What It Is: Workforce and Sourcing Strategy is the long-term approach that an organization uses to provide the necessary skills, internal and external, to enable capabilities to deliver on business commitments and support the current and future technology footprint
Why It Matters: Having a deliberate and thoughtful strategy not only creates an agile and responsive workforce to meet ongoing and variable business demand, but also does so at the right cost. Where a defined strategy is not in place and being governed, there is very likely cost optimization opportunity
Key Concepts
Business and technology needs fluctuate. A strategy helps mitigate the cost impact of change
Leverage a competency model internally and externally to benchmark roles, capacity, and costs
Generally speaking, it’s better to align variable capacity to areas of variable demand
Benchmark internal cost of service against best-in-class providers, make adjustments as needed
Understand that not everything needs differentiated service, keep the lights on is valid in cases
Invest in areas where technology creates competitive advantage and IP, outsource elsewhere
Actively manage and govern talent development and performance to optimize productivity
Never assume HC = FTE. Used named resources for capacity planning of critical roles vs FTEs
Source where technology is emerging and immature to facilitate experiments and early learning
It is a reasonable strategy to engage partners in simplification efforts through mutual incentives
Never assume shifting sourcing to captives for arbitrage benefits is a 1:1 FTE exchange, it isn’t
Be mindful in how you manage overall tenure. Motivated inexperience introduces risk and cost
Leverage role-based capacity agreements to shift contract labor costs to a defined model
Scrutinize contracting heavily to avoid inflated cost. Convert or hire longer-term needs
Establish consistent contract language that aligns to service delivery roles and expectations
Define primary and secondary partners for individual sourcing needs, manage them consistently
Negotiate aggressively but fairly, “partnerships” produce more value than a “vendor” mentality
Benchmark and leverage consistent performance metrics across internal and external partners
Apply vendor management and governance processes to captives the same as external partners
Approach
Understand Current State – Benchmarking capacity by role across sources of staff, including cost
Determine What You Need – Evaluate business and industry trends, do the same for technology
Define Sourcing Approach – Identify critical skills to retain and source, and where to get them
Refine Talent Strategy – Clarify gaps between current and future IT staffing, skills and capacity
Develop Transition Plan – Plan change to talent pool and make explicit sourcing decisions
What It Is: With the advent of AI, the question ishow to integrate it effectively at an enterprise level. The long-term view should be a synthesis of applications, AI, and data, working in harmony, providing integrated capabilities that maximize effectiveness and productivity for the end users of technology
Why It Matters: Much like the .com era, there are lofty expectations of what AI can deliver without a fundamental strategy for how those capabilities will be integrated and leveraged at scale. Selecting the right approach that balances tactical gains with strategic infrastructure will be critical to optimizing and delivering differentiated value rapidly and consistently in a highly competitive business environment
Key Concepts
AI is a capability, not an end in itself. User-centered design is more important than ever
Resist the temptation to treat AI as a one-off and integrate it with existing portfolio processes
The end goal is to expose and harness all of an organization’s capabilities in a consistent way
Agentic solutions will become much more mainstream, along with orchestration of processes
The more agentic solutions become standard, the less application-specific front ends are needed
Natural language input will become common to reduce manual entry in various processes
We will shift from content via LLMs to optimizing processes and transactions via causal models
AI should help personalize solutions, reduce complexity, and improve productivity
Only a limited number of sidecar applications can be deployed before overwhelming end users
The less standardized the environment is, the longer it will take to achieve enterprise AI benefits
As with any transformation, don’t try to boil the ocean, have a strategy and migrate over time
Approach
Ensure architecture governance is in place quickly to avoid accruing significant technical debt
Design towards an enterprise architecture framework to enable rapid scaling and deployment
Migrate towards domain-based ecosystems to facilitate evolution and rapid scaling of capability
Enable rapid, disciplined, and governed experiments to explore tools and solution approaches
Place heavy emphasis on integration standards as a means to deploy new AI services with speed
Develop a conceptual “template” for how AI capabilities will be integrated to facilitate reuse
Organize AI services into insights (inform), agents (assist), and experts (benchmark, train, act)
Separate internal from package-provided AI services to provide agility and manage overall costs
Evaluate internal and external solutions by their ability to integrate services and enable agents
Reinforce data management and data governance processes to enable quality insights
Define roles and expectations for those in the organization who develop, use, and manage AI
What It Is: IT Value/Cost Optimization is the process of adjusting IT spend relative to the value being created through IT services in the interest of finding the optimal balance for an organization
Why It Matters: When organizations face financial challenges, there is often a desire to reduce expense. The challenge is that the activity is often managed as a cost cutting exercise focused on direct labor, without regard to other, less disruptive opportunities that exist if a more holistic approach was taken
Key Concepts
Optimization should be a continual activity. Doing it periodically increases negative impacts
The activity requires a clear understanding of costs (direct and indirect) and value being created
