No one builds applications or uses new technology with the intention of making things worse… and yet we have and still do at times.
Why does this occur, time and again, with technology? The latest thing was supposed to “disrupt” or “transform” everything. I read something that suggested this was it. The thing we needed to do, that a large percentage of companies were planning, that was going to represent $Y billions of spending two years from now, generating disproportionate efficiency, profitability, and so on. Two years later (if that), there was something else being discussed, a considerable number of “learnings” from the previous exercise, but the focus was no longer the same… whether that was windows applications and client/server computing, the internet, enterprise middleware, CRM, Big Data, data lakes, SaaS, PaaS, microservices, mobile applications, converged infrastructure, public cloud… the list is quite long and I’m not sure that productivity and the value/cost equation for technology investments is any better in many cases.
The belief that technology can have such a major impact and the degree of continual change involved have always made the work challenging, inspiring, and fun. That being said, the tendency to rush into the next advance without forming a thoughtful strategy or being deliberate about execution can be perilous in what it often leaves behind, which is generally frustration for the end users/consumers of those solutions and more unrealized benefits and technical debt for an organization. We have to do better with AI, bringing intelligence into the way we work, not treating it as something separate entirely. That’s when we will realize the full potential of the capabilities these technologies provide. In the case of an application portfolio, this is about our evolution to a suite of intelligent applications that fit into the connected ecosystem framework I described earlier in the series.
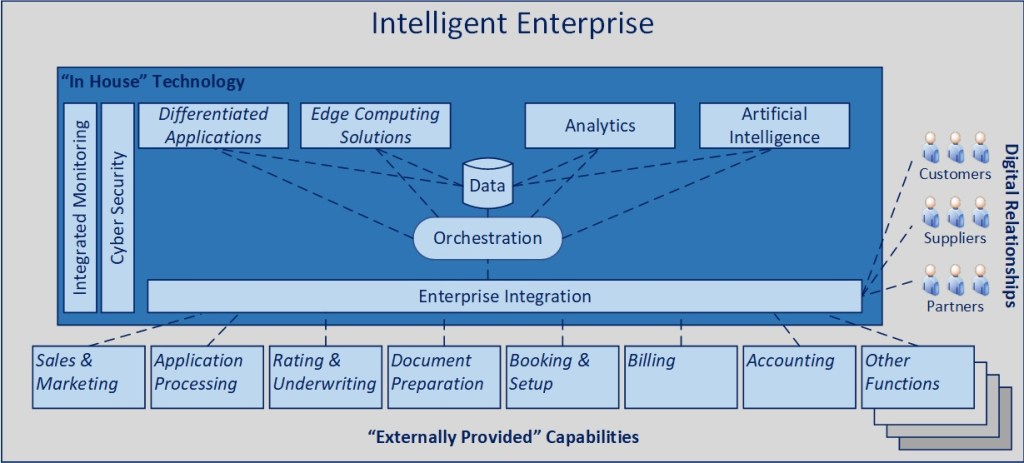
This is the fourth post in a series focused on where I believe technology is heading, with an eye towards a more harmonious integration and synthesis of applications, AI, and data… what I previously referred to in March of 2022 as “The Intelligent Enterprise”. The sooner we begin to operate off a unified view of how to align, integrate, and leverage these oftentimes disjointed capabilities today, the faster an organization will leapfrog others in their ability to drive sustainable productivity, profitability, and competitive advantage.
Design Dimensions
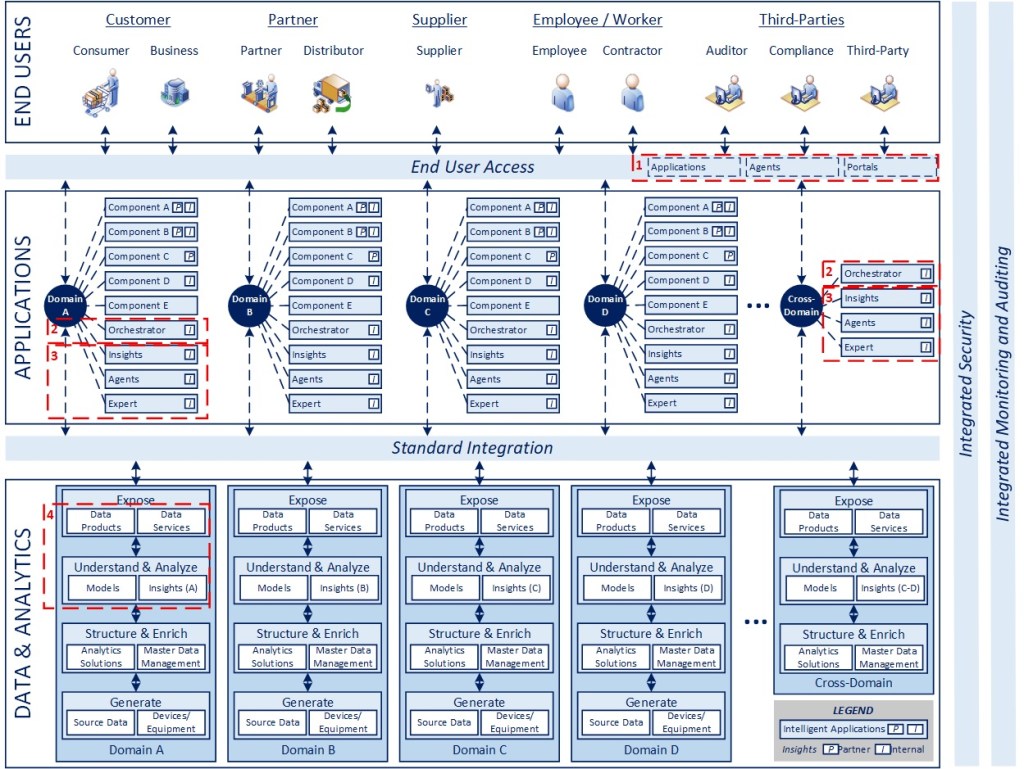
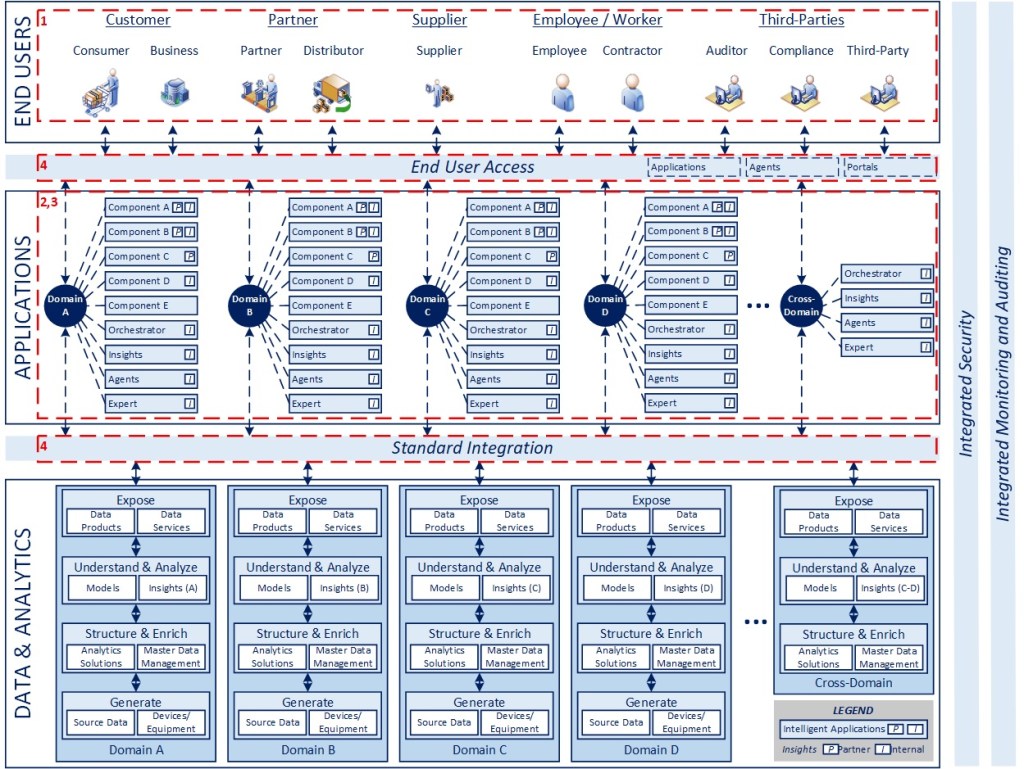
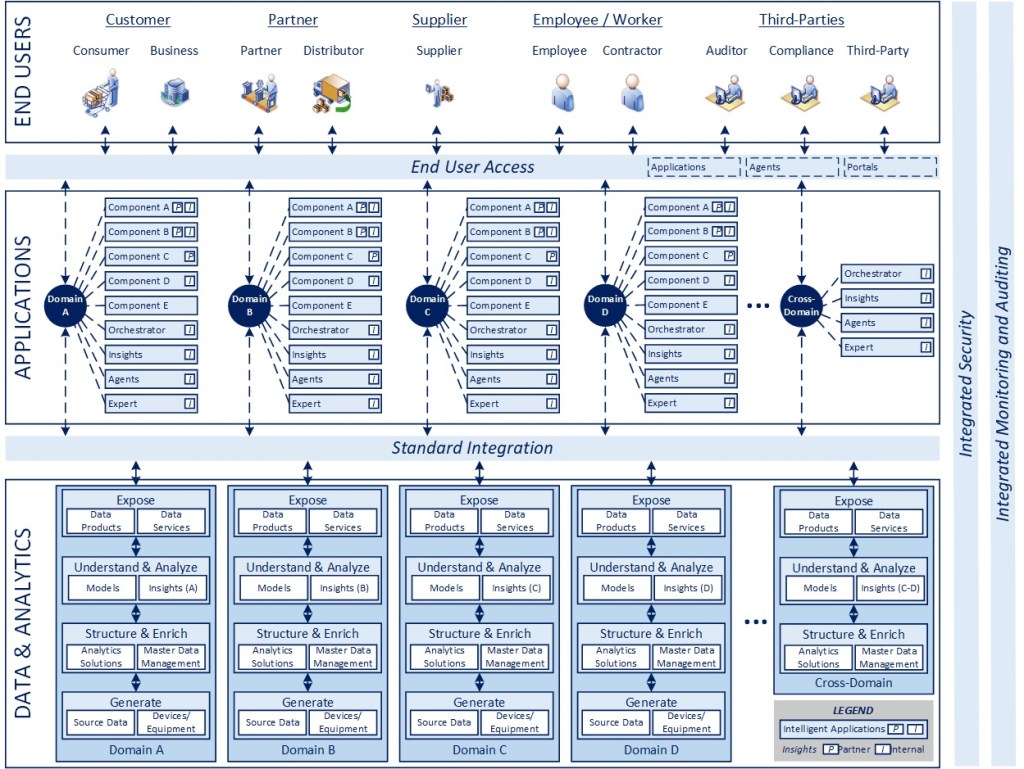
In line with the blueprint above, articles 2-5 highlight key dimensions of the model in the interest of clarifying various aspects of the conceptual design. I am not planning to delve into specific packages or technologies that can be used to implement these concepts as the best way to do something always evolves in technology, while design patterns tend to last. The highlighted areas and associated numbers on the diagram correspond to the dimensions described below.
Before exploring various scenarios for how we will evolve the application landscape, it’s important to note a couple overall assumptions:
End user needs and understanding should come first, then the capabilities
Not every application needs to evolve. There should be a benefit to doing so
I believe the vast majority of product/platform providers will eventually provide AI capabilities
Providing application services doesn’t mean I have to have a “front-end” in the future
Governance is critical, especially to the extent that citizen development is encouraged
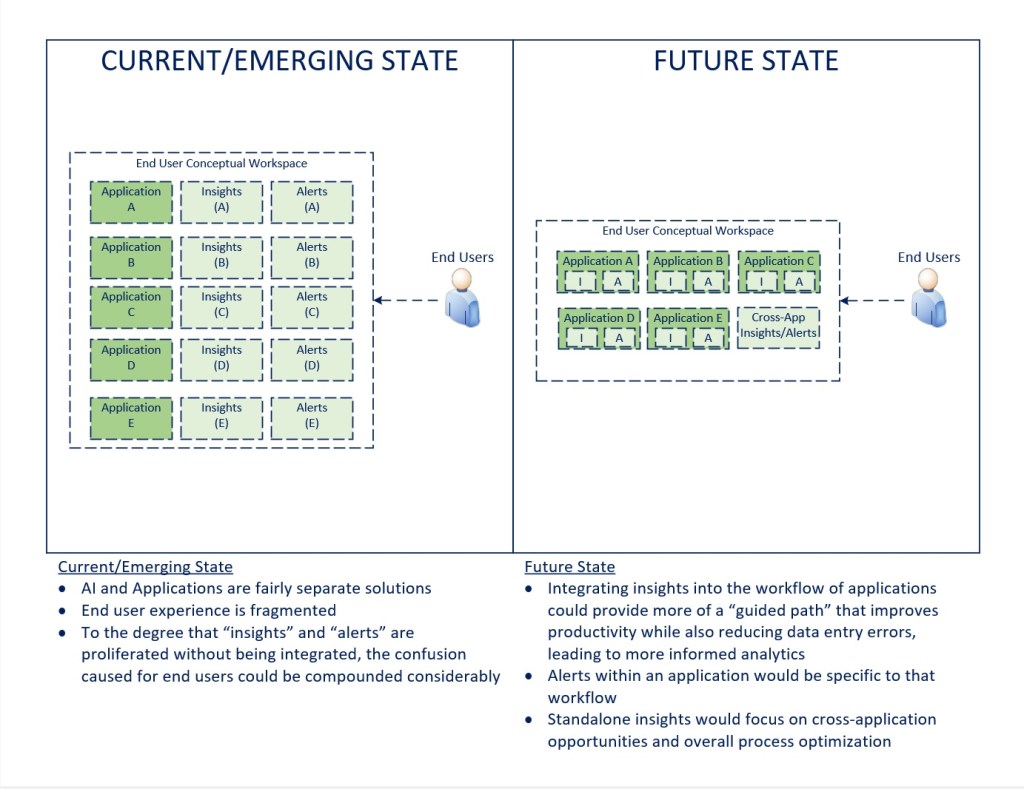
If we’re not mindful how many AI apps we deploy, we will cause confusion and productivity loss because of the fragmented experience
Purchased Software (1)
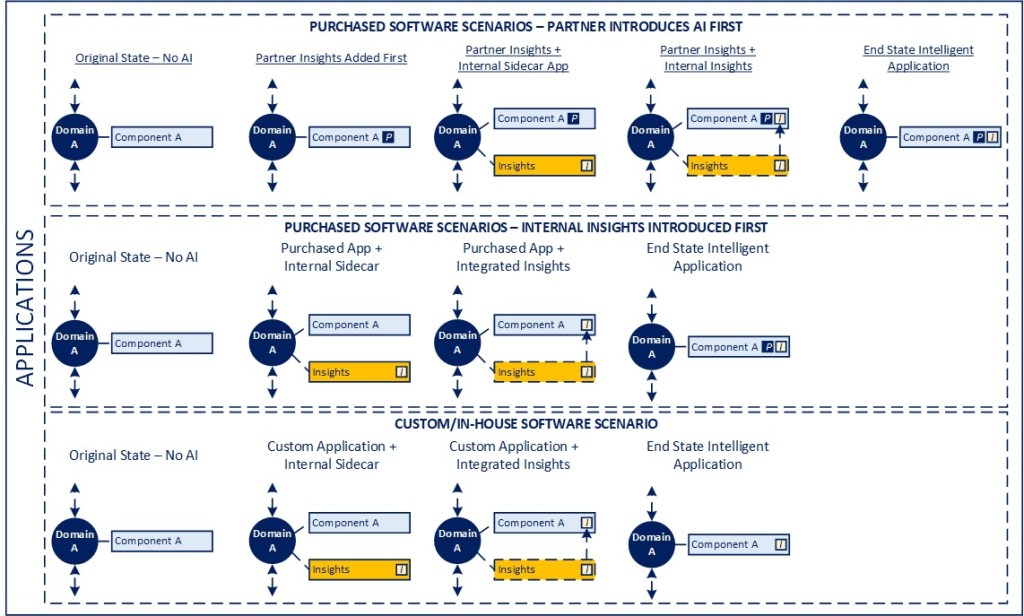
The diagram below highlights a few different scenarios for how I believe intelligence will find its way into applications.
