained to a set of individual point solutions, use cases, and one-off successes. Where standards are, however, implemented and scaled over time, the value opportunity will eventually cross over into exponential gains that aren’t otherwise possible, because the technical debt associated with retrofitting and mapping across various standards in place will create a significant maintenance effort that limits focus on true innovation and optimization. This isn’t to suggest that there is a one-size-fits-all way to thinking about standards and that every solution needs to conform for the sake of an ivory tower ideal. The point is that it’s worth slowing down the pace of “progress” at times to understand the value in designing solutions for longer-term value creation.
The Role of Data Governance
It’s impossible to discuss the criticality of standards without also highlighting the need for active, ongoing data governance, both to ensure standards are followed, that data quality at the local and enterprise level is given priority (especially to the degree that analytical insights and AI become core to informed decision making), and also to help identify and surface additional areas of opportunity where standards may be needed to create further insights and value across the operating environment. The upshot of this is that there need to be established roles and accountability for data stewards at the facility and enterprise level if there is an aspiration to drive excellence in manufacturing, no matter what the present level of automation is across facilities.
Modeling Distributed Operations
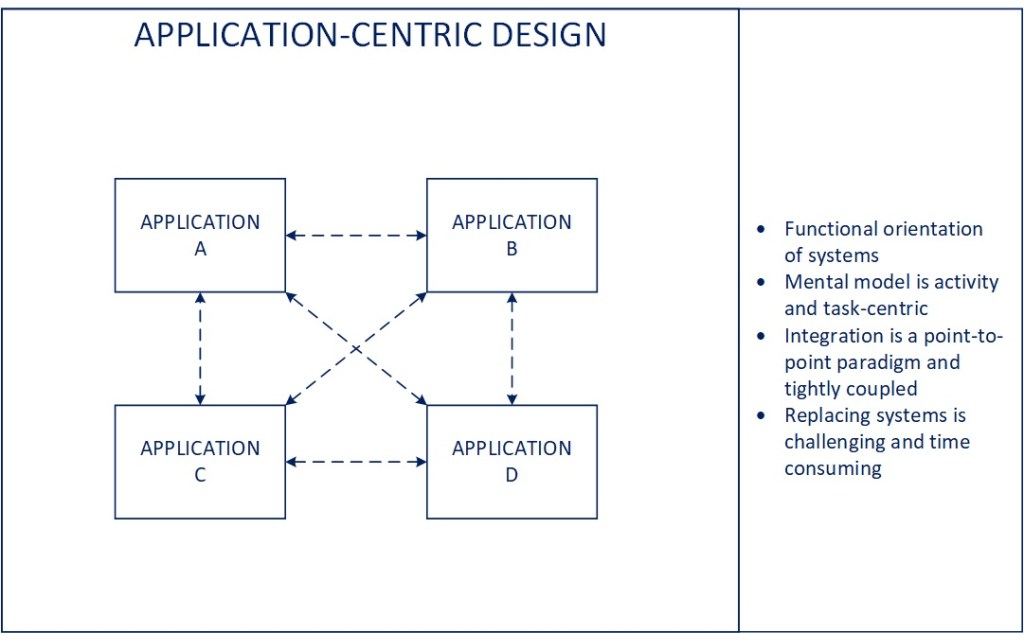
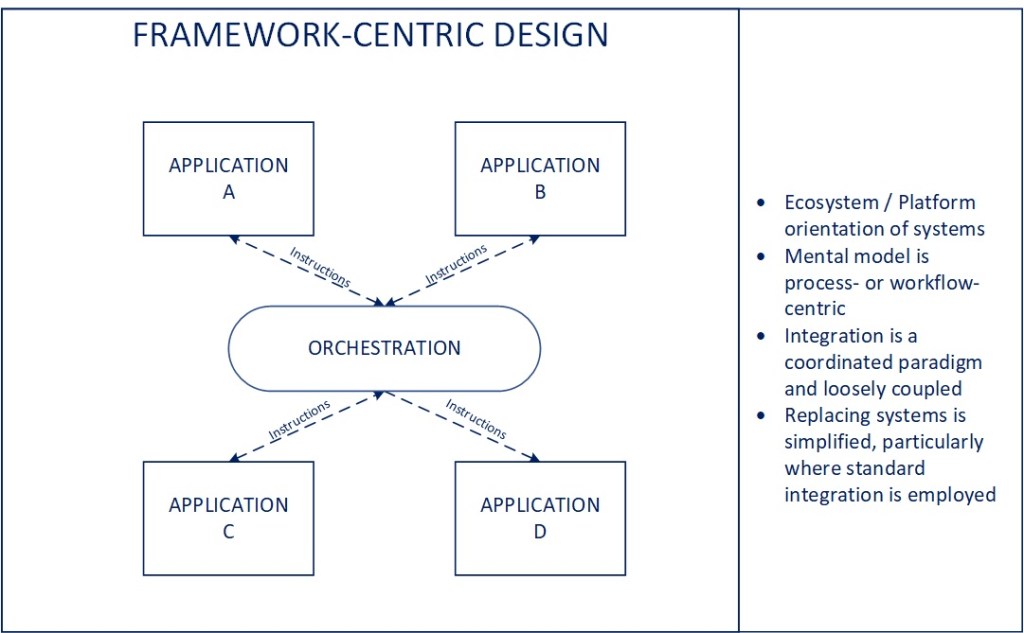
Applying Distributed Computing
There is a power in distributed computing that enables you to scale execution at a rate that is beyond the capacity you can achieve with a single machine (or processor). The model requires an overall coordinator of activity to distribute work and monitor execution and then the individual processors to churn out calculations as rapidly as they are able. As you increase processors, you increase capacity, so long as the orchestrator can continue to manage and coordinate the parallel activity effectively.