Where spending isn’t governed, it is likely inflated and suboptimized
The scale and complexity of a technology footprint has a direct relationship to labor cost
Direct labor should be the last lever adjusted. It represents the potential to create value
Every $1MM you save in other ways is 8 headcounts (@$125k) you could have to perform work
If you can eliminate >5% of your workforce for performance, you aren’t managing it effectively
In the event labor ever becomes “numbers on a spreadsheet”, ask someone else to manage cost
In my experience, people would take other levers more seriously if their headcount was in play
Approach
IT Operations – Provide critical, minimum data to enable benchmarking and governance
Portfolio Management – Ensure effective prioritization, slotting, and resource utilization
Release Strategy – Have a disciplined to minimize operating disruptions and optimize utilization
Enterprise Architecture – Establish a capability to develop blueprints, simplify, and standardize
Applications – Rationalize on an ongoing basis to manage costs and promote speed-to-market
Data – Promote interoperability, minimize data movement, and avoid monolithic solutions
Artificial Intelligence – Establish a disciplined and governed process for AI introduction and use
Technologies – Minimize duplication and manage end-of-life to avoid disruptive costs
Infrastructure – Unless there is a legal or compliance-related reason, shift to external providers
Cloud – Develop a FinOps capability to review and adjust resource consumption to avoid waste
Licensing – Establish an ongoing process to review, optimize, and manage license transitions
Modernization – Actively modernize solutions to avoid episodic efforts that increase costs
Services – Define a workforce and sourcing strategy, govern relationships, negotiate effectively
What It Is: App Rationalization is the process of reducing redundancies that exist in an application portfolio in the interest of reducing complexity, cost of ownership, and improving speed-to-market.
Why It Matters: Organizations typically spend anywhere between 50-80% of their IT budget maintaining and supporting systems in place. That limits investment in innovation and competitive advantage.
Key Concepts
Understand that rationalization is more about change management than technology
Ensure there are healthy relationships in place and strong leadership support for the work
Focus in on critical areas of the portfolio that drive cost. Don’t boil the ocean
Don’t worry about creating the perfect infrastructure day one. Clean that up along the way
Start with how your business operates and simplify and standardize processes first
Align your future blueprint as cleanly to your desired operating footprint as possible
Consider your Artificial Intelligence (AI), cloud, and security strategies in the future vision
Simplification can come through reducing both unique applications and instances of applications
Address how systems will be supported and enhanced moving forward in your design
Explicitly include milestones for decommissioning in your roadmap. Don’t let that go undone
Expect the work to continually evolve and adapt. Plan for change and adjust responsively
Include rationalization as part of your ongoing portfolio strategy so it’s not a one-time event
Approach
Align – Obtain organizational support critical to defining vision, scope, and facilitating change
Understand – Gather an understanding of the current state and alignment to operations
Evaluate – Leverage something like the Gartner TIME model to evaluate portfolio quality and fit
Strategize – Develop a future state blueprint, CBA, and proposed changes to the environment
Socialize – Obtain feedback, iterate, clarify the vision, and finalize the initial roadmap
Mobilize – Launch first wave of delivery, realign ongoing work as required
Execute – Deliver on 30-, 60-, and 90-day goals, governing and adjusting the approach as you go
Ok, I have the scope identified, but what do I do now?
Having recently written about the intangibles and scope associated with simplification, the focus of this article is the process of rationalization itself, with an eye towards reducing complexity and operating cost.
The next sections will breakdown the steps in the process flow above, highlighting various dimensions and potential issues that can occur throughout a rationalization effort. I will focus primarily on the first three steps (i.e., the analysis and solutioning), given that is where the bulk of the work occurs. The last two steps are largely dedicated to socializing and executing on the plan, which is more standard delivery and governance work. I will then provide a conceptual manufacturing technology example to illustrate some ways the exercise could play out in a more tangible way.
Understand
The first step of the process is about getting a thorough understanding of the footprint in place to enable reasonable analysis and solutioning. This does not need to be exhaustive and can be prioritized based on the scope and complexity of the environment.
Clarify Ownership
What’s Involved:
Identifying technology owners of sets of applications, however they are organized. Hereinafter referred to as portfolio owners
Identifying primary business customers for those applications (business owners)
Identifying specific individuals who have responsibility for each application (application owners)
Portfolio and application owners can be the same individual, but in larger organizations, they likely won’t be given the scope of an individual portfolio and ways it is managed
Why It Matters:
Subject matter knowledge will be needed relative to applications and the portfolios in which they are organized, the value they provide, their alignment to business needs, etc.
Opportunities will need to be discussed and decisions made related to ongoing work and the future of the footprint, which will require involvement of these stakeholders over time
Key Considerations:
Depending on the size of the organization and scope of various portfolios in place, it may be difficult to engage the right leaders in the process, in which case a designate should be identified who can serve as a day-to-day representative of a larger organization, who is empowered to provide input and make recommendations on behalf of their respective area.