In the case of purchased applications, between the market buzz and continuing desire for differentiation, it is extremely likely that a large share of purchased software products and platforms will have some level of “AI” included in the future, whether that is an AI/ML capability leveraging OLTP data that lives within its ecosystem, or something more causal and advanced in nature.
I believe it is important to delineate between internally generated insights and ones coming as part of a package for several reasons. First, we may not always want to include proprietary data on purchased solutions, especially to the degree they are hosted in the public cloud and we don’t want to expose our internal data to that environment from a security, privacy, or compliance standpoint. Second, we may not want to expose the rules and IP associated with our decisioning and specific business processes to the solution provider. Third, to the degree we maintain these as separate things, we create flexibility to potentially migrate to a different platform more easily than if we are tightly woven into a specific package. And, finally, the required data ingress to comingle a larger data set to expand the nature of what a package could provide “out of the box” may inflate operating costs of the platforms unnecessarily (this can definitely be the case with ERP platforms).
The overall assumption is that, rather than require custom enhancements of a base product, the goal from an architecture standpoint would be for the application to be able to consume and display information from an external AI service that is provided from your organization. This is available today within multiple ERP platforms, as an example.
The graphic below shows two different migration paths towards a future state where applications have both package and internally provided AI capabilities, one where the package provider moves first, internal capabilities are developed in parallel as a sidecar application, and then eventually fully integrated into the platform as a service, and the other way around, assuming the internal capability is developed first, run in parallel, then folded into the platform solution.
Custom-Developed Software (2)
In terms of custom software, the challenge is, first, evaluating whether there is value in introducing additional capabilities for the end user and, second, understanding the implications for trying to integrate the capabilities into the application itself versus leaving them separate.
In the event that there is uncertainty on the end user value of having the capability, implementing the insights as a side car / standalone application, then looking to integrate them within the application as an integrated capability a second step may be the best approach.
If a significant amount of redesign or modernization is required to directly integrate the capabilities, it may make sense to either evaluate market alternatives as a replacement to the internal application or to leave the insights separate entirely. Similar to purchased products, the insights should be delivered as a service and integrated into the application versus being built as an enhancement to provide greater flexibility for how they are leveraged and to simplify migrations to a different solution in the future.
The third scenario in the diagram above is meant to reflect a separate insights application that is then folded into the custom application as a service over time, so that it is a more seamless experience for the end user over time.
Either way, whether it be a purchased or custom-built solution, the important points are to decouple the insights from the applications to provide flexibility, but also to think about both providing a front-end for users to interact with the applications, but also to allow for a service-based approach as well, so that an agent acting on behalf of the user or the system itself could orchestrate various capabilities exposed from that application without the need for user intervention.
From Disconnected to Integrated Insights (3)
One of the reasons for separating out these various migration scenarios is to highlight the risk that introducing too many sidecar or special/single purpose applications could cause significant complexity if not managed and governed carefully. Insights should serve a process or need, and if the goal is to make a user more productive, effective, or safer, those capabilities should ultimately be used to create more intelligent applications that are easier to use. To that end, there likely would be value in working through a full product lifecycle when introducing new capabilities, to determine whether it is meant to be preserved, integrated with a core application (as a service), or tested and possibly decommissioned once a more integrated capability is available.
Summing Up
While the experience of a consumer of technology likely will change and (hopefully) become more intuitive and convenient with the introduction of AI and agents, the need to be thoughtful in how we develop an application architecture strategy, leverage components and services, and put the end user first will be priorities if we are going to obtain the value of these capabilities at an enterprise level. Intelligent applications is where we are headed and our ability to work with an integrated vision of the future will be critical to realizing the benefits available in that world.
The next article will focus on how we should think about the data and analytics environment in the future state.
Up Next: Deconstructing Data-Centricity
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
“If only I could find an article that focused on AI”… said no one, any time recently.
In a perfect world, I don’t want “AI” anything, I want to be able to be more efficient, effective, and competitive. I want all of my capabilities to be seamlessly folded into the way people work so they become part of the fabric of the future environment. That is why having an enterprise-level blueprint for the future is so critically important. Things should fit together seamlessly and they often don’t, especially when we don’t design with integration in mind from the start. That friction slows us down, costs us more, and makes us less productive than we should be.
This is the third post in a series focused on where I believe technology is heading, with an eye towards a more harmonious integration and synthesis of applications, AI, and data… what I previously referred to in March of 2022 as “The Intelligent Enterprise”. The sooner we begin to operate off a unified view of how to align, integrate, and leverage these oftentimes disjointed capabilities today, the faster an organization will leapfrog others in their ability to drive sustainable productivity, profitability, and competitive advantage.
Design Dimensions
In line with the blueprint above, articles 2-5 highlight key dimensions of the model in the interest of clarifying various aspects of the conceptual design. I am not planning to delve into specific packages or technologies that can be used to implement these concepts as the best way to do something always evolves in technology, while design patterns tend to last. The highlighted areas and associated numbers on the diagram correspond to the dimensions described below.
Natural Language First (1)
I don’t own an Alexa device, but I have certainly had the experience of talking to someone who does, and heard them say “Alexa, do this…”, then repeat themself, then repeat themself again, adjusting their word choice slightly, or slowing down what they said, with increasing levels of frustration, until eventually the original thing happens.
These experiences of voice-to-text and natural language processing have been anything but frictionless: quite the opposite, in fact. With the advent of large language models (LLMs), it’s likely that these kinds of interactions will become considerably easier and more accurate, along with the integration of written and spoken input being a means to initiate one or more actions from an end user standpoint.
Is there a benefit? Certainly. Take the case of a medical care provider directing calls to a centralized number for post-operative and case management follow ups. A large volume of calls needs to be processed and there are qualified medical personnel available to handle them on a prioritized basis. The technology can play the role of a silent listener, both recording key points of the conversation and recommended actions (saving time in documenting the calls), and also making contextual observations integrated with the healthcare worker’s application (providing insights) to potentially help address any needs that arise mid-discussion. The net impact could be a higher volume of calls processed due to the reduction in time documenting calls and improved quality of care from the additional insights provided to the healthcare professional. Is this artificial intelligent replacing workers? No, it is helping them be more productive and effective, by integrating into the work they are already doing, reducing the lower value add activities and allowing them to focus more on patient care.
If natural language processing can be integrated such that comprehension is highly accurate, I can foresee where a large amount of end user input could be provided this way in the future. That being said, the mechanics of a process and the associated experience still need to be evaluated so that it doesn’t become as cumbersome as some voice response mechanisms in place today can be, asking you to “say or enter” a response, then confirming what you said back to you, then asking for you to confirm that, only to repeat this kind of process multiple times. No doubt, there is a spreadsheet somewhere to indicate savings for organizations in using this kind of technology by comparison with having someone answer a phone call. The problem is that there is a very tedious and unpleasant customer experience on the other side of those savings, and that shouldn’t be the way we design our future environments.
Orchestration is King (2)
Where artificial intelligence becomes powerful is when it pivots from understanding to execution.
Submitting a natural language request, “I would like to…” or “Do the following on my behalf…”, having the underlying engine convert that request to a sequence of actions, and then ultimately executing those requests is where the power of orchestration comes in.
Back to my earlier article on The Future of IT from March of 2024, I believe we will pivot from organizations needing to create, own, and manage a large percentage of their technology footprint to largely becoming consumers of technologies produced by others, that they configure to enable their business rules and constraints and that they orchestrate to align with their business processes.
Orchestration will exist on four levels in the future:
That which is done on behalf of the end user to enable and support their work (e.g., review messages, notifications, and calendar to identify priorities for my workday)
That which is done within a given domain to coordinate transaction processing and optimize leverage of various components within a given ecosystem (e.g., new hire onboarding within an HR ecosystem or supplier onboarding within the procurement domain)
That which is done across domains to coordinate activity that spans multiple domains (e.g., optimizing production plans coming from an ERP systems to align with MES and EAM systems in Manufacturing given execution and maintenance needs)
Finally, that which is done within the data and analytics environment to minimize data movement and compute while leveraging the right services to generate a desired outcome (e.g., optimizing cost and minimizing the data footprint by comparison with more monolithic approaches)
Beyond the above, we will also see agents taking action on behalf of other, higher-level agents, where there is more of a heirarchical relationship where a process is decomposed into subtasks executed (ideally in parallel) to serve an overall need.
Each of these approaches refer back to the concept of leveraging defined ecosystems and standard integration as discussed in the previous article on the overarching framework.
What is critical is to think about this as a journey towards maturing and exposing organizational capabilities. If we assume an end user wants to initiate a set of transactions through a verbal command, that then is turned in a process to be orchestrated on their behalf, we need to be able to expose the services that are required to ultimately enable that request, whether that involves applications, intelligence, data, or some combination of the three. If we establish the underlying framework to enable this kind of orchestration, however it is initiated, through an application, an agent, or some other mechanism, we could theoretically plug new capabilities into that framework to expand our enterprise-level technology capabilities more and more over time, creating exponential opportunity to make more of our technology investments. The goal is to break down all the silos and make every capability we have accessible to be orchestrated on behalf of an end user or the organization.
I met with a business partner not that long ago who was a strong advocate for “liberating our data”. My argument would be that the future of an intelligent enterprise should be to “liberate all of our capabilities”.
Insights, Agents, and Experts (3)
Having focused on orchestration, which is a key capability within agentic solutions, I did want to come back to three roles that I believe AI can fulfill in an enterprise ecosystem of the future, they are:
Insights – observations or recommendations meant to inform a user to make them more productive, effective, or safer
Agents – applications that orchestrate one or more activities on behalf of or in concert with an end user
Experts – applications that act as a reference for learning and development and to serve as a representation of the “ideal” state either within a given domain (e.g., a Procurement “Expert” may have accumulated knowledge of both best practices, market data, and internal KPIs and goals that allow end users and applications to interact with it as an interactive knowledge base meant to help optimize performance) or across domains (i.e., extending the role of a domain-based expert to be broader to focus on enterprise-level objectives and to help calibrate the goals of individual domains to help achieve those overall outcomes more effectively)
I’m not aware of the “Expert” type capabilities existing for the most part today, but I do believe having more of an autonomous entity that can provide support, guidance, and benchmarking to help optimize performance of individuals and systems could be a compelling way to leverage AI in the future.
AI as a Service (4)
I will address how AI should be integrated into an application portfolio in the next article, but I felt it was important to clarify that I believe that, while AI is being discussed as an objective, a product, and an outcome in many cases today, it is important to think of it as a service that lives and is developed as part of a data and analytics capability. This feels like the right logical association because the insights and capabilities associated with AI are largely data-centric and heavily model dependent, and that should live separate from applications meant to express those insights and capabilities to an end user.
Where the complicating factor could arise from my experience is in how the work is approached and the capabilities of the leaders charged with AI implementation, something I will address in the seventh article in this series on organizational consideration.
Suffice is to say that I see AI as an application-oriented capability, even though it is heavily dependent on data and your underlying model. To the extent that a number of data leaders can come from a background focused on storage, optimization, and performance of traditional or even advanced analytics/data science capabilities, they may not be ideal candidates to establish the vision for AI, given it benefits from more of an outside-in (consumer-driven) mindset than an inside-out (data-focused) approach.
Summing Up
With all the attention being given to AI, the main purpose of breaking it down in the manner I have above it to try and think about how we integrate and leverage it within and across an enterprise, and most importantly: not to treat it as a silo or a one-off. That is not the right way to approach AI moving forward. It will absolutely become part of the way people work, but it is a capability like many other in technology, and it is critically important that we continue to start with the consumers of technology and how we are making them more productive, effective, safe, and so on.