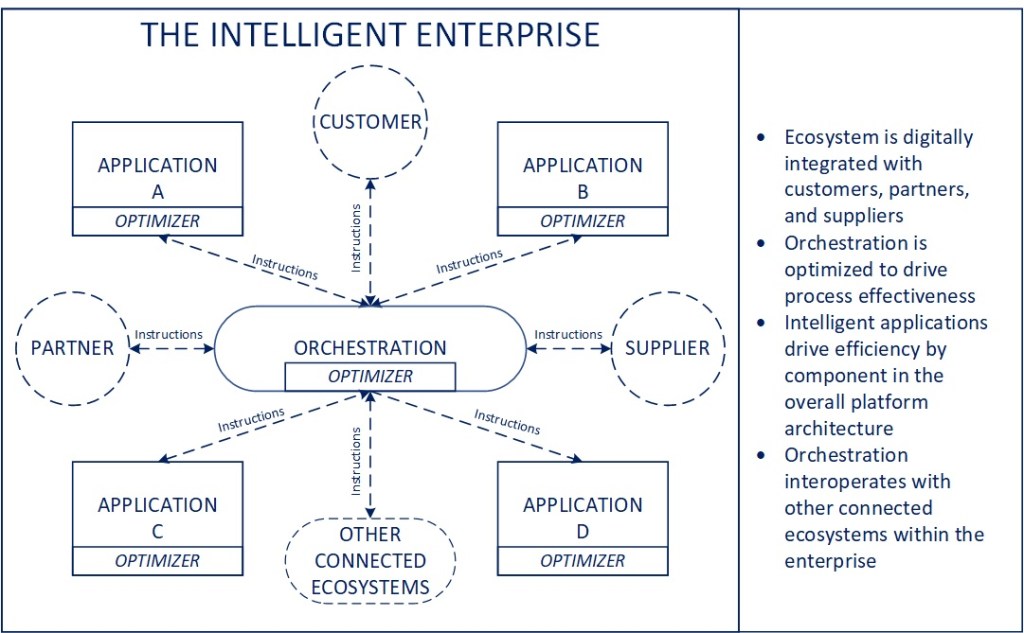
From a manufacturing standpoint, the concept applies well across a set of distributed facilities, where the overall goal is to optimize the performance and utilization of available capacity given varying demand signals, individual operating characteristics of each facility, cost considerations, preventative maintenance windows, etc. It’s a system that can be measured, analyzed, and optimized, with data gathered and measured locally, a subset of which is used to inform and guide the macro-level process.
Striking the Balance
While I will dive into this a little further towards the tail end of this article, the overall premise from an operating standpoint is to have a model that optimizes the coordination of activity between individual operating units (facilities) that are running as autonomously as possible at peak efficiency, while distributing work across them in a way that maximizes production, availability, cost, or whatever other business parameters are most critical.
The key point being that the technology infrastructure for distributing and enabling production across and within facilities should ideally be a matter of business parameters that can be input and adjusted at the macro-level and the entire system of facilities be adjusted in real-time in a seamless, integrated way. Conversely, the system should be a closed loop where a disruption at the facility level can inform a change across the overall ecosystem such that workloads are redistributed (if possible) to minimize the impact on overall production. This could be manifest in one or more micro-level events (e.g., a higher than expected occurrence of unplanned outages) that informs production scheduling and distribution of orders to a major event (e.g., a fire or substantial facility outage) that redirects work across other facilities to minimize end customer impact. Arguably there are elements that exist within ERP systems that can account for some of this today, but the level and degree of customization required to make it a robust and inclusive process would be substantial, given much of the data required to inform the model exists outside the ERP ecosystem itself, in equipment, devices, processes, and execution within individual facilities themselves.