In these cases, a separate process step will need to be added to socialize and confirm the outcomes of the process with the ultimate owners of the applications to ensure alignment, regardless of the designated responsibilities of the people participating in the process itself. Given the criticality of simplification work, there could be substantial risk in making broad assumptions related to organizational support and alignment, so some form of additional checkpoints would be a good idea in nearly all cases where this occurs
Inventory Applications
What’s Involved:
Working with Portfolio Owners to identify the assets across the organization and create as much transparency as possible into the current state environment
Why It Matters:
There are two things that should come from this activity: an improved understanding of what is in place, and an intangible understanding of the volatility, variability, and level of opacity in the environment itself. In the case of the latter point, if I find that I have a substantial amount more applications across a set of facilities or set of operating units than I expected and those vary by business greatly, it should inform how I think about the future state environment and governance model I want in place to manage that proliferation in the future. This is related to my point on being a “historian” in the process in the previous article on managing the intangibles of the process.
Key Considerations:
Catalogue the unique applications in production, providing a general description of what they do, users of the technology (business units, individual facilities, customer segments/groups), primary business function(s)/capabilities provided, criticality of the solution (e.g., whether it is a mission-critical/“core” or supporting/”fringe” application), teams that support the application, number of application instances (see the next point), key owners (in line with the roles mentioned above), mapping to financials (the next point after this), mapping to ongoing delivery efforts (also described below), and any other critical considerations where appropriate (e.g., on a technology platform that is near end of life)
In concert with the above, identify the number of applicationinstances in production, specifically the number of different configurations of a base application running on separate infrastructure, supporting various operations or facilities with unique rules and processes, or anything that would be akin to a “copy-paste-modify” version of a production application. This is critical to understand and differentiate, because the simplification process needs to consider reducing these instance counts in the interest of streamlining the future state. That simplification effort can be a separate and time-consuming activity on top of reducing the number of unique applications as a whole
Whether to include hosting and the technology stack of a given application is a key consideration in the inventory process itself. In general, I would try to avoid going too deep, too early in the rationalization process, because these kinds of issues will surface during the analysis effort anyway and putting them in the first step of the process could slow down the work documenting things on applications that aren’t ultimately the top priority for simplification
Understand Financials
What’s Involved:
Providing a directionally accurate understanding of direct and indirect cost to individual applications across the portfolio
Providing a lens on the expected cost of any discretionary projects targeted at enhancing replacing, or modernizing individual applications (to the extent there is work identified)
Why It Matters:
Simplification is done primarily to save or redistribute cost and accelerate delivery and innovation. If you don’t understand the cost associated with your footprint, it will be difficult to impossible to size the relative benefit of different changes you might make and, as such, the financial model is fundamental to the eventual business case meant to come as an output of the exercise
Key Considerations:
Direct cost related to dedicated teams, licensing, and hosted solutions can be relatively straightforward and easy to gather, along with the estimated cost of any planned initiatives for a specific application
Direct cost can be more difficult to ascertain when a team or third-party supports a set of applications, in which case some form of cost apportionment may be needed to estimate individual application costs (e.g., allocate cost based on number of production tickets closed by application within a portfolio of systems)
Indirect expenses related to infrastructure and security in particular can be difficult to understand depending on the hosting model (e.g., dedicated versus shared EC2 instances in the cloud versus on premises, managed hardware) and how costs for hardware, network, cyber security tools, and other shared services are allocated and tracked back to the portfolio
As I mentioned in my article on the intangibles associated with rationalization, directional accuracy is more important than precision in this activity, because the goal at the early stage of the process is to identify redundancies where there is material cost savings potential, not building out a precise cost allocation for infrastructure in the current state
Evaluate Cloud Strategy
What’s Involved:
Clarifying the intended direction in terms of enterprise hosting and the cloud overall, along with the approach being taken where cloud migration is in progress or planned at some level moving forward
Why It Matters:
Hosting costs change when moving from a hosted to a cloud-based environment, which could affect the ultimate business case, depending on the level of change planned in the footprint (and associated hosting assumptions)
Key Considerations:
There is a major difference in costs for hosting depending on whether you are planning to use a lift-and-shift, modernize, or “containerize”-type of approach to the cloud,
Not all applications will be suitable to the last approach in particular, and it’s important to understand whether this will play into your application strategy as you are evaluating the portfolio and identifying future alternatives
If there is no major shift planned (e.g., because the footprint is already cloud-hosted and modernized or containerized), it could be that this is a non-issue, but likely it does need to be considered somewhere in the process, minimally from a risk management and business case development standpoint
Evaluate AI Strategy
What’s Involved:
Understanding the role AI applications and agentic AI solutions are meant to be a core component in the future application portfolio and enterprise footprint, along with any primary touchpoints for these capabilities as appropriate
Understanding any high opportunity areas from an end user standpoint where AI could aid in improving productivity and effectiveness
Why It Matters:
Any longer-term strategy for enterprise technology today needs to contemplate and articulate how AI is meant to integrate and align to what is going to be in place, particularly if agentic AI is meant to be included as part of the future state, otherwise you risk having to iterate your entire blueprint relatively quickly, which could lead to issues in stakeholder confidence and momentum