The next two articles will focus on how we integrate AI into the application and data environments.
Up Next: Evolving Applications
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
Why does it take so much time to do anything strategic?
This not an uncommon question to hear in technology and, more often than not, the answer is relatively simple: because the focus in the organization is delivering projects and not establishing an environment to facilitate accelerated delivery at scale. Those are two very different things and, unfortunately, it requires more thought, partnership, and collaboration between business and technology teams than headlines like “let’s implement product teams” or “let’s do an Agile transformation” imply. Can those mechanisms be part of how you execute in a scaled environment? Absolutely, but choosing an operating approach and methodology shouldn’t precede or take priority over having a blueprint to begin with, and that’s the focus of this article.
This is the second post in a series focused on where I believe technology is heading, with an eye towards a more harmonious integration and synthesis of applications, AI, and data… what I previously referred to in March of 2022 as “The Intelligent Enterprise”. The sooner we begin to operate off a unified view of how to align, integrate, and leverage these oftentimes disjointed capabilities today, the faster an organization will leapfrog others in their ability to drive sustainable productivity, profitability, and competitive advantage.
Design Dimensions
In line with the blueprint above, articles 2-5 highlight key dimensions of the model in the interest of clarifying various aspects of the conceptual design. I am not planning to delve into specific packages or technologies that can be used to implement these concepts as the best way to do something always evolves in technology, while design patterns tend to last. The highlighted areas and associated numbers on the diagram correspond to the dimensions described below.
User-Centered Design (1)
A firm conducts a research project on behalf of a fast-food chain. There is always a “coffee slick” in the drive thru, where customers stop and pour out part of their beverage. Is there something wrong with the coffee? No. Customers are worried about burning themselves. The employees are constantly overfilling the drink, assuming that they are being generous, but actually creating a safety concern by accident. Customers don’t want to spill their coffee, so that excess immediately goes to waste.
In the world of technology, the idea of putting enabling technology in the hands of “empowered” end users or delivering that one more “game changing” tool or application is tempting, but often doesn’t deliver the value that is originally expected. This can occur for a multitude of reasons, but what can often be the case is an inadequate understanding of the end user’s mental model, approach to performing their work, or a fundamental misunderstanding that more technology in the hands of a user is always a good thing (when it definitely isn’t the case).
Two learnings that came out of the dotcom era were, first, the value to be derived from investing in user-centered design, thinking through their needs and workflow, and designing experiences around that. The other common practice was assuming that a disruptive technology (the internet in this case) was cause to spin out a separate organization (the “eBusiness” teams of the time) meant to incubate and accelerate development of capabilities that embraced the new technology. These teams generally lacked a broader understanding of the “traditional” business and its associated operating requirements, and thus began the ”bricks versus clicks” issues and channel conflict that eventually led to these capabilities being folded back into the broader organization, but only after having spent time and (in many cases) a considerable amount of money experimenting without producing sustainable business value.
In the case of artificial intelligence, it’s tempting to want to stand up new organizations or repurpose existing ones to mobilize the technology or to assume everything will eventually be relegated to a natural language-based interface where a user provides a description of what they want into an agent acting at their personal virtual assistant, with system deriving the appropriate workflow and orchestrating the necessary actions to support the request. While that may be a part of our future reality, taking an approach similar to the dotcom era would be a mistake and there will lost opportunity where this is the chosen path.
To be effective in a future digital world with AI, we need to think of how we want things integrated at the outset, starting with that critical understanding of the end user and how they want to work. Technology is meant to enable and support them, not the other way around, and leading with technology versus a need is never going to be an optimal approach… a lesson we’ve been shown many times over the years, no matter how disruptive the technology advancement has been.
I will address some of the organizational implications of the model in the seventh article in this series, so the remainder of this post will be on the technology framework itself.
Designing Around Connected Ecosystems (2)
Domain-driven design is not a new concept in technology.
As I mentioned in the first article, the technology footprint of most medium- to large-scale organizations is complex and normally steeped in redundancies, varied architectures, unclear boundaries between custom and purchased software, hosted and cloud-based based environments, hard coded integrations, and standard ways of moving data within and across domains.
While package solutions offer some level of logical separation of concerns between different business capabilities, the natural tendency in the product and platform space is to move towards more vertically or horizontally integrated solutions that create customer lock in and make interoperability very challenging, particularly in the ERP space. What also tends to occur is that an organization’s data model is biased to conform to what works best for a package or platform, but not necessarily the best representation of their business or their consumers of technology (something I will address in article 5 on Data & Analytics).
In terms of custom solutions, given they are “home grown”, there is a reasonable probability that, unless they were well-architected at the outset, they very likely provide multiple capabilities, without clear separation of concerns in ways that make them difficult to integrate with other systems in “standard” ways.
While there is nothing unique about these kinds of challenges, the problem comes when new technology capabilities like AI are available and we want to either replace or integrate things in a different way. This is where the lack of enterprise-level design and a broader, component-based architecture takes its toll, because there likely will be significant remediation, refactoring, and modernization required to enable existing systems to interoperate with the new capabilities. These things take time, add risk, and ultimately cost to our ability to respond when these opportunities arise, and no one wants to put new plumbing in a house that is already built with a family living in it.
On the other hand, in an environment with defined, component-based ecosystems that uses standard integration patterns, replacing individual components becomes considerably easier and faster, with much less disruption at both a local- and an enterprise-level. In a well-defined, component-based environment, I should be able to replace my Talent Acquisition application without having to impact my Performance Management, Learning & Development, or Compensation & Benefits solutions from an HR standpoint. Similarly, I shouldn’t need to make changes to my Order Management application within my Sales ecosystem because I’m transitioning to a different CRM package. To the extent that you are using standard business objects to support integration across systems, the need to update downstream systems in other domains should be minimized as well. Said differently, if you want to be fast, be disciplined in your design.
Modular, Composable, Standardized (3)
Beyond designing towards a component-based environment, it is also important to think about capabilities independent of a given process so you have more agility in how you ultimately leverage and integrate different things over time.
Using a simple example from personal lines insurance, I want to be able to support a third-party rating solution by exposing a “GetQuote” function that takes necessary customer information and coverage-related parameters and sends back a price. From a carrier standpoint, the process may involve ordering credit and pulling a DMV report (for accidents and violations) as inputs to the process. I don’t necessarily want these capabilities to be developed internal to the larger “GetQuote”, because I may want to leverage them for any one of a number of other reasons, so that smaller grained (more atomic) transactions should also be defined as services that can be leveraged by the larger one. While this is a fairly trivial case, there are often situations where delivery efforts move at such a rapid pace that things are tightly coupled or built together that really should be discreet and separate, providing more flexibility and leverage of those individual services over time.
This also can occur in the data and analytics space, where there are normally many different tools and platforms between the storage and consumption layers and ideally you want to optimize data movement and computing resources such that only the relevant capabilities are included in a data pipeline based on specific customer needs.
The flexibility described above is predicated on a well-defined architecture that is service-based and composable, with standard integration patterns, that leverages common business objects for as many transactions as practical. That isn’t to say that there are times where the economics make sense to custom code something or to leverage point-to-point integration, rather that thinking about reuse and standardized approaches up front is a good delivery practice to avoid downstream cost and complexity, especially when the rate of new technologies being introduced is as high as it is today.
Leveraging Standard Integration (4)
Having mentioned standard integration above, my underlying assumption is that we’re heading towards a near real-time environment where streaming infrastructure and publish and subscribe models are going to be critical infrastructure to enable delivery of key insights and capabilities to consumers of technology. To the extent that we want that infrastructure to scale and work efficiently and consistently, there is a built-in incentive to be intentional about the data we transmit (whether that is standard business objects or smaller data sets coming from connected equipment and devices) as well as the ways we connect to these pipelines across application and data solutions. Adding a data publisher or consumer shouldn’t require rewriting anything per se, any more than plugging in a new appliance to a power outlet in your home should require you to either unplug something else or change the circuit board and wiring itself (except in extreme cases).
Summing Up
I began this article with the observation about delivering projects by comparison with establishing an environment for delivering repeatably at scale. In my experience, depending on the scale of an organization, there will be some level of many of the things I’ve mentioned above in place, but then a potentially large set of pain points and opportunities across the footprint where things are suboptimized.
This is not about boiling the ocean or suggesting we should start over. The point of starting with the framework itself is to raise awareness that the way we establish the overall environment has a significant ripple effect into our ability to do things we want to do downstream to leverage new capabilities and get the most out of our technology investments later on. The time spent in design is well worth the investment, so long as it doesn’t become analysis paralysis.
To that end, in summary:
Design from the end user and their needs first
Think and design with connected ecosystems in mind
Be purposeful in how you design and layer services to promote reuse and composability
Leverage standards in how you integrate solutions to enable near real-time processing
It is important to note that, while there are important considerations in terms of hosting, security, and data movement across platforms, I’m focusing largely on the organization and integration of the portfolios needed to support an organization. From a physical standpoint, the conceptual diagram isn’t meant to suggest that any or all of these components or connected ecosystems need to be managed and/or hosted internal to an organization. My overall belief is that, the more we move to a service-driven environment, the more of a producer/consumer model will emerge where corporations largely act as an integrator and orchestrator (aka “consumer”) of services provided by third-parties (the “producers”). To the extent that the architecture and standards referenced above are in place, there shouldn’t be any significant barriers to moving from a more insourced and hosted environment to a more consumption-based, outsourced, and cloud-native environment in the future.
With the overall framework in place, the next three articles will focus on the individual elements of the environment of the future, in terms of AI, applications, and data.
Up Next: Integrating Artificial Intelligence
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
The challenges involved in managing a technology footprint today at any medium to large organization are very high for a multitude of reasons:
Proliferation of technologies and solutions that are disconnected or integrated in inconsistent ways, making simplification or modernization efforts difficult to deliver
Mergers and acquisitions that bring new systems into the landscape that aren’t rationalized with or migrated to existing systems, creating redundancy, duplication of capabilities, and cost
“Speed-to-market” initiatives involving unique solution approaches that increase complexity and cost of ownership
A blend of in-house and purchased software solutions, hosted across various platforms (including multi-cloud), increasing complexity and cost of security, integration, performance monitoring, and data movement
Technologies advancing at a rate, especially with the introduction of artificial intelligence (AI), that organizations can’t integrate them quickly enough to do so in a consistent manner
Decentralized or federated technology organizations that operate with relative autonomy, independent of standards, frameworks, or governance, which increases complexity and cost
The result of any of the above factors can be enough cost and complexity that the focus within a technology organization can shift from innovation and value creation to struggling to keep the lights on and maintaining a reliable and secure operating environment.
This article will be the first in a series focused on where I believe technology is heading, with an eye towards a more harmonious integration and synthesis of applications, AI, and data… what I previously referred to in March of 2022 as “The Intelligent Enterprise”. The sooner we begin to operate off a unified view of how to align, integrate, and leverage these oftentimes disjointed capabilities today, the faster an organization will leapfrog others in their ability to drive sustainable productivity, profitability, and competitive advantage.
Why It Matters
Before getting into the dimensions of the future state, I wanted to first clarify how these technology challenges manifest themselves in meaningful ways, because complexity isn’t just an IT problem, it’s a business issue, and partnership is important in making thoughtful choices in how we approach future solutions.
Lost Productivity
A leadership team at a manufacturing facility meets first thing in the morning. It is the first of multiple they will have throughout the course of a day. They are setting priorities for the day collectively because the systems that support them: a combination of applications, analytics solutions, equipment diagnostics, and AI tools, are all providing different perspectives on priorities and potential issues, but in disconnected ways, and it is now on the leadership team to decide which of these should receive attention and priority in the interest of making their production targets for a day. Are they making the best choices in terms of promoting efficiency, quality, and safety? There’s no way to know.
Is this an unusual situation? Not at all. Today’s technology landscape is often a tapestry of applications with varied levels of integration and data sharing, data apps and dashboards meant to provide insights and suggestions, and now AI tools to “assist” or make certain activities more efficient for an end user.
The problem is what happens when all these pieces end up on someone’s desktop, browser, or mobile device and they are left to copy data from one solution to the other, arbitrate which of various alerts and notifications is most important, identify dependencies to help make sure they are taking the right actions in the right sequence (in a case like directed work activity), and quite often that time is lost productivity in itself, regardless of which path they take, which may amplify the impact further, given retention and/or high turnover are real issues in some jobs that reduce the experience available to navigate these challenges successfully.
Lower Profitability
The result of this lost productivity and ever-expanding technology footprint is both lost revenue (to the extent it hinders production or effective resource utilization) and higher operating cost, especially to the degree that organizations introduce the next new thing without retiring or replacing what was already in place, or integrating things effectively. Speed-to-market is a short-term concept that tends to cause longer-term cost of ownership issues (as I previously discussed in the article “Fast and Cheap Isn’t Good”), especially to the degree that there isn’t a larger blueprint in place to make sure such advancements are done in a thoughtful, deliberate manner.
To this end, how we do something can be as important as what we intend to do, and there is an argument for thinking through the operating implications when undertaking new technology efforts with a more holistic mindset than a single project tends to take in my experience.
Lost Competitive Advantage
Beyond the financial implications, all of the varied solutions, accumulated technologies and complexity, and custom or interim band aids built to connect one solution to the next eventually catches up in a form of what one organization used to refer to as “waxy buildup” that prevents you from moving quickly on anything. What seems on paper to be a simple addition or replacement becomes a lengthy process of analysis and design that is cumbersome and expensive, where the lost opportunity is speed-to-market in an increasingly competitive marketplace.
This is where the new market entrants thrive and succeed, because they don’t carry the legacy debt and complexity of entrenched market players who are either too slow to respond or too resistant to change to truly transform at a level that allows them to sustain competitive advantage. Agility gives way to a “death by a thousand paper cuts” of tactical decisions made that were appropriate and rational in the moment, but created significant amounts of technical debt that inevitably must be paid.