Thinking about Mergers, Acquisitions, and Divestitures
As I mentioned in the previous section on data, establishing standards is critical to enabling a distributed paradigm for operations, the benefit of which is also the speed at which an acquisition could be leveraged effectively in concert with an existing set of facilities. This assumes there is an ability to translate and integrate systems rapidly to make the new facility function as a logical extension of what is already in place, but ultimately a number of those technology-related challenges would have to be worked through in the interest of optimizing individual facility performance regardless. The alternative to having this macro-level dynamic ecosystem functioning would likely be excess cost, inefficiency, and wasted production capacity.
Advancing the Digital Facility
The Role of the Digital Facility
At a time when data and analytics can inform meaningful action in real-time, the starting point for optimizing performance is the individual “processor”, which is a digital facility. While the historical mental model would focus on IT and OT systems and integrating them in a secure way, the emergence of digital equipment, sensors, devices, and connected workers has led to more complex infrastructure and an exponential amount of available data that needs to be thoughtfully integrated to maximize the value it can contribute over time. With this increased reliance on technology, likely some of which runs locally and some in the cloud, the reliability of wired and wireless connectivity has also become a critical imperative of operating and competing as a digital manufacturer.
Thinking About Auto Maintenance
Drawing on a consumer example, I brought my car in for maintenance recently. The first thing the dealer did was plug in and download a set of diagnostic information that was gathered over the course of my road trips over the last year and a half. The data was collected passively, provided the technicians with input on how various engine components were performing, and also some insight on settings that I could adjust given my driving habits that would enable the car to perform better (e.g., be more fuel efficient). These diagnostics and safety systems are part of having a modern car and we take them for granted.
Turning back to a manufacturing facility, a similar mental model should apply for managing data at a local and enterprise level, which is that there should be a passive flow of data to a central repository that is mapped to processes, equipment, and operators in a way that enables ongoing analytics to help troubleshoot problems, identify optimization and maintenance opportunities, and look across facilities for efficiencies that could be leveraged at broader scale.
Building Smarter Equipment
Taking things a step further… what if I were to attach a sensor under the hood of my car, take the data, build a model, and try to make driving decisions using that model and my existing dashboard as input? The concept seems a little ridiculous given the systems already in place within a car to help make the driving experience safe and efficient. That being said, in a manufacturing facility with legacy equipment, that intelligence isn’t always built in, and the role of analytics can become an informed guessing game of how a piece of equipment is functioning without the benefit of the knowledge of the people who built the equipment to begin with.
Ultimately, the goal should be for the intelligence to be embedded within the equipment itself, to enable a level of self-healing or alerting, and then within control systems to look at operating conditions across a connected ecosystem to determine appropriate interventions as they occur, whether that be a minor adjustment to operating parameters or a level of preventative maintenance.
The Role of Edge Computing and Facility Data
The desire to optimize performance and safety at the individual facility level means that decisions need to be informed and actions taken in near real-time as much as possible. This premise then suggests that facility data management and edge computing will continue to increase in criticality as more advanced uses of AI become part of everyday integrated work processes and facility operations.
Enabling Operators with Intelligence
The Knowledge Challenge
With the general labor shortage in the market and retirement of experienced, skilled laborers, managing knowledge and accelerating productivity is a major issue to be addressed in manufacturing facilities. There are a number of challenges associated with this situation, not the least of which can be safety related depending on the nature of the manufacturing environment itself. Beyond that, the longer it takes to make an operator productive in relation to their average tenure (something that statistics would suggest is continually shrinking over time), the effectiveness of the average worker can become a limiting factor in the operating performance of a facility overall.
Understanding Operator Overload
One way that things have gotten worse is the proliferation of systems that comes with “modernizing” the manufacturing environment itself. When confronted with the ever-expanding set of control, IT, ERP, and analytical systems, all of which can be sending alerts and requesting action (to varying degrees of criticality) on a relatively continuous basis, the pressure being created on individual operators and supervisors in a facility has increased substantially (with the availability of exponential amounts of data itself). This is further complicated in situations where an individual “wears multiple hats” in terms of fulfilling multiple roles/personas within a given facility and arbitrating which actions to take against that increased number of demands can be considerably more complex.
Why Digital Experience Matters
While the number of applications that are part of an operating environment may not be something that is easy to reduce or simplify without significant investment (and time to make change happen), it is possible to look at things like digital experience platforms (DXPs) as a means to manage multiple applications into a single, integrated experience, inclusive of AR/VR/XR technologies as appropriate. Organizing around an individual operator’s responsibilities can help reduce confusion, eliminate duplicated data entry, improve data quality, and ultimately improve productivity, safety, and effectiveness by extension.
The Role of the Intelligent Agent
With a foundation in place to organize and present relevant information and actions to an operator on a real-time basis, the next level of opportunity comes with the integration of intelligent agents (AI-enabled tools) into a digital worker platform to inform meaningful and guided actions that will ultimate create the most production and safety impact on an ongoing basis. Again, there is a significant dependency on edge computing, wireless infrastructure, facility data, mobile devices, a delivery mechanism (the DXP mentioned above), and a sound underlying technology strategy to enable this at scale, but it is ultimately where AI tools can have a major impact in manufacturing moving forward.