Key Considerations:
If Agentic AI is meant to be a material component in the future state, the evaluation process for targeted applications should include their API model and whether they are effectively “open” platforms that can be orchestrated and remote operated as part of an agentic flow. The larger the overall scope of the strategy and longer the implementation is expected to take, the more important this aspect should be as a consideration in the analysis process itself, because orchestration is going to become more critical in large enterprises over time under almost any circumstances
Understanding the role AI is anticipated to play is also important to the extent that it could play a critical role in facilitating transition in the implementation process itself, particularly if it becomes an integrated part of the end user presentment or education and training environment. This could both help reduce implementation costs and accelerate deployment and adoption, depending on how AI is (or isn’t leveraged)
Assess Ongoing Work
What’s Involved:
The final aspect to understanding the current state is obtaining a snapshot of the ongoing delivery portfolio and upcoming pipeline
Why It Matters:
Understanding anticipated changes, enhancements, replacements, or retirements and the associated investments is important to evaluating volatility and also determining the financial consequences of decisions made as part of the strategy
Key Considerations:
Gather a list of active and upcoming projects, applications in scope, the scope of work, business criticality, any significant associated risk, relative cost, and anticipated benefits
Review the list with owners identified in the initial step with a mindset of “go”, “stop”, and “pause” given the desire to simplify overall. It may be the case that some inflight work needs to be completed and handled as sunk cost, but there could be cost avoidance opportunity early on that can help fund more beneficial changes that improve the health of the footprint overall
Evaluate
With a firm understanding of the environment and a chosen set of applications to be explored further (which could be everything), the process pivots to assessing what is in place and identifying opportunities to simplify.
Assess Portfolio Quality
What’s Involved:
Work with business, portfolio, and application owners to apply a methodology, like Gartner’s TIME model, to evaluate the quality of solutions in place. In general, this would involve looking at both business and technology fit in the interest of differentiating what does and doesn’t work, what needs to change, and what requirements are critical to the future state
Why It Matters:
Rationalization efforts can be conducted over the course of months or weeks, depending on the scope and goals of the activity. Consequently, the level of detail that can be considered in the analysis will change based on the time and resources available to support the effort but, regardless of the time and effort available, it is important for there to be a fact-based foundation to support the opportunities identified, even if only at an anecdotal level
Key Considerations:
There are generally two levels of this kind of analysis: a higher-level activity like the TIME model, which provides more of a directional perspective on the underlying applications and a more detailed gap analysis-type activity that evaluates features and functionality in the interest of vetting alternatives and identifying gaps that may need to be addressed in the rationalization process itself. The more detailed activity would typically be performed as part of an implementation process and not upstream in the strategy definition phase. The gap analysis could be performed leveraging a standard package evaluation process (replacing external packages with the applications in place), assuming one exists within the organization
The technical criteria for the TIME model evaluation should include things like AI readiness, platform strategy, underlying technical stack, and other key dimensions based on how critical those individual elements are, as surfaced during the initial stage of the work
Identify Redundancies
What’s Involved:
Assuming some level of functional categories and application descriptions were identified during the data gathering phase of the work, it should be relatively straightforward to identify potential redundancies that exist in the environment
Why It Matters:
Redundancies create opportunities for simplification, but also for improved capabilities. The simplification process doesn’t necessarily mean that those having an application replaced will be “giving up” existing capabilities. It could be the case that the solution to which a given user group is being migrated provides more capabilities than what they currently have in place
Key Considerations:
Not all groups within a large organization have equal means to invest in systems capabilities. There can be situations where migrating smaller entities to solutions in use by larger and more well-funded pieces of the organization allows them to leverage new functionality not available in what they have
In the situation where organizations move from independent to shared/leveraged solutions, it is important to not only consider how the shift will affect cost allocation, but also the prioritization and management of those platforms post-implementation. A concern can often arise in these scenarios that either costs will be apportioned in a way that burdens smaller entities at a greater level of funding than they can sustain or that their needs may not be prioritized effectively once they are in a shared environment with other. Working through these mechanics is a critical aspect of making simplification work at an enterprise level. There needs to be a win-win environment to the maximum extent possible or it will be difficult to incent teams to move in a more common direction
Surface Opportunities
What’s Involved:
With redundancies identified, costs aligned, and some level of application quality/fit understood, it should be possible to look for opportunities to replace and retire solutions that either aren’t in use/creating value or that don’t provide the same level of capability in relation to cost as others in the environment
Why It Matters:
The goal of rationalization is to reduce complexity and cost while making it easier and faster to deliver capabilities moving forward. Where cost is consumed in maintaining solutions that are redundant or that don’t create value, they hamper efforts to innovate and create competitive advantage, which is the overall goal of this kind of effort
Key Considerations:
Generally speaking, the opportunities to simplify will be identified at a high-level during the analysis phase of a rationalization effort. The detailed/feature-level analysis of individual solutions is an important thing to include in the planning of subsequent design and implementation work to surface critical gaps, integration points, and workflow dependencies between systems to facilitate transition to the desired future state environment
Strategize
Having completed the Analysis effort and surfaced opportunities to simplify the footprint, the process shifts to identifying the target future state environment and mapping out the approach to transition.