A Vision for the Future
So where does this leave us? Pack up the tent and go home? Of course not.
We are at a significant inflection point with AI technology that affords us the opportunity to examine where we are and to start adjusting our course to a more thoughtful and integrated future state where AI, applications, and data and analytics solutions work in concert and harmony with each other versus in a disconnected reality of confusion.
It begins with the consumers of these capabilities, supported by connected ecosystems of intelligent applications, enabled by insights, agents, and experts, that infuse intelligence into making people productive, businesses agile and competitive, and improve value derived from technology investments at a level disproportionate to what we can achieve today.
The remaining articles in this series will focus on various dimensions of what the above conceptual model means, as a framework, in terms of AI, applications, and data, and then how we approach that transition and think about it from an IT organizational perspective.
Up Next: Establishing the Framework for the future…
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
In my first blog article back in 2021, I wrote that “we learn to value experience only once we actually have it”… and one thing I’ve certainly realized is that it’s much easier to do something quickly than to do it well. The problem is that excellence requires discipline, especially when you want to scale or have sustainable results, and that often comes into conflict with a natural desire to achieve speed in delivery.
There is a tremendous amount of optimism in the transformative value AI can create across a wide range of areas. While much continues to be written about various tools, technologies, and solutions, there is value in having a structured approach to developing AI strategy and how we will govern it once it is implemented across an organization.
Why? We want results.
Some historical examples on why there is a case for action:
Many organizations have leveraged SharePoint as a way to manage documents. Because it’s relatively easy to use, access to the technology generally is provided to a broad set of users, with little or no guidance on how to use it (e.g., metatagging strategy), and over time there becomes a sprawl of content that may contain critical, confidential, or proprietary information with limited overall awareness of what exists and where
In the last number of years, Citizen Development has become popular, with the rise of low code, no code, and RPA tools, creating accessibility to automation that is meant to enable business (and largely non-technical) resources to rapidly create solutions, from the trivial to relatively complex. Quite often these solutions aren’t considered part of a larger application portfolio, are managed with little or no oversight, and become difficult to integrate, leverage, or support effectively
In data and analytics, tools like Alteryx can be deployed across a broad set of users who, after they are given access to requested data sources, create their own transformations, dashboards, and other analytical outputs to inform ongoing business decisions. The challenge occurs when the underlying data changes, is not understood properly (and downstream inferences can be incorrect), or these individuals leave or transition out of their roles and the solutions they built are not well understood or difficult for someone else to leverage or support
What these situations have in common is the introduction of something meant to serve as an enabler that has relative ease of use and accessibility across a broad audience, but where there also may be a lack of standards and governance to make sure the capabilities are introduced in a thoughtful and consistent manner, leading to inefficiency, increased cost, and lost opportunity. With the amount of hype surrounding AI, the proliferation of tools, and general ease of use that they provide, the potential for organizations to create a mess in the wake of their experimentation with these technologies seems very significant.
The focus of the remainder of this article is to explore some dimensions to consider in developing a strategy for the effective use and governance of AI in an organization. The focus will be on the approach, not the content of an AI strategy, which can be the subject of a later article. I am not suggesting that everything needs to be prescriptive, cumbersome, or bureaucratic to the point that nothing can get done, but I believe it is important to have a thoughtful approach to avoid the pitfalls that are common to these situations.
To the extent that, in some organizations, “governance” implies control versus enablement or there are historical real or perceived IT delivery issues, there may be concern with heading down this path. Regardless of how the concepts are implemented, I believe they are worth considering sooner rather than later, given we are still relatively early in the adoption process of these capabilities.
Dimensions to Consider
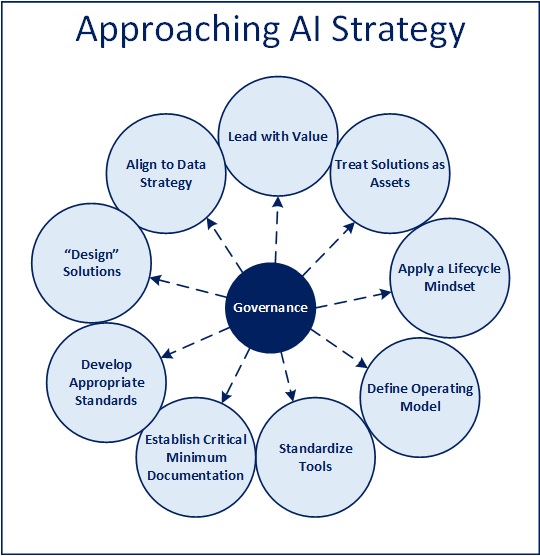
Below are various aspects of establishing a strategy and governance process for AI that are worth consideration. I listed them somewhat in a sequential manner, as I’d think about them personally, though that doesn’t imply you can’t explore and elaborate as many as are appropriate in parallel, and in whatever order makes sense. The outcome of the exercise doesn’t need to be rigid mandates, requirements, or guidelines per se, but nearly all of these topics likely will come up implicitly or otherwise as we delve further into leveraging these technologies moving forward.
Lead with Value
The first dimension is probably the most important in forming an AI strategy, which is to articulate the business problems being solved and value that is meant to be created. It is very easy with new technologies to focus on the tools and not the outcomes and start implementing without a clear understanding of the impact that is intended. As a result, measuring the value created and governing the efficacy of the solutions delivered becomes extremely difficult.
As a person who does not believe in deploying technology for technology’s sake, identifying, tracking, and measuring impact is important in knowing we will ultimately make informed decisions in how we leverage new capabilities and invest in them appropriately over time.
Treat Solutions as Assets
Along the lines of the above point, there is risk associated with being consumed by what is “cool” versus what is “useful” (something I’ve written about previously), and treating new technologies like “gadgets” versus actual business solutions. Where we treat our investments as assets, the associated discipline we apply in making decisions surrounding them should be greater. This is particularly important in emerging technology because the desire to experiment and leverage new tools could quickly become unsustainable as the number of one-off solutions grows and is unsupportable, eventually draining resources from new innovation.
Apply a Lifecycle Mindset
When leveraging a new technical capability, I would argue that we should look for opportunities to think of the full product lifecycle when it comes to how we identify, define, design, develop, manage, and retire solutions. In my experience, the identify (finding new tools) and develop (delivering new solutions) aspects of the process receive significant emphasis in a speed-to-market environment, but the others much less so, and often to the overall detriment of an organization when they quickly are saddled with the resulting technical debt that comes from neglecting some of the other steps in the process. This doesn’t necessarily imply a lot of additional steps, process overhead, or time/effort to be expended, but there is value created in each step of a product lifecycle (particularly in the early stages) and all of them need to be given due consideration if you want to establish a sustainable, performant environment. The physical manifestation of some these steps could be as simple as a checklist to make sure there aren’t blind spots that arise later on that were avoidable or that create business risk.
Define Operating Model
Introducing new capabilities, especially ones where the barrier to entry/ease of use allows for a wide audience of users can cause unintended consequences if not managed effectively. While it’s tempting to draw a business/technology dividing line, my experience has been that there can be very technically capable business consumers of technology and very undisciplined technologists who implement it as well. The point of thinking through the operating model is to identify roles and responsibilities in how you will leverage new capabilities so that expectations and accountability is clear, along with guidelines for how various teams are meant to collaborate over the lifecycle mentioned above.
Whether the goal is to “empower end users” by fully distributing capabilities across teams, with some level of centralized support and governance, or fully centralizing with decentralized demand generation (or any flavor in between), the point is to understand who is best positioned to contribute at different steps of the process and promote consistency to an appropriate level so performance and efficacy of both the process and eventual solutions is something you can track, evaluate, and improve over time. As an example, it would likely be very expensive and ineffective to hire a set of “prompt engineers” that operate in a fully distributed manner in a larger organization by comparison with having a smaller, centralized set of highly skilled resources who can provide guidance and standards to a broader set of users in a de-centralized environment.
Following onto the above, it is also worthwhile to decide whether and how these kinds of efforts should show up in a larger portfolio management process (to the extent one is in place). Where AI and agentic solutions are meant to displace existing ways of working or produce meaningful business outcomes, the time spent delivering and supporting these solutions should likely be tracked so there is an ability to evaluate and manage these investments over time.
Standardize Tools
This will likely be one of the larger issues that organizations face, particularly given where we are with AI in a broader market context today. Tools and technologies are advancing at such a rapid rate that having a disciplined process for evaluating, selecting, and integrating a specific set of “approved” tools is and will be challenging for some time.
While asking questions of a generic large language model like ChatGPT, Grok, DeepSeek, etc. and changing from one to the other seems relatively straightforward, there is a lot more complexity involved when we want to leverage company-specific data and approaches like RAG to produce more targeted and valuable outcomes.
When it comes to agentic solutions, there is also a proliferation of technologies at the moment. In these cases, managing the cost, complexity, performance, security, and associated data privacy issues will also become complex if there aren’t “preferred” technologies in place and “known good” ways in which they can be leveraged.
Said differently, if we believe effective use of AI is critical to maintaining competitive advantage, we should know that the tools we are leveraging are vetted, producing quality results, and that we’re using them effectively.
Establish Critical Minimum Documentation
I realize it’s risky to use profanity in a professional article, but documentation has to be mentioned if we assume AI is a critical enabler for businesses moving forward. Its importance can probably be summarized if you fast forward one year from today, hold a leadership meeting, and ask “what are all the ways we are using artificial intelligence, and is it producing the value we expected a year ago?” If the response contains no specifics and supporting evidence, there should be cause for concern, because there will be significant investment made in this area over the next 1-2 years, and tracking those investments is important to realizing the benefits that are being promised everywhere you look.
Does “documentation” mean developing a binder for every prompt that is created, every agent that’s launched, or every solution that’s developed? No, absolutely not, and that would likely be a large waste of money for marginal value. There should be, however, a critical minimum amount of documentation that is developed in concert with these solutions to clarify their purpose, intended outcome/use, value to be created, and any implementation particulars that may be relevant to the nature of the solution (e.g. foundational model, data sets leveraged, data currency assumptions, etc.). An inventory of the assets developed should exist, minimally so that it can be reviewed and audited for things like security, compliance, IP, and privacy-related concerns where applicable.
Develop Appropriate Standards
There are various types of solutions that could be part of an overall AI strategy and the opportunity to develop standards that promote quality, reuse, scale, security, and so forth is significant. Whether it takes the form of a “how to” guide for writing prompts, to data sourcing and refresh standards with RAG-enabled solutions, reference architecture and design patterns across various solution types, or limits to the number of agents that can be developed without review for optimization opportunities… In this regard, something pragmatic, that isn’t overly prescriptive but that also doesn’t reflect a total lack of standards would be appropriate in most organizations.
In a decentralized operating environment, the chance that solutions will be developed in a one-off fashion, with varying levels of quality, consistency, and standardization is highly probable and that could create issues with security, scalability, technical debt, and so on. Defining the handshake between consumers of these new capabilities and those developing standards, along with when it is appropriate to define them, could be important things to consider.
Design Solutions
Again, as I mentioned in relation to the product lifecycle mindset, there can be a strong preference to deliver solutions without giving much thought to design. While this is often attributed to “speed to market” and a “bias towards action”, it doesn’t take long for tactical thinking to lead to a considerable amount of technical debt, an inability to reuse or scale solutions, or significant operating costs that start to slow down delivery and erode value. These are avoidable consequences when thought is given to architecture and design up front and the effort nearly always pays off over time.
Align to Data Strategy
This topic could be an article in itself, but suffice is to say that having an effective AI strategy is heavily dependent on an organization’s overall data strategy and the health of that portfolio. Said differently: if your underlying data isn’t in order, you won’t be able to derive much in terms of meaningful insights from it. Concerns related to privacy and security, data sourcing, stewardship, data quality, lineage and governance, use of multiple large language models (LLMs), effective use of RAG, the relationship of data products to AI insights and agents, and effective ways of architecting for agility, interoperability, composability, evolution, and flexibility are all relevant topics to be explored and understood.
Define and Establish a Governance Process
Having laid out the above dimensions in terms of establishing and operationalizing an AI strategy, there needs to be a way to govern it. The goal of governance is to achieve meaningful business outcomes by promoting effective use and adoption of the new capabilities, while managing exposure related to introducing change into the environment. This could be part of an existing governance process or set up in parallel and coordinated with others in place, but the point is that you can’t optimize what you don’t monitor and manage, and the promise of AI is such that we should be thoughtful about how we govern its adoption across an organization.
Having worked both in consulting and corporate environments for many years and across multiple industries, we’re at an interesting juncture in how technology is leveraged at a macro-level and the broader business and societal impacts of those choices. Whether that is AI-generated content that could easily be mistaken for “real” events to the leverage of data collection and advanced analytics in various business and consumer scenarios to create “competitive advantage”.
The latter scenario has certainly been discussed for quite a while, whether it is in relation to managing privacy while using mobile devices, trusting a search engine and how they “anonymize” your data before potentially selling it to third parties, or whether the results presented as the outcome of a search (or GenAI request) is objective and unbiased, or being presented with some level of influence given the policies or leanings of the organization sponsoring it.
The question to be explored here is: How do we define the ethical use of technology?
For the remainder of this article, I’ll suggest some ways to frame the answer in various dimensions, acknowledging that this isn’t a black-and-white issue and the specifics of a situation could make some of the considerations more or less relevant.
Considerations
What Ethical Use Isn’t
Before diving into what I believe could be helpful in framing an answer, I wanted to clarify what I don’t consider a valid approach, which is namely the argument used in a majority of cases where individuals or organizations cross a line: We can use technology in this way because it gives us competitive advantage.
Competitive advantage can tend to be an easy argument in the interest of doing something questionable, because there is a direct or indirect financial benefit associated with the decision, thereby clouding the underlying ethics of the decision itself. “We’re making more money, increasing shareholder value, managing costs, increasing profitability, etc.” are things that tend to move the needle in terms of the roadblocks that can exist in organizations and mobilizing new ideas. The problem is that, with all of the data collected in the interest of securing approval and funding for initiative, I haven’t seen many cases where there is a proverbial “box to check” in terms of the effort conforming to ethical standards (whether that’s specific to technology use or otherwise).