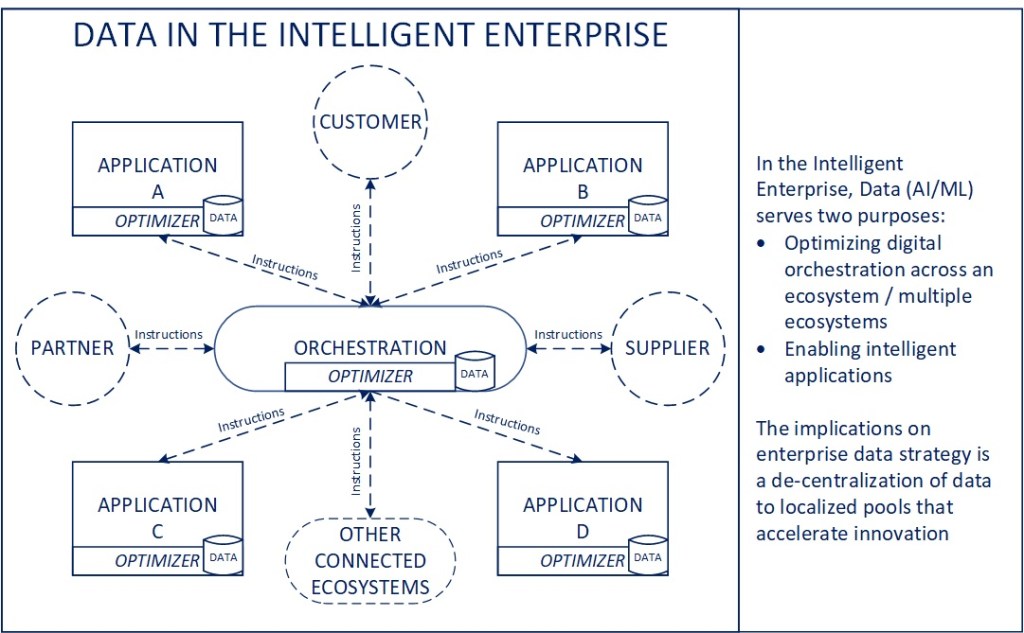
Optimizing Performance through Orchestration
Why Orchestration Matters
Orchestration itself isn’t a new concept in manufacturing from my perspective, as the legacy versions of it are likely inherent in control and MES systems themselves. The challenge occurs when you want to scale that concept out to include digital equipment, digital workers, digital devices, control systems, and connected applications into one, seamless, integrated end-to-end process. Orchestration provides the means to establish configurable and dynamic workflow and associated rules into how you operate and optimize performance within and across facilities in a digital enterprise.
While this is definitely a capability that would need to be developed and extended over time, the concept is to think of the manufacturing ecosystem as a seamless collaboration of operators and equipment to ultimately drive efficient and safe production of finished goods. Having established the infrastructure to coordinate and track activity, the process performance can be automatically recorded and analyzed to inform continuous improvement on an ongoing basis.
Orchestrating within the Facility
The number of uses of orchestration within a facility can be as simple as coordinating and optimizing material movement between autonomous vehicles and fork lifts within a facility, to computer vision applications for safety and quality management. With the increasing number of connected solutions within a facility, having the means to integrate and coordinate activity between and across them offers a significant opportunity in digital manufacturing moving forward.
Orchestrating across the Enterprise
Scaling back out to the enterprise level, looking across facilities, there are opportunities to look at things like procurement of MRO supplies and optimizing inventory levels, managing and optimizing production planning across similar facilities, benchmarking and analyzing process performance and looking for improvements that can be applied across facilities in a way that will create substantially greater impact than is possible if the focus is limited to the individual facility alone. Given that certain enterprise systems like ERPs tend to operate at largely a global versus local level, having infrastructure in place to coordinate activity across both can create visibility to improvement opportunities and thereby substantial value over time.
Coordinated Execution
Finally, to coordinate between the local and global levels of execution, a thoughtful approach to managing data and the associated analytics needs to be taken. As was mentioned in the opening, the overall operating model is meant to leverage a configurable, distributed paradigm, so the data that is shared and analyzed within and across layers is important to calibrate as part of the evolving operating and technology strategy.
Wrapping Up
There is a considerable amount of complexity associated with moving between a legacy, process and equipment-oriented mindset to one that is digitally enabled and based on insight-driven, orchestrated action. That being said, the good news is that the value that can be unlocked with a thoughtful digital strategy is substantial given we’re still on the front-end of the evolution overall.
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
-CJG 02/12/2024