Define Future Blueprint(s)
What’s Involved:
Assuming some representation of the current state environment has been created as a byproduct of the first two steps of the process, the goal of this activity is to define the conceptual end state footprint for the organization
To the extent that there are corporate shared services, multiple business/commercial entities, operating units, facilities, locations, etc. to be considered, the blueprint should show the simplified application landscape post-transition, organized by operating entity, where one or more operating unit could be mapped into a common element of the future blueprint (e.g., organized by facility type versus individual locations, lower complexity business units versus larger entities)
Why It Matters:
A relatively clear, conceptual representation of the future state environment is needed to facilitate discussion and understanding of the difference between the current environment, the intended future state, and the value for changes being proposed
Key Considerations:
Depending on the breadth and depth of the organization itself, the representation of the blueprint may need to be defined at multiple levels
The approach to organizing the blueprint itself could also provide insight into how the implementation approach and roadmap is constructed, as well as how stakeholders are identified and aligned to those efforts
Map Solutions
What’s Involved:
With opportunities identified and a future state operating blueprint, the next step is to map retained solutions into the future state blueprint and project the future run rate of the application footprint
Why It Matters:
The output of this activity will both provide a vision of the end state and act as input to socializing the vision and approach with key stakeholder in the interest of moving the effort forward
Key Considerations:
There is a bit of art and science when it comes to rationalization, because too much standardization could limit agility if not managed in a thoughtful. I will provide an example of this in the scenario following the process, but a simple example is to think about whether maintaining separate instances of a core application is appropriate in situations where speed to market or individual operating units need the flexibility to have greater autonomy than they might otherwise have if they had to operate off a single, shared instance of one application
I mentioned in the article on the intangibles of simplification, that is it a good idea to take an aggressive approach to the future state, because likely not everything will work in practice and the entire goal of the exercise is to try and optimize as much as possible in terms of value in relation to cost
From a financial standpoint, it is important to be conservative in assumptions related to changes in operating expense. That should manifest itself in allowing for contingency in implementation schedule and costs as well as assuming the decommissioning of solutions will take longer than expected (it most likely will). It is far better to be ahead of a conservative plan than to be perpetually behind an overly aggressive one
Define Change Strategy
What’s Involved:
With the current and future blueprints identified, the next step would be to identify the “building blocks” (in conceptual terms) of the eventual roadmap. This is essentially a combination of three things: application instances to be consolidated, replacement of one application by another, and retirement of applications that are either unused or that don’t create enough value to continue supporting them
Opportunities can also be segregated into big bets that affect core systems and material cost/change, those that are more operational and less substantial in nature, and those that are essentially cleanup of what exists. The segregation of opportunities can help inform the ultimate roadmap to be created, the governance model established, and program management approach to delivery (e.g., how different workstreams are organized and managed)
Why It Matters:
Roadmaps are generally fluid beyond a near-term window because things inevitably occur during implementation and business priorities change. Given there can be a lot of socializing of a roadmap and iteration involved in strategic planning, I believe it’s a good idea to separate the individual transitions from the overall roadmap itself, which can be composed in various ways, depending on how you ultimately want to tackle the strategy. At a conceptual level, you can think of it as a set of Post-it notes representing individual efforts that can be organized in a number of legitimate ways with different cost, benefit, and risk profiles
Key Considerations:
Individual transitions can be assessed in terms of risk, business implications, priority, relative cost and benefits, and so forth as a means to help determine slotting in the overall roadmap for implementation
Develop Roadmap
What’s Involved:
With the individual building blocks for transition identified, the final step in the strategy definition stage is to develop one or more roadmaps to assemble those blocks to explore as many implementation strategies as appropriate
Why It Matters:
The roadmap is a critical artifact in the formation of an implementation plan, though they generally change quite a bit over time depending on the time horizon, scope, complexity, and scale of the program itself
Key Considerations:
Ensure that all work is included and represented, including any foundational or kickoff-related activities that will serve the program as a whole (e.g., establishing a governance model, PMO, etc.)
Include retirements (not just new solution deployments), minimally as milestones, in the roadmap so they are planned and accounted for. There are many times this is missed in my experience with new system deployments
Depending on the scale of implementation, explore various business scenarios (e.g., low risk work up front, big bets first, balanced approaches, etc.) to ascertain the relative cost, benefit, implementation requirements, and risks of each and determine the “best case” scenario to be socialized
Socialize and Mobilize
Important footnote: I’ve generally assumed that the process above would be IT-led with a level of ongoing business participation given much of the data gathering and analysis can be performed within IT itself. That isn’t to say that solutioning and development of a roadmap needs to be created and socialized in a sequential manner as is outlined here. It could also be the case that opportunities are surfaced out of the evaluation effort and then the strategy and socialization is done through a collaborative/ workshop process, it depends on the scope of the exercise and nature of the organization.