What Ethical Use Could Be
That point having been stated, below are some questions that could be considered as part of an “ethical use policy”, understanding that not all may have equal weight in an evaluation process.
They are:
Legal/Compliance/Privacy
Does the ultimate solution conform to existing laws and regulations for your given industry?
Is there any pending legislation related to the proposed use of technology that could create such a compliance issue?
Is there any industry-specific legislation that would suggest a compliance issue if it were logically applied in a new way that relates to the proposed solution?
Would the solution cause a compliance issue in another industry (now or in legislation that is pending)? Is there risk of that legislation being applied to your industry as well?
Transparency
Is there anything about the nature of the solution that, were it shared openly (e.g., through a press release or industry conference/trade show) would cause customers, competitors, or partners/suppliers to raise issues with the organization’s market conduct or end user policies? This can be a tricky item given the previous points on competitive advantage and what might be labeled as “trade secret” but potentially violate anti-trust, privacy, or other market expectations
Does anything about the nature of the solution, were it to be shared openly, suggest that it could cause trust issues between customers, competitors, suppliers, or partners with the organization and, if so, why?
Cultural
Does the solution align to your organization’s core values? As an example, if there is a transparency concern (above) and “Integrity” is a core value (which it is in many organizations), why does that conflict exist?
Does the solution conform to generally accepted practices or societal norms in terms of business conduct between you and your target audience (customers, vertical or horizontal partners, etc.)?
Social Responsibility
Does the solution create any potential issues from an environmental, societal, or safety standpoint that could have adverse impacts (direct or indirect)?
Autonomy and Objectivity
Does the solution provide an unbiased, fact-based (or analytically-correct) outcome, free of any potential bias, that can also be governed, audited, and verified? This is an important dimension to consider given the dependency we have on automation continues to increase and we want to be able to trust the security, reliability, accuracy, and so on of what that technology provides.
Competitive
If a competitor announced they were developing a solution of exactly the same nature as what is proposed, would it be comfortable situation or something that you would challenge as unethical or unfair business practice in any way? Quite often, the lens through which unethical decisions are made is biased with an internal focus. If that line of sight were reversed and a competitor was open about doing exactly the same thing, would that be acceptable or not? If there would be issues, likely there might be cause for concern in developing the solution yourself
Wrapping Up
From a process standpoint, a suggestion would be to take the above list and discuss it openly in the interest of not only determining the right criteria for you, but also to establish where these opportunities exist (because they do and will, the more analytics and AI-focused capabilities advance). Ultimately, there should be a check-and-balance process for ethical use of technology in line with any broader compliance and privacy-related efforts that may exist within an organization today.
Ultimately, the “right thing to do” can be a murky and difficult question to answer, especially with ever-expanding tools and technologies that create capabilities a digital business can use to its advantage. But that’s where culture and values should still exist, not simply because there is or isn’t a compliance issue, but because reputations are made and reinforced over time through these kinds of decisions, and they either help build a brand or can damage it when the right questions aren’t explored at the right time.
It’s interesting to consider, as a final note, that most companies have an “acceptable use of IT” policy for employees, contractors, and so forth, in terms of setting guidelines for what they can or can’t do (e.g., accessing ‘prohibited’ websites / email accounts or using a streaming platform while at work), but not necessarily for technology directed outside the organization. As we enter a new age of AI-enabled capabilities, perhaps it’s a good time to look at both.
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
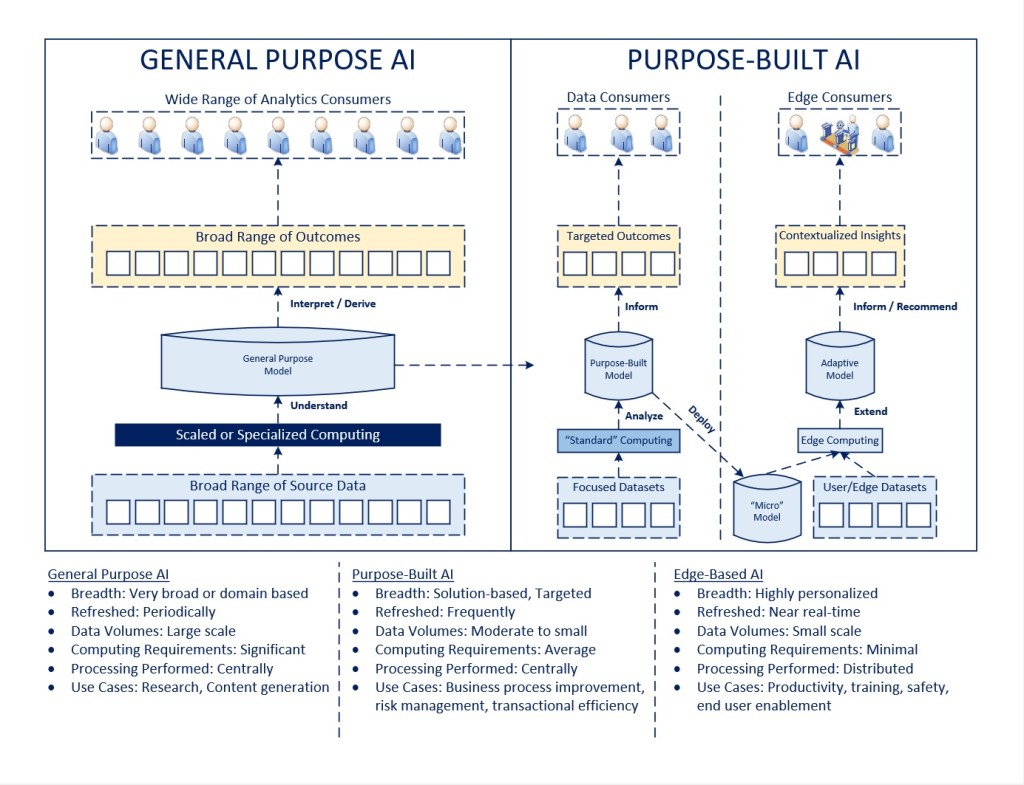
In my recent article on Exploring Artificial Intelligence, I covered several dimensions of how I think about the direction of AI, including how models will evolve from general-purpose and broad-based to be more value-focused and end consumer-specific as the above diagram is intended to illustrate.
The purpose of this article is to dive a little deeper into a mental model for how I believe the technology could become more relevant and valuable in an end-user (or end consumer) specific context.
Before that, a few assertions related to the technology and end user application of the technology:
The more we can passively collect data in the interest of simplifying end-user tasks and informing models, the better. People can be both inconsistent and unreliable in how they capture data. In reality, our cell phones are collecting massive amounts of data on an ongoing basis that is used to drive targeted advertising and other capabilities to us without our involvement. In a business context, however, the concept of doing so can be met with significant privacy and other concerns and it’s a shame because, while there is data being collected on our devices regardless, we aren’t able to benefit from it in the context of doing our work
Moving from a broad- or persona-based means of delivering technology capabilities to a consumer-specific approach is a potentially significant advancement in enabling productivity and effectiveness. This would be difficult or impossible to achieve without leveraging an adaptive approach that synthesizes various technologies (personalization, customization, dynamic code generation, role-based access control, AI/ML models, LLMs, content management, and so forth) to create a more cohesive and personalized user experience
While I am largely focusing on end-user application of the technology, I would argue that the same concepts and approach could be leveraged for the next generation of intelligent devices and digital equipment, such as robotics in factory automation scenarios
To make the technology both performant and relevant, part of the design challenge is to continually reduce and refine to level of “model” information that is needed at the next layer of processing so as not to overload the end computing device (presumably a cell phone or tablet) with a volume of data that isn’t required to enable effective action on behalf of the data consumer.
The rest of this article will focus on providing a mental model for how to think about the relationship across the various kinds of models that may make up the future state of AI.
Starting with a “Real World” example
Having spent a good portion of my time off traveling across the U.S., while I had a printed road atlas in my car, I was reminded of the trust I place in Google Maps more than once, particularly when driving through an “open range” gravel road with cattle roaming about in northwest Nebraska on my way to South Dakota. In many ways, navigation software represents a good starting point for where I believe intelligent applications will eventually go in the business environment.
Maps is useful as a tool because it synthesizes what data is has on roads and navigation options with specific information like my chosen destination, location, speed traps, delays, and accident information that is specific to my potential routes, allowing for a level of customization if I prefer to take routes that avoid tolls and so on. From an end-user perspective, it provides a next recommended action, remaining contextually relevant to where I am and what I need to do, along with how long it will be both until that action needs to be taken as well as the distance remaining and time I should arrive at my final destination.
In a connected setting, navigation software pulls pieces of its overall model and applies data on where I am and where I’m going, to (ideally) help me get where I’m going as efficiently as possible. The application is useful because it is specific to me, to my destination, and to my preferred route, and is different than what would be delivered to a car immediately behind me, despite leveraging the same application and infrastructure. This is the direction I believe we need to go with intelligent applications, to drive individual productivity and effectiveness.
Introducing the “Tree of Knowledge” concept
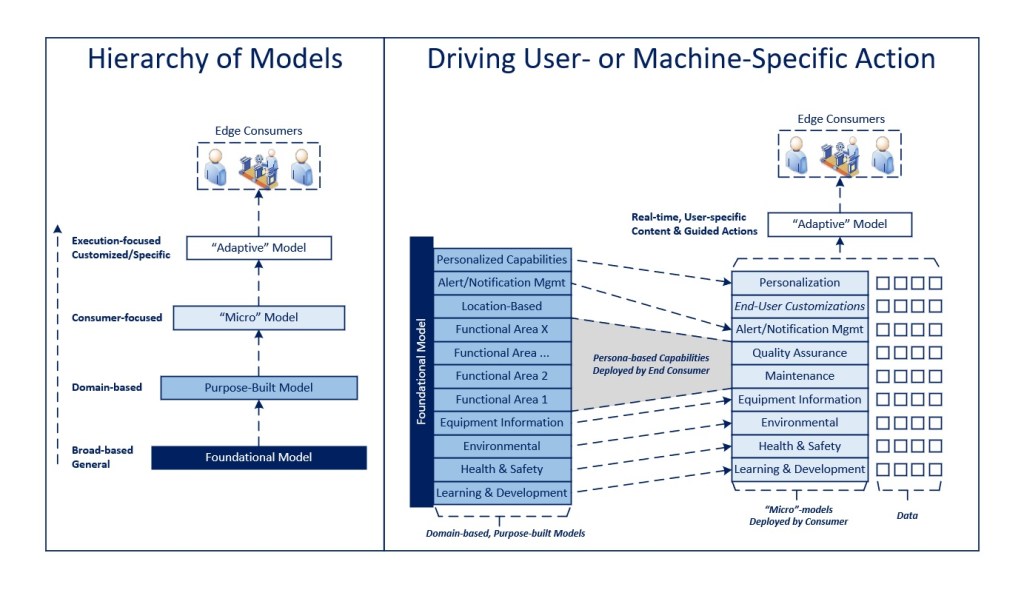
The Overall Model
The visual above is meant to represent the relationship of general-purpose and foundational models to what ultimately are delivered to an end-user (or piece of digital equipment) in a distributed fashion.
Conceptually, I think of the relationship across data sets as if it were a tree.
The general-purpose model (e.g., LLM) provides the trunk that establishes a foundation for downstream analytics
Domain-specific models (e.g., RAG) act as the branches that rely on the base model (i.e., the trunk) to provide process- or function-specific capabilities that can span a number of end-user applications, but have specific, targeted outcomes in mind
A “micro”-model is created when specific branches of the tree are deployed to an end-user based on their profile. This represents the subset that is relevant to that data consumer given their role, permissions, experience level, etc.
The data available at the end point (e.g., mobile device) then provides the leaves that populate the branches of the “micro”-models that have been deployed to create an adaptive model used to inform the end user and drive meaningful and productive action.
The adaptive model should also take into account user preferences (via customization options) and personalization to tune their experience as closely as possible to what they need and how they work.
In this way, the progression of models moves from general to very specific, end-user focused solutions that are contextualized with real-time data much the same as the navigation example above.
It is also worth noting that, in addition to delivering these capabilities, the mobile device (or endpoint) may collect and send data back to further inform and train the knowledge models by domain (e.g., process performance data) and potentially develop additional branches based on gaps that may surface in execution.
Applying the Model
Having set context on the overall approach, there are some notable differences from how these capabilities could create a different experience and level of productivity than today, namely:
Rather than delivering content and transactional capabilities based on an end-user’s role and persona(s), those capabilities would be deployed to a user’s device (the branches of the “micro”-model), but synthesized with other information (the “leaves”) like the user’s experience level, preferences, location, training needs, equipment information (in a manufacturing-type context), to generate an interface specific to them that continually evolves to optimize their individual productivity
As new capabilities (i.e., “branches”) are developed centrally, they could be deployed to targeted users and their individual experiences would adapt to incorporate in ways that work best for them and their given configuration, without having to relearn the underlying application(s)
Going Back to Navigation
On the last point above, a parallel example would be the introduction of weather information into navigation.
At least in Google Maps, while there are real-time elements like speed traps, traffic delays, and accidents factored into the application, there is currently no mechanism to recognize or warn end users about significant weather events that also may surface along the route. In practice, where severe weather is involved, this could represent safety risk to the traveler and, in the event that the model was adapted to include a “branch” for this kind of data, one would hope that the application would behave the same from an end-user standpoint, but with the additional capability integrated into the application.
Wrapping Up
Understanding that we’re still early in the exploration of how AI will change the way we work, I believe that defining a framework for how various types of models can integrate and work across purposes would enable significant value and productivity if designed effectively.
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
It’s impossible to scroll through a news feed and miss the energy surrounding AI and its potential to transform. The investment in technology as a strategic differentiator is encouraging to see, particularly as a person who thrives on change and innovation. It is, however, also concerning that the ways in which it is often described are reminiscent of other technology advances of the past… CRM, BigData, .com… where there was an immediate surge in spending without a clear set of outcomes in mind, operating approach, or business architecture established for how to leverage it effectively. Consequently, while a level of experimentation is always good in the interest of learning and exploring, a lot of money and time can be wasted (and technical debt created) without necessarily creating any meaningful business value through the process.
For the purposes of this article, I’m going to focus on five dimensions of AI and how I’m thinking about them:
Framing the Problem – Thinking about how AI will be used in practice
The Role of Compute – Considering the needs for processing moving forward
Revisiting Data Strategy – Putting AI in the context of the broader data landscape
Simplifying “Intelligence” – Exploring the end user impact of AI
Thinking About Multi-Cloud – Contemplating how to approach AI in a distributed environment
This topic is very extensive, so I’ll try to keep the thoughts at a relatively high-level to start and dive into more specifics in future articles as appropriate.
Framing the Problem
Considering the Range of Opportunities
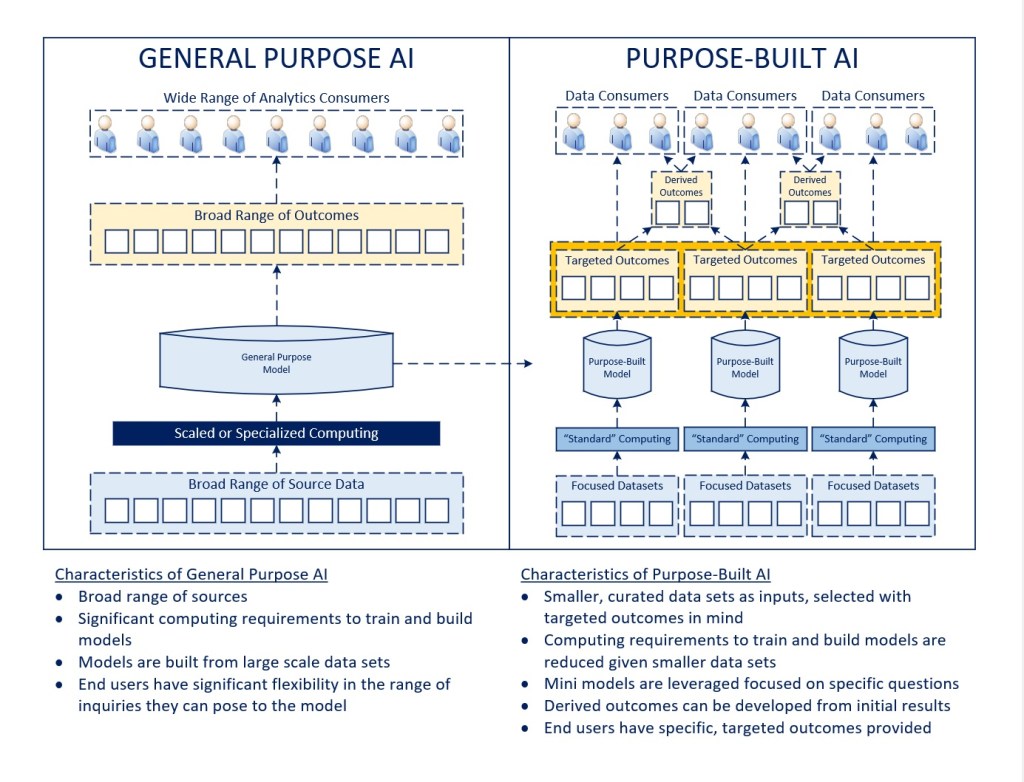
While a lot of the attention surrounding Generative AI over the last year has been focused on content generation for research, communication, software development, and other purposes, I believe the focus for how AI can create business value will shift substantially to be more outcome-driven and directed at specific business problems. In this environment, smaller, more focused data sets (e.g., incorporating process, market, equipment, end user, and environmental data) will be analyzed to understand causal relationships in the interest of producing desired business outcomes (e.g., optimizing process efficiency, improving risk management, increasing safety) and content (e.g., just in time training, adaptive user experiences). Retrieval-Augmented Generation (RAG) models are an example of this today, with a purpose-built model leveraging a foundational large language model to establish context for a more problem-specific solution.
This is not to suggest that general purpose models will decline in utility, but rather that I believe those applications will be better understood, mature, and become integrated where they create the most value (in relatively short order). The focus will then shift towards areas where more direct business value can be obtained through an evolution of these technologies.
For that to occur, the fundamentals of business process analysis need to regain some momentum to overcome the ‘silver bullet’ mentality that seems largely prevalent with these technologies today. It is, once again, a rush towards “the cool versus the useful” towards my opening remark about how current AI discussions feel a lot like conversations at the start of the .com era, and the sooner we shift towards a disciplined approach to leveraging these technology advancements, the better.
The opportunity will be to look at how we can leverage what these models provide, in terms of understanding multi-dimensional relationships across large sets of data, but then extending the concept to become more deterministic in terms of what decisions under a given set of conditions are most likely to bring about desired outcomes (i.e., causal models). This is not where we are today, but is where I believe these technologies are meant to go in the near future. Ultimately, we don’t just want to produce content, we want to influence processes and business results with support from artificial intelligence.
As purpose-built models evolve, I believe there will be a base set of business insights that are made available across communities of end users, and then an emergence of secondary insights that are developed in a derivative fashion. In this way, rather than try to summit Mount Everest in a direct ascent, we will establish one of more layers of outcomes (analogous to having multiple base camps) that facilitate the eventual goal.
Takeaways
General purpose AI and large language models (LLMs) will continue to be important and become integrated with how we work and consume technology, but reach a plateau of usefulness fairly rapidly in the next year or so
Focus will shift towards integrating transactional, contextual, and process data with the intention of predicting business outcomes (causal AI) in a much more targeted way
The overall mindset will pivot from models that do everything to ones that do something much more specific, with a desired outcome in mind up front
The Role of Compute
Considering the Spectrum of Needs
Having set the context of general versus purpose-built AI and the desire to move from content to more outcome-focused intelligence, the question is what this means for computing. There is a significant amount of attention going to specialized processors (e.g., GPUs) at the moment, with the presumption that there are significant computing requirements to generate models based on large sets of data in a reasonable amount of time. That being said, while content-focused outcomes may be based on a large volume of data and only need to be refreshed on a periodic basis, the more we want AI to assist in the performance of day-to-day tasks, the more we need the insights to be produced on a near-real time basis and available on a mobile device or embedded on a piece of digital equipment.
Said differently, as our focus shifts to smaller and more specific business problems, so should the data sets involved, making it possible to develop purpose-built models on more “standard” computing platforms that are commercially available, where the models are refreshed on a more frequent basis, taking into account relevant environmental conditions, whether that’s production plans or equipment status in manufacturing, market conditions in financial services, or weather patterns or other risk factors in insurance.
The Argument for a “Micro-Model”
Assuming a purpose-built model can be developed with a particular business outcome or process in mind, where things could take an interesting leap forward would be extending those models into edge computing environments, like a digital worker in a manufacturing facility, where the specific end user knowledge and skills, geo-location, environmental conditions, equipment status could be fed into a purpose-built model and then extended to create a more adaptive model that provides a user-specific set of insights and instructions to drive productivity, safety, and effectiveness.
Ultimately, AI needs to be focused on the individual and run on something as accessible as a mobile device to truly realize it’s potential. The same would also be true for extending models that could be embedded within a piece of industrial equipment to run as part of a digital facility. That is beyond anything we can do today, it makes insights personalized and specific to an individual, and that concept holds a significant amount more business value than targeting a specific user group or persona from an application development standpoint. Said differently, the concept is similar to integrating personalization, workflow, presentation, and insights into one integrated technology.
With this in mind, perhaps the answer will ultimately still result in highly specialized computing, but before rushing in the direction of quantum computing and buying a significant number of GPUs, I’d definitely consider the ultimate outcome we want, which is to put the power of insights in the hands of end users in day-to-day activities, but being much more effective in what they are able to do. That is not a once-a-month refresh of a massive amount of data. It is a constantly evolving model that is based on learnings from the past, but the current realities and conditions of the moment and the specific individual taking action on those things.
Takeaways
Computing requirements will shift from centralized processing of large data volumes to smaller, curated data sets that are refreshed more often and targeted to specific business goals
Ultimately, the goal should be to enable end users with a highly personalized model that is focused on them, the tasks they need to accomplish, and the current conditions under which they are operating
Processing for artificial intelligence will therefore be distributed across a spectrum of environments from large scale centralized methods to distributed edge appliances and mobile devices
Revisiting Data Strategy
Business Implications of AI
The largest risk with artificial intelligence that I see today is no different than anything else in regards to data: the value of new technology is only as good as the underlying data quality, and that’s a business issue (for the most part).
Said differently, in the case of AI, if the underlying data sets upon which models are developed has data quality issues and there is a lack of data management and data governance in place, the inferences drawn will likely be of limited value.
Ultimately, the more we move from general purpose to purpose-built solutions, the ability to identify relevant and necessary data to be incorporated into a model can be a significant accelerator of value. This is because the “give me all the data” approach would likely both increase time to develop and produce models as well as introduce significant overhead in ensuring data quality and governance to confirm the usefulness of the resulting models.
If, as an example, I wanted to use AI to ingest all the training materials developed across a set of manufacturing facilities in the interest of synthesizing, standardizing, and optimizing them across an enterprise, the underlying quality of those materials becomes critically important in deriving the right outcomes. There may be out of date procedures, unique steps specific to a location, quality issues in some of the source content, etc. The technology itself doesn’t solve these issues. Arguably, a level of data wrangling or quality tools could be helpful in identifying and surfacing these issues, but the point is that data governance and curation are required before the infrastructure would produce the desired business outcomes.
Technology Implications of AI
As the diagram intends to indicate, whether AI lives as a set of intelligent agents that run as separate stove pipes in parallel with existing applications and data solutions, the direction for how things will evolve is an important element of data strategy to consider, particularly in a multi-cloud environment (something I’ll address in the final section).
As discussed in The Intelligent Enterprise, I believe that the eventual direction for AI (as we already see somewhat evidenced with Copilot in Microsoft Office 365), is to move from separate agents and data apps (“intelligent agents”) to having those capabilities integrated into the workflow of applications themselves (making them “intelligent applications”), where they can create the most overall value.
What this suggests to me is that transaction data from applications will make its way into models, and be exposed back into consuming applications via AI services. Whether the data ultimately moves into a common repository that can handle both the graph and relational data within the same data solution remains to be seen, but having personally developed an integrated object- and relational-database for a commercial software package thirty years ago at the start of my career, I can foresee that there may be benefits in thinking through the value of that kind of solution.
Where things get more complicated on an enterprise level is when you scale these concepts out. I will address the end user and multi-cloud aspects of this in the next two sections, but it’s critically important in data strategy to consider how too many point solutions in the AI domain could significantly increase cost and complexity (not to mention have negative quality consequences). As data sets and insights are meant to extend outside an individual application to cross-application and cross-ecosystem levels, the ways in which that data is stored, accessed, and exposed likely will become significant. My article on Perspective on Impact-Driven Analytics attempted to establish a layered approach to how to think about the data landscape, from production to consumption, that may provide a starting point for evaluating alternatives in this regard.
Takeaways
While AI provides new technology capabilities, business ownership / stewardship of data and the processes surrounding data quality, data management, and data governance are extremely critical in an AI-enabled world
As AI capabilities move within applications, the need to look across applications for additional insights and optimization opportunities will emerge. To the extent that can be designed and architected in a consistent approach, it will be significantly more cost-effective and create more value over time at an enterprise level
Experimentation is appropriate in the AI domain for the foreseeable future, but it is important to consider how these capabilities will ultimately become integrated with the application and data ecosystems in medium to larger organizations in the interest of getting the most long-term value from the investments
Simplifying “Intelligence”
Avoiding the Pitfalls of Introducing New Technologies to End Users
The diagram above is meant to help conceptualize what could ultimately occur if AI capabilities are introduced as various data apps or intelligent agents, running separate from applications versus becoming an integrated part of the way intelligent applications behave over time.
At an overall level, expecting users to arbitrate new capabilities without integrating them thoughtfully into the workflow and footprint that exists creates the conditions for significant change management and productivity issues. This is always true when introducing change, but the expectations associated with the disruptive potential of AI (at the moment) are quite high, and that could set the stage for disappointment if there isn’t a thoughtful design in place for how the solutions are meant to make the consumer more effective on a workflow and task level.
Takeaways
Intelligence capabilities will move inside applications rather than be adjacent to them, providing more of a “guided path” approach to end users
To the degree that “micro-models” are eventually in place, that could include making the presentation layer of applications personalized to the individual user based on their profile, experience level, role, and operating conditions
The role of “Intelligent Agents” will take on a higher-level, cross-application focus, which could be (as an example) optimizing notifications and alerts coming from various applications to a more thoughtful set of prioritized actions intended to maximize individual performance
Thinking About Multi-Cloud
Working Across Environments
With the introduction of AI capabilities at an enterprise level, the challenge becomes how to leverage and integrate these technologies, particularly given that data may exist across a number of hosted and cloud-based environments. For simplicity’s sake, I’m going to assume that any cloud capability required for data management and AI services can be extended to the edge (via containers), though that may not be fully true today.
At an overall level, as it becomes desirable to extend models to include data resident both in something like Microsoft Office 365 (running on Azure) and corporate transactional data (largely running in AWS if you look at market share today), the considerations and costs for moving data between platforms could be significant if not architected in a purposeful manner.