With the alternatives and future state recommendations prepared, the remaining steps of the process are fairly standard, in terms of socializing and iterating the vision and roadmap, establishing a governance model and launching the work with clear goals for 30, 60, and 90 days in mind. As part of the ongoing governance process, it is assumed that some level of iteration of the overall roadmap and goals will be performed based on learnings gathered early in the implementation process.
Putting Ideas into Practice – An Example
The Conceptual Example – Manufacturing
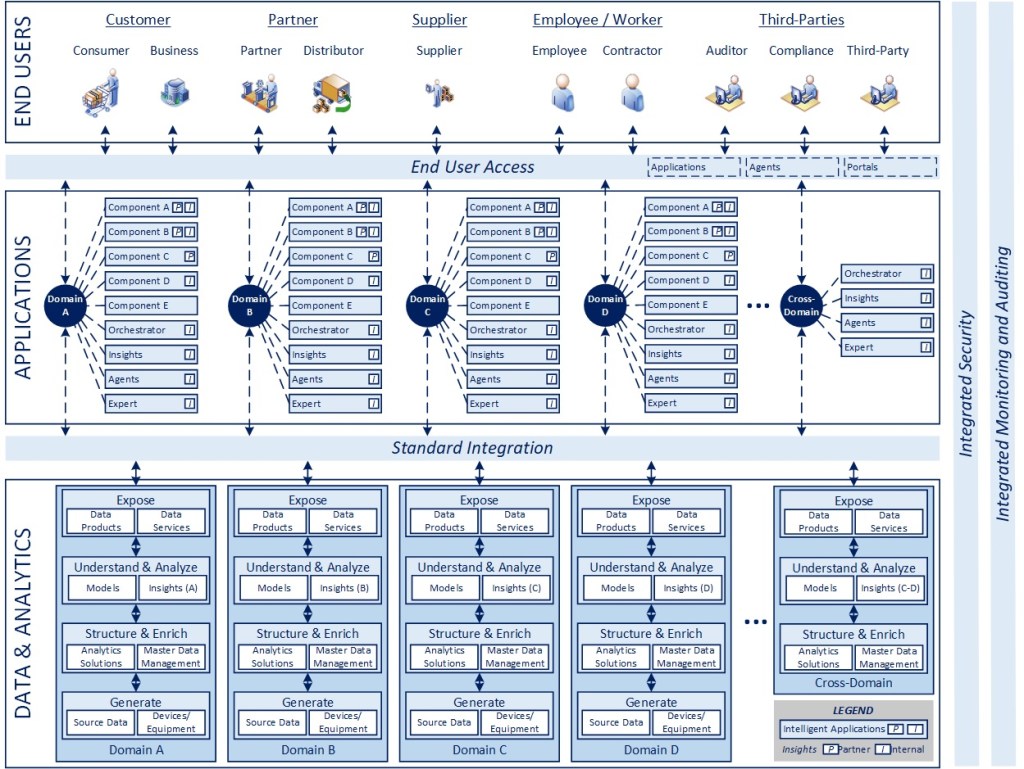
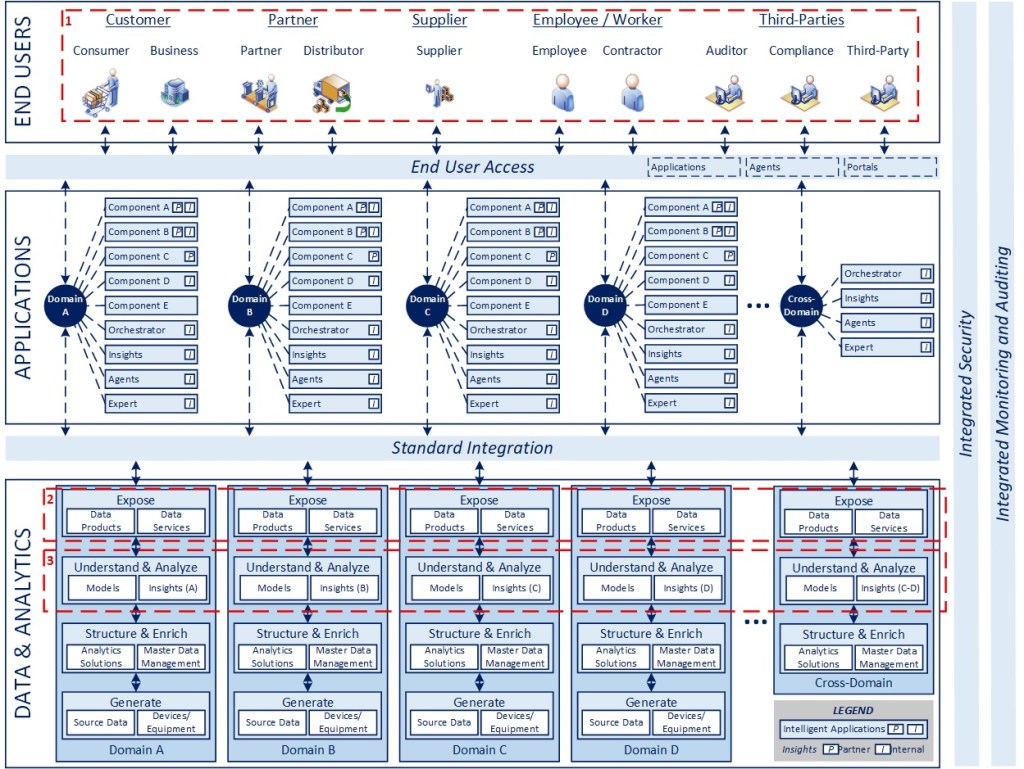
If you’ve made it this far, I wanted to move beyond the theory to a conceptual scenario to help illustrate various situations that could occur in the course of a simplification exercise. The example diagram represents the flow of data across the three initial steps of the process outlined above. The data is logically consistent and traceable across steps in the process if it is helpful in understanding the situation. I limited the number of application types (lower left corner of the diagram) so I could explore multiple scenarios without making the data too overwhelming. In practice, there would be multiple domains and many components in each domain to be considered (e.g., HR is a domain with many components represented as a single application category here), depending on the level of granularity being used for the rationalization effort.
From here, I’ll provide some observations on each major step in the hopes of making some example outcomes clear. I’m not covering the financial analysis given it would make things even more complicated to represent, but for the sake of argument, we can assume that there is financial opportunity associated with reducing the number of applications and instances in place
Notes on the Current State
Some observations on the current state based on the data collected:
The organization has a limited set of corporate applications for Finance, Procurement, and HR, but most of the core applications are relegated to individual business units (there are three in this example) and manufacturing facilities (there are four)
Business Operation 1 is the largest commercial entity, sharing the same HR and Procurement solutions, though with unique copies of its own, a different instance of the core accounting system that is managed separately, with two facilities (1 and 2), using different instances of the same MES system, a common WMS system, and a set of unique fringe applications in most other functional categories, some of which overlap or complement those at the business unit level. Despite these differences in footprint, facilities 1 and 2 are highly similar from an operational/business process standpoint
Business Operations 2 and 3 are smaller commercial entities, running on a different HR system and a different instance of the Procurement solutions than Corporate, a different instance of the core accounting system that is managed separately in one and a unique accounting system in the other, with one facility each (3 and 4), using different MES systems, different instances of the same WMS system, and a set of unique fringe applications in most other functional categories, some of which overlap or complement those at the business unit level. Despite these differences in footprint, facilities 3 and 4 are highly similar from an operational/business process standpoint
All three business entities operate of unique ERP solutions, two of them leverage the same CRM system, though they are on separate instances, so there is no enterprise-level view of customer and financials need to be consolidated at corporate across all three entities using something like Hyperion or OneStream
The facilities utilize three different EAM solutions for Asset Health today, with two of them (2 and 3) using the same software
The fringe applications for accounting, EH&S, HR, and Procurement largely exist because of capability gaps in the solutions already available from the corporate or business unit applications
All things considered, the current environment includes 29 unique applications and 15 application instances.
Sounds complicated, doesn’t it?
Well, while this is entirely a made-up scenario meant to help illustrate various simplification opportunities, the fact is that these things do actually happen, especially as you scale up and out an organization, have acquisitions, or partially roll out technology over time.
Notes on the Evaluation
Observations based on the analysis performed:
Having worked with business, portfolio, and application owners to classify and assess the applications in place, a set of systems surfaced as creating higher levels of business value, between mission-critical core (ERP, CRM, Accounting, MES) and supporting/fringe (Procurement, HR, WMS, EH&S, EAM) applications.
Application A, having been implemented by the largest commercial entity, provides the most capability of any of the solutions in place
Application D, as the current CRM system in use by two of the units today, likely offers the best potential platform for a future enterprise standard
Application F likely would make sense as an enterprise standard platform for accounting, though there is something about Application I currently in Facility 3 that provides unique capability at a day-to-day level
Application V is the best of the MES solutions from a fit and technology standpoint and is in place at two of the facilities today, though running on separate instances
Application K is already in place to support Procurement across most of the enterprise, though instances are varied and Applications L and M exist at the facility level because of gaps in capability today
Applications M and O surface as the best technical solutions in the EH&S space, with all of the others providing equal or lesser business value and technical quality
Application S stands out among other HR solutions as being a very solid technology platform
Application AB is the best of the EAM solutions both in terms of business capability and technical quality
Notes on the Strategy
The overall simplification strategy begins with the desire to standardize operations for smaller business entities 2 and 3 (operating blueprint B) and to run facilities in a more standard way between those supporting the larger commercial unit (facility blueprint A) and those supporting the smaller ones (facility blueprint B).