To that end, my suggestion is to look at business needs in one of three ways:
Those that can be addressed via a single cloud platform, in which case it would likely be appropriate to design and deliver solutions leveraging the AI capabilities available natively on that platform
To the extent a solution extends across multiple providers, it may be possible to look at layering the solutions such that each cloud platform performs a subset of the analysis, resulting in pre-processed data that could then be published to a centralized, enterprise cloud environment where the various data sets are pulled into a single enterprise model that is used to address the overall need
If a partitioning approach isn’t possible, then some level of cost, capability, and performance analysis would likely make sense to determine where data should reside to enable the necessary integrated models to be developed
Again, the point is to step back from individual solutions and projects to consider the enterprise strategy for how data will be managed, models will be developed, and deployed overall. The alternative approach of deploying too many point solutions could lead to considerable cost and complexity (i.e., technical debt) over time.
Takeaways
AI capabilities are already available on all the major cloud platforms. I believe they will reach relative parity from a capability standpoint in the foreseeable future, to the point that they shouldn’t be a primary consideration in how data and models are managed and deployed
The more the environment can be designed with standards in mind, modularity, integration, interoperability, and a level of composability, the better. Technology solutions will continue to be introduced that an organization will want to leverage without having to abandon or migrate everything that is already in place
It is extremely probably that AI models will be deployed across cloud platforms, so having a deliberate strategy for how to manage and facilitate this should be given consideration
A lack of overall multi-cloud strategy will likely create complexity and cost that may be difficult to unwind over time
Wrapping Up
If you’ve made it this far, thank you for taking the time, hopefully some of the concepts were thought provoking. In Excellence by Design, I talk about ‘Relentless Innovation’…
Admittedly, there is so much movement in this space, that it’s very possible some of what I’ve written is obsolete, obvious, far-fetched, or some combination of all of the above, but that’s also part of the point of sharing the ideas: to encourage the dialogue. My experience in technology over the last thirty-two years, especially with emerging capabilities like artificial intelligence, is that we can lose perspective on value creation in the rush to adopt something new and the tool becomes a proverbial hammer in search of a nail.
What would be far better is to envision a desired end state, identify what we’d really like to be able to do from a business capability standpoint, and then endeavor to make that happen with advanced technology. I do believe there is significant power in these capabilities for the organizations that leverage them effectively.
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
Having covered a couple future-oriented topics on Transforming Manufacturing and The Future of IT, I thought it would good to come back to where we are with Enterprise Architecture as a critical function for promoting excellence in IT.
Overall, there is a critical balance to be struck in technology strategy today: technology-driven capabilities are advancing faster than any organization can reasonably adopt and integrate them (as is the exposure in cyber security), even if you could, the change management issues you’d cause on end users would be highly disruptive, and thereby undermine your desired business outcomes, and, in practice rapidly evolving, sustainable change is the goal, not any one particular “implementation” of the latest thing. This is what Relentless Innovation is about, referenced in my article on Excellence by Design.
Connecting Architecture back to Strategy
In the article, Creating Value Through Strategy, I laid out a framework for thinking about IT strategy at an overall level that can be used to create some focal points for enterprise architecture efforts in practice, namely:
Innovate – leveraging technology advancements in ways that promote competitive advantage
Accelerate – increasing speed to market/value to be more responsive to changing needs
Optimize – improving the value/cost ratio to drive return on technology investments overall
Inspire – creating a workplace that promotes retention and enables the above objectives
Perform – ensuring reliability, security, and performance in the production environment
The remainder of this article will focus on how enterprise architecture (EA) plays a role in enabling each of these dimensions given the pace of change today.
Breaking it Down
Innovate
Adopting new technologies for maximum business advantage is certainly the desired end game in this dimension, but unless there is a very unique, one-off situation, the role of EA is fairly critical in making these advancements leverageable, scalable, and sustainable. It’s worth noting, by the way, that I’m specifically referring to “enterprise architecture” here, not “solution architecture”, which I would consider to be the architecture and design of a specific business solution. One should not exist without the other and, to the degree that solution architecture is emphasized without a governing enterprise architecture framework in place, the probability of significant technical debt, delivery issues, lack of reliability, and a host of other issues will skyrocket.
Where EA plays a role in promoting innovation is minimally in exploring market trends and looking for enabling technologies that can promote competitive advantage, but also, and very critically in establishing the standards and guidelines by which new technologies should be introduced and integrated into the existing environment.
Using a “modern” example, I’ve seen a number of articles of late on the role of GenAI in “replacing” or “disrupting” application development, from the low-code/no code type solutions to the SaaS/package software domain, to everywhere. While this sounds great in theory, it shouldn’t take long for the enterprise architecture questions to surface:
How do I integrate that accumulated set of “point solutions” in any standard way?
How do I meaningfully run analytics on the data associated with these applications?
How do I secure these applications in a way that I’m not exposed to vulnerabilities that I would with any open-source technology (i.e., they are generated by an engine that may have inherent security gaps)?
How do I manage the interoperability between these internally-developed/generated solutions and standard packages (ERP, CRM, etc.) that are likely a core part of any sizeable IT environment?
In the above example, even if I find way to replace existing low-code/no code solutions with a new technology, it doesn’t mean that I don’t have the same challenges as exist with leveraging those technologies today.
In the case of innovation, the highest priorities for EA are therefore: looking for new disruptive technologies in the market, defining standards to enable their effective introduction and use, and then governing that delivery process to ensure standards are followed in practice.
Accelerate
Speed to market is a pressing reality in any environment I’ve seen, though it can lead to negative consequences as I discussed in Fast and Cheap… Isn’t Good. Certainly, one of the largest barriers to speed is complexity, and complexity can come in many forms depending on the makeup of the overall IT landscape, the standards, processes, and governance in place related to delivery, and the diversity in solutions, tools, and technologies that are involved in the ecosystem as a whole.
While I talk about standards, reuse, and governance in the broader article on IT strategy, I would argue that the largest priority for EA in terms of accelerating delivery is in rationalization of solutions, tools, and technologies in use overall.
The more diverse the enterprise ecosystem is, the more difficult it becomes to add, replace, or integrate new solutions over time, and ultimately this will slow delivery efforts down to a snail’s pace (not to mention making them much more expensive and higher risk over time).
Using an example of a company that has performed many acquisitions over time, looking for opportunities to simplify and standardize core systems (e.g., moving to a single ERP versus having multiple instances and running consolidations through a separate tool) can lead to significant reduction in complexity over time, not to mention making it possible to redeploy resources to new capability development versus being spread across multiple redundant production solutions.
Optimize
In the case of increasing the value/cost ratio, the ability to rationalize tools and solutions should definitely lead to reduced cost of ownership (beyond the delivery benefit mentioned above), but the largest priority should be in identifying ways to modernize on a continual basis.
Again, in my experience, modernization is difficult to prioritize and fund until there is an end-of-life or end-of-support scenario, at which point it becomes a “must do” priority, and causes a significant amount of delivery disruption in the process.
What I believe is a much better and healthier approach to modernization is a more disciplined, thoughtful approach that is akin to “urban renewal”, where there is an annual allocation of work directed at modernization on a prioritized basis (the criteria for which should be established through EA, given an understanding of other business demand), such that significant “events” are mitigated and it becomes a way of working on a sustained basis. In this way, the delineation between “keep the lights on” (KTLO) support, maintenance (which is where modernization efforts belong), and enhancement/ build-related work is important. In my experience, that second maintenance bucket is too often lumped into KTLO work, it is underserved/underfunded, and ultimately that creates periodic crises in IT to remediate things that should’ve been addressed far sooner (as a much lower cost) if a more disciplined portfolio management strategy was in place.
Inspire
In the interest of supporting the above objectives, having the right culture and skills to support ongoing evolution is imperative. To that end, the role of EA should be in helping to inform and guide the core skills needed to “lean forward” into advanced technology, while maintaining the right level of competency to support the footprint in place.
Again, this is where having a focus on modernization can help, as it creates a means to sunset legacy tools and technologies, to enable that continuous evolution of the skills the organization needs to operate (whether internally or externally sourced).
Perform
Finally, the role of EA in the production setting could be more or less difficult depending on how well the above capabilities are defined and supported in an enterprise. To the degree standards, rationalization, modernization, and the right culture and skills are in place, the role of EA would be helping to “tune” the environment to perform better and at a lower cost to operate.
Where there is a priority need for EA is ensuring there is an integrated approach to cyber security that aligns to development processes (e.g., DevSecOps) and a comprehensive, integrated strategy to monitor and manage performance in the production environment so that production incidents (using ITIL-speak) can be minimized and mitigated to the maximum degree possible.
Wrapping Up
Looking back on the various dimensions and priorities outlined above in relation to the role of EA, perhaps there isn’t much that I can argue is very different than what the role entailed five or ten years ago… establish standards, simplify / rationalize, modernize, retool, govern… that being said, the pace at which these things need to be accomplished and the criticality of doing them well is more important than ever with the increasing role technology plays in the digital enterprise. Like other dimensions required to establish excellence in IT, courageous leadership is where this needs to start, because it takes discipline to do things “right” while still doing them at a pace and with an agility that discerns the things that matter to an enterprise versus those that are simply ivory tower thinking.
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
I’ve been thinking about writing this article for a while, with the premise of “what does IT look like in the future?” In a digital economy, the role of technology in The Intelligent Enterprise will certainly continue to be creating value and competitive business advantage. That being said, one can reasonably assume a few things that are true today for medium to large organizations will continue to be part of that reality as well, namely:
The technology footprint will be complex and heterogenous in its makeup. To the degree that there is a history of acquisitions, even more so
Cost will always be a concern, especially to the degree it exceeds value delivered (this is explored in my article on Optimizing the Value of IT)
Agility will be important in adopting and integrating new capabilities rapidly, especially given the rate of technology advancement only appears to be accelerating over time
Talent management will be complex given the variety of technologies present will be highly diverse (something I’ve started to address in my Workforce and Sourcing Strategy Overview article)
My hope is to provide some perspective in this article on where I believe things will ultimately move in technology, in the underlying makeup of the footprint itself, how we apply capabilities against it, and how to think about moving from our current reality to that environment. Certainly, all of the five dimensions of what I outlined in my article on Creating Value Through Strategy will continue to apply at an overall strategy level (four of which are referenced in the bullet points above).
A Note on My Selfish Bias…
Before diving further into the topic at hand, I want to acknowledge that I am coming from a place where I love software development and the process surrounding it. I taught myself to program in the third grade (in Apple Basic), got my degree in Computer Science, started as a software engineer, and taught myself Java and .Net for fun years after I stopped writing code as part of my “day job”. I love the creative process for conceptualizing a problem, taking a blank sheet of paper (or white board), designing a solution, pulling up a keyboard, putting on some loud music, shutting out distractions, and ultimately having technology that solves that problem. It is a very fun and rewarding thing to explore those boundaries of what’s possible and balance the creative aspects of conceptual design with the practical realities and physical constraints of technology development.
All that being said, insofar as this article is concerned, when we conceptualize the future of IT, I wanted to put a foundational position statement forward to frame where I’m going from here, which is:
Just because something is cool and I can do it, doesn’t mean I should.
That is a very difficult thing to internalize for those of us who live and breathe technology professionally. Pride of authorship is a real thing and, if we’re to embrace the possibilities of a more capable future, we need to apply our energies in the right way to maximize the value we want to create in what we do.
The Producer/Consumer Model
Where the Challenge Exists Today
The fundamental problem I see in technology as a whole today (I realize I’m generalizing here) is that we tend to want to be good at everything, build too much, customize more than we should, and throw caution to the wind when it comes to things like standards and governance as inconveniences that slow us down in the “deliver now” environment in which we generally operate (see my article Fast and Cheap, Isn’t Good for more on this point).
Where that leaves us is bloated, heavy, expensive, and slow… and it’s not good. For all of our good intentions, IT doesn’t always have the best reputation for understanding, articulating, or delivering value in business terms and, in quite a lot of situations I’ve seen over the years, our delivery story can be marred with issues that don’t create a lot of confidence when the next big idea comes along and we want to capitalize on the opportunity it presents.
I’m being relatively negative on purpose here, but the point is to start with the humility of acknowledging the situation that exists in a lot of medium to large IT environments, because charting a path to the future requires a willingness to accept that reality and to create sustainable change in its place. The good news, from my experience, is there is one thing going for most IT organizations I’ve seen that can be a critical element in pivoting to where we need to be: a strong sense of ownership. That ownership may show up as frustration in the status quo depending on the organization itself, but I’ve rarely seen an IT environment where the practitioners themselves don’t feel ownership for the solutions they build, maintain, and operate or have a latent desire to make them better. There may be a lack of a strategy or commitment to change in many organizations, but the underlying potential to improve is there, and that’s a very good thing if capitalized upon.
Challenging the Status Quo
Pivoting to the future state has to start with a few critical questions:
Where does IT create value for the organization?
Which of those capabilities are available through commercially available solutions?
To what degree are “differentiated” capabilities or features truly creating value? Are they exceptions or the norm?
Using an example from the past, a delivery team was charged with solving a set of business problems that they routinely addressed through custom solutions, even though the same capabilities could be accomplished through integration of one or more commercially available technologies. From an internal standpoint, the team promoted the idea that they had a rapid delivery process, were highly responsive to the business needs they were meant to address, etc. The problem is that the custom approach actually cost more money to develop, maintain, and support, was considerably more difficult to scale. Given solutions were also continually developed with a lack of standards, their ability to adopt or integrate any new technologies available on the market was non-existent. Those situations inevitably led to new custom solutions and the costs of ownership skyrocketed over time.
This situation begs the question: if it’s possible to deliver equivalent business capability without building anything “in house”, why not do just that?
In the proverbial “buy versus build” argument, these are the reasons I believe it is valid to ultimately build a solution:
There is nothing commercially available that provides the capability at a reasonable cost
I’m referencing cost here, but it’s critical to understand the TCO implications of building and maintaining a solution over time. They are very often underestimated.
There is a commercially available solution that can provide the capability, but something about privacy, IP, confidentiality, security, or compliance-related concerns makes that solution infeasible in a way that contractual terms can’t address
I mention contracting purposefully here, because I’ve seen viable solutions eliminated from consideration over a lack of willingness to contract effectively, and that seems suboptimal by comparison with the cost of building alternative solutions instead
Ultimately, we create value in business capability enabled through technology, “who” built them doesn’t matter.
Rethinking the Model
My assertion is that we will obtain the most value and acceleration of business capabilities when we shift towards a producer/consumer model in technology as a whole.
What that suggests is that “corporate IT” largely adopts the mindset of the consumer of technologies (specifically services or components) developed by producers focused purely on building configurable, leverageable components that can be integrated in compelling ways into a connected ecosystem (or enterprise) of the future.
What corporate IT “produces” should be limited to differentiated capabilities that are not commercially available, and a limited set of foundational capabilities that will be outlined below. By trying to produce less and thinking more as a consumer, this should shift the focus internally towards how technology can more effectively enable business capability and innovation and externally towards understanding, evaluating, and selecting from the best-of-breed capabilities in the market that help deliver on those business needs.
The implication, of course for those focused on custom development, would be to move towards those differentiated capabilities or entirely towards the producer side (in a product-focused environment), which honestly could be more satisfying than corporate IT can be for those with a strong development inclination.
The cumulative effect of these adjustments should lead to an influx of talent into the product community, an associated expansion of available advanced capabilities in the market, and an accelerated ability to eventually adopt and integrate those components in the corporate environment (assuming the right infrastructure is then in place), creating more business value than is currently possible where everyone tries to do too much and sub-optimizes their collective potential.
Learning from the Evolution of Infrastructure
The Infrastructure Journey
You don’t need to look very far back in time to remember when the role of a CTO was largely focused on managing data centers and infrastructure in an internally hosted environment. Along the way, third parties emerged to provide hosting services and alleviate the need to be concerned with routine maintenance, patching, and upgrades. Then converged infrastructure and the software-defined data center provided opportunities to consolidate and optimize that footprint and manage cost more effectively. With the rapid evolution of public and private cloud offerings, the arguments for managing much of your own infrastructure beyond those related specifically to compliance or legal concerns are very limited and the trajectory of edge computing environments is still evolving fairly rapidly as specialized computing resources and appliances are developed. The learning being: it’s not what you manage in house that matters, it’s the services you provide relative to security, availability, scalability, and performance.
Ok, so what happens when we apply this conceptual model to data and applications? What if we were to become a consumer of services in these domains as well? The good news is that this journey is already underway, the question is how far we should take things in the interest of optimizing the value of IT within an organization.
The Path for Data and Analytics
In the case of data, I think about this area in two primary dimensions:
How we store, manage, and expose data
How we apply capabilities to that data and consume it
In terms of storage, the shift from hosted data to cloud-based solutions is already underway in many organizations. The key levers continue to be ensuring data quality and governance, finding ways to minimize data movement and optimize data sharing (while facilitating near real-time analytics), and establishing means to expose data in standard ways (e.g., virtualization) that enable downstream analytic capabilities and consumption methods to scale and work consistently across an enterprise. Certainly, the cost of ingress and egress of data across environments is a key consideration, especially where SaaS/PaaS solutions are concerned. Another opportunity continues to be the money wasted on building data lakes (beyond archival and unstructured data needs) when viable platform solutions in that space are available. From my perspective, the less time and resources spent on moving and storing data to no business benefit, the more energy that can be applied to exposing, analyzing, and consuming that data in ways that create actual value. Simply said, we don’t create value in how or where we store data, we create value in how consume it.
On the consumption side, having a standards-based environment with a consistent method for exposing data and enabling integration will lend itself well to tapping into the ever-expanding range of analytical tools on the market, as well as swapping out one technology for another as those tools continue to evolve and advance in their capabilities over time. The other major pivot being to minimize the amount of “traditional” analytical reporting and business intelligence solutions to more dynamic data apps that leverage AI to inform meaningful end-user actions, whether that’s for internal or external users of systems. Compliance-related needs aside, at an overall level, the primary goal of analytics should be informed action, not administrivia.
The Shift In Applications
The challenge in the applications environment is arbitrating the balance between monolithic (“all in”) solutions, like ERPs, and a fully distributed component-based environment that requires potentially significant management and coordination from an IT standpoint.
Conceptually, for smaller organizations, where the core applications (like an ERP suite + CRM solution) represent the majority of the overall footprint and there aren’t a significant number of specialized applications that must interoperate with them, it likely would be appropriate and effective to standardize based on those solutions, their data model, and integration technologies.
On the other hand, the more diverse and complex the underlying footprint is for a medium- to large-size organization, there is value in looking at ways to decompose these relatively monolithic environments to provide interoperability across solutions, enable rapid integration of new capabilities into a best-of-breed ecosystem, and facilitate analytics that span multiple platforms in ways that would be difficult, costly, or impossible to do within any one or two given solutions. What that translates to, in my mind, is an eventual decline of the monolithic ERP-centric environment to more of a service-driven ecosystem where individually configured capabilities are orchestrated through data and integration standards with components provided by various producers in the market. That doesn’t necessarily align to the product strategies of individual companies trying to grow through complementary vertical or horizontal solutions, but I would argue those products should create value at an individual component level and be configurable such that swapping out one component of a larger ecosystem should still be feasible without having to abandon the other products in that application suite (that may individually be best-of-breed) as well.
Whether shifting from a highly insourced to a highly outsourced/consumption-based model for data and applications will be feasible remains to be seen, but there was certainly a time not that long ago when hosting a substantial portion of an organization’s infrastructure footprint in the public cloud was a cultural challenge. Moving up the technology stack from the infrastructure layer to data and applications seems like a logical extension of that mindset, placing emphasis on capabilities provided and value delivered versus assets created over time.
Defining Critical Capabilities
Own Only What is Essential
Making an argument to shift to a consumption-oriented mindset in technology doesn’t mean there isn’t value in “owning” anything, rather it’s meant to be a call to evaluate and challenge assumptions related to where IT creates differentiated value and to apply our energies towards those things. What can be leveraged, configured, and orchestrated, I would buy and use. What should be built? Capabilities that are truly unique, create competitive advantage, can’t be sourced in the market overall, and that create a unified experience for end users. On the final point, I believe that shifting to a disaggregated applications environment could create complexity for end users in navigating end-to-end processes in intuitive ways, especially to the degree that data apps and integrated intelligence becomes a common way of working. To that end, building end user experiences that can leverage underlying capabilities provided by third parties feels like a thoughtful balance between a largely outsourced application environment and a highly effective and productive individual consumer of technology.
Recognize Orchestration is King
Workflow and business process management is not a new concept in the integration space, but it’s been elusive (in my experience) for many years for a number of reasons. What is clear at this point is that, with the rapid expansion in technology capabilities continuing to hit the market, our ability to synthesize a connected ecosystem that blends these unique technologies with existing core systems is critical. The more we can do this in consistent ways, the more we shift towards a configurable and dynamic environment that is framework-driven, the more business flexibility and agility we will provide… and that translates to innovation and competitive advantage over time. Orchestration is a critical piece of deciding which processes are critical enough that they shouldn’t be relegated to the internal workings of a platform solution or ERP, but taken in-house, mapped out, and coordinated with the intention of creating differentiated value that can be measured, evaluated, and optimized over time. Clearly the scalability and performance of this component is critical, especially to the degree there is a significant amount of activity being managed through this infrastructure, but I believe the transparency, agility, and control afforded in this kind of environment would greatly outweigh the complexity involved in its implementation.
Put Integration in the Center
In a service-driven environment, clearly the infrastructure for integration, streaming in particular, along with enabling a publish and subscribe model for event-driven processing, will be critical for high-priority enterprise transactions. The challenge in integration conversations in my experience tends to be defining the transactions that “matter”, in terms of facilitating interoperability and reuse, and those that are suitable for point-to-point, one off connections. There is ultimately a cost for reuse when you try to scale, and there is discipline needed to arbitrate those decisions to ensure they are appropriate to business needs.
Reassess Your Applications/Services
With any medium to large organization, there is likely technology sprawl to be addressed, particularly if there is a material level of custom development (because component boundaries likely won’t be well architected) and acquired technology (because of the duplication it can cause in solutions and instances of solutions) in the landscape. Another complicating factor could be the diversity of technologies and architectures in place, depending on whether or not a disciplined modernization effort exists, the level of architecture governance in place, and rate and means by which new technologies are introduced into the environment. All of these factors call for a thoughtful portfolio strategy, to identify critical business capabilities and ensure the technology solutions meant to enable them are modern, configurable, rationalized, and integrated effectively from an enterprise perspective.
Leverage Data and Insights, Then Optimize
With analytics and insights being a critical capability to differentiated business performance, an effective data governance program with business stewardship, selecting the right core, standard data sets to enable purposeful, actionable analytics, and process performance data associated with orchestrated workflows are critical components of any future IT infrastructure. This is not all data, it’s the subset that creates significant business value to justify the investment in making it actionable. As process performance data is gathered through the orchestration approach, analytics can be performed to look for opportunities to evolve processes, configurations, rules, and other characteristics of the environment based on key business metrics to improve performance over time.
Monitor and Manage
With the expansion of technologies and components, internal and external to the enterprise environment, having the ability to monitor and detect issues, proactively take action, and mitigate performance, security, or availability issues will become increasingly important. Today’s tools are too fragmented and siloed to achieve the level of holistic understanding that is needed between hosted and cloud-based environments, including internal and external security threats in the process.
Secure “Everything”
While zero trust and vulnerability management risk is expanding at a rate that exceeds an organization’s ability to mitigate it, treating security as a fundamental requirement of current and future IT environments is a given. The development of a purposeful cyber strategy, prioritizing areas for tooling and governance effectively, and continuing to evolve and adapt that infrastructure will be core to the DNA of operating successfully in any organization. Security is not a nice to have, it’s a requirement.
The Role of Standards and Governance
What makes the framework-driven environment of the future work is ultimately having meaningful standards and governance, particularly for data and integration, but extending into application and data architecture, along with how those environments are constructed and layered to facilitate evolution and change over time. Excellence takes discipline and, while that may require some additional investment in cost and time during the initial and ongoing stages of delivery, it will easily pay itself off in business agility, operating cost/ cost of ownership, and risk/exposure to cyber incidents over time.
The Lending Example
Having spent time a number of years ago understanding and developing strategy in the consumer lending domain, the similarities in process between direct and indirect lending, prime and specialty / sub-prime, from simple products like credit card to more complex ones like mortgage is difficult to ignore. That being said, it isn’t unusual for systems to exist in a fairly siloed manner, from application to booking, from document preparation, into the servicing process itself.
What’s interesting, from my perspective, is where the differentiation actually exists across these product sets: in the rules and workflow being applied across them, while the underlying functions themselves are relatively the same. As an example, one thing that differentiates a lender is their risk management policy, not necessarily the tool they use to assess to implement their underwriting rules or scoring models per se. Similarly, whether pulling a credit score is part of the front end of the process in something like credit card and an intermediate step in education lending, having a configurable workflow engine could enable origination across a diverse product set with essentially the same back-end capabilities and likely at a lower operating cost.
So why does it matter? Well, to the degree that the focus shifts from developing core components that implement relatively commoditized capability to the rules and processes that enable various products to be delivered to end consumers, the speed with which products can be developed, enhanced, modified, and deployed should be significantly improved.
Ok, Sounds Great, But Now What?
It Starts with Culture
At the end of the day, even the best designed solutions come down to culture. As I mentioned above, excellence takes discipline and, at times, patience and thoughtfulness that seems to contradict the speed with which we want to operate from a technology (and business) standpoint. That being said, given the challenges that ultimately arise when you operate without the right standards, discipline, and governance, the outcome is well worth the associated investments. This is why I placed courageous leadership as the first pillar in the five dimensions outlined in my article on Excellence by Design. Leadership is critical and, without it, everything else becomes much more difficult to accomplish.
Exploring the Right Operating Model
Once a strategy is established to define the desired future state and a culture to promote change and evolution is in place, looking at how to organize around managing that change is worth consideration. I don’t necessarily believe in “all in” operating approaches, whether it is a plan/build/run, product-based orientation, or some other relatively established model. I do believe that, given leadership and adaptability are critically needed for transformational change, looking at how the organization is aligned to maintaining and operating the legacy environment versus enabling establishment and transition to the future environment is something to explore. As an example, rather than assuming a pure product-based orientation, which could mushroom into a bloated organization design where not all leaders are well suited to manage change effectively, I’d consider organizing around a defined set of “transformation teams” that operate in a product-oriented/iterative model, but basically take on the scope of pieces of the technology environment, re-orient, optimize, modernize, and align them to the future operating model, then transition those working assets to different leaders that maintain or manage those solutions in the interest of moving to the next set of transformation targets. This should be done in concert with looking for ways to establish “common components” teams (where infrastructure like cloud platform enablement can be a component as well) that are driven to produce core, reusable services or assets that can be consumed in the interest of ultimately accelerating delivery and enabling wider adoption of the future operating model for IT.
Managing Transition
One of the consistent challenges with any kind of transformative change is moving between what is likely a very diverse, heterogenous environment to one that is standards-based, governed, and relatively optimized. While it’s tempting to take on too much scope and ultimately undermine the aspirations of change, I believe there is a balance to be struck in defining and establishing some core delivery capabilities that are part of the future infrastructure, but incrementally migrating individual capabilities into that future environment over time. This is another case where disciplined operations and disciplined delivery come into play so that changes are delivered consistently but also in a way that is sustainable and consistent with the desired future state.
Wrapping Up
While a certain level of evolution is guaranteed as part of working in technology, the primary question is whether we will define and shape that future or be continually reacting and responding to it. My belief is that we can, through a level of thoughtful planning and strategy, influence and shape the future environment to be one that enables rapid evolution as well as accelerated integration of best-of-breed capabilities at a pace and scale that is difficult to deliver today. Whether we’ll truly move to a full producer/consumer type environment that is service based, standardized, governed, orchestrated, fully secured, and optimized is unlikely, but falling short of excellence as an aspiration would still leave us in a considerably better place than where we are today… and it’s a journey worth making in my opinion.
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.