From a big bets standpoint:
ERP: Make improvements to Application A supporting business operation 1 so that the company can move from three ERPs to one, using a separate instance for the smaller operating units.
CRM: Make any necessary enhancements to Application D so that it can be run as a single enterprise application supporting all three business units (removing it from their footprint to manage), providing a mechanism to have a single view of the customer and reduced operating complexity and cost
Accounting: Given it is already largely in place across businesses, make improvements to Application F so it can serve as a single enterprise finance instance and remove it from footprint of the individual units. In the case of the facility-level requirements, making updates to accounting Application I and standardizing on that application for the small business manufacturing facilities.
MES: Finally, standardize on Application V across facilities, with a unique instance being used to operate large and small business facilities respectively
For Operational Improvements:
Procurement and HR: Similar to CRM and Accounting, standardize on Application K and S so that they can be maintained and operated at the enterprise level
EH&S: Assuming there are differences how they operate, standardize to Applications M and O as solutions for large and smaller units respectively, eliminating all other applications in place
WMS: Y is already the standard for large facilities, so no action is needed there. For smaller facilities, consolidate to a single instance to support both facilities rather than maintain two versions of Application Z
EAM: standardize to a single, improved version of Application AB and eliminate other applications currently in place
Finally, for low value applications like H and M, to review and ensure no dependencies or issues exist, but to sunset those applications and reduce complexity and any associated cost outright
Post-implementation, the future environment would include 12 unique applications and 2 application instances, which is a net reduction of 17 applications (59%) and 13 instances (87%), likely with a substantial cost impact as well.
Wrapping Up
I realized in chalking out this article that it would be a substantial amount of information, but it is aimed at practitioners in the interest of sharing some perspective on considerations involved in doing rationalization work. In my experience, what seems fairly straightforward on paper (including in my example above) generally isn’t for many reasons that are organizational and process-driven in nature. That being said, there is a lot of complexity in many organizations to be addressed and so hopefully some of the ideas covered will be helpful in making the process a little more manageable.
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
I have all this complexity, and I’m not sure what I can do about it…
In medium- to large-scale organizations, complexity is part of daily life. Systems build up over time, as does the integration between them, and eventually it is easy to have a very complex spider web of applications and data solutions across an enterprise, some of which provide significant value, some that are there for reasons no one can explain… but the solution is somehow still viewed to be essential.
Returning to a simplified technology footprint is often desirable for multiple reasons:
A significant portion of ongoing spend is required to support and maintain what’s in place, hampering efforts to innovate, improve, or create new, more highly valued capabilities
New delivery efforts take a long time, because there is so much to consider in implementation both to integrate what exists and also not to break something in the process of making changes
Technologies continue to advance and security exposures come about, and a large portion of IT spend becomes consumed in “modernization” of things that don’t create enough value to justify the spend, but you don’t have a choice not to invest in them given they also can’t be retired
People enter and leave the organization over time. Onboarding people takes time and cost, leading to suboptimized utilization for an extended period of time, and exits can orphan solutions where the risks for modifying or retiring something are difficult to evaluate
The problem is that simplification, like modernization, is often treated as a point-in-time activity and not an ongoing maintenance effort as part of an annual planning and portfolio management process. As a result, assets accumulate, and the cost for addressing the associated complexity and technical debt increases substantially the longer it takes to address the situation. I will address optimizing overall IT productivity in a separate article, but this is definitely an issue that exists in many organizations today.
Having recently written about the intangibles associated with simplification, the focus of this article is establishing the foundation upon which a rationalization effort can be built, because the way you define scope and the tools you use to manage the process matter.
A quick note on Enterprise Architecture…
While the focus of this series of articles is specifically on app rationalization, my point of view on enterprise architecture overall is no different than what is outlined in the recent 7-part series on “The Intelligent Enterprise in an AI World” (Intelligent Enterprise Recap). The future of technology will move to a producer/consumer model, involving highly configurable, intelligent applications, with a heavy emphasis on standard integration and orchestration (largely through agentic AI), organized via connected domain-based ecosystems.
While the overall model and framework is the same, the focus in this series is the process for identifying and simplifying the application footprint, where applications are the “components” referenced above.
Establishing the Foundation
Infrastructure
In a perfect world, any medium or large organization should have some form of IT Asset Management (ITAM) solution in place to track and manage assets, identify dependencies, enable ongoing discovery and license management, and a host of other things. In a perfect world, it can also be integrated with your IT Service Management (ITSM) infrastructure provide a fully traceable mechanism to link assets to incidents and strive to improve reliability and operating performance over time.
Is this kind of infrastructure required for a simplification effort? No.
The goal of rationalization is not boiling the ocean or establishing an end-to-end business aligned enterprise infrastructure for managing the application portfolio, the goal is identifying opportunities to simplify and optimize.
In a perfect world, an enterprise architecture strategy should start with business capabilities, map those to technology capabilities, then translate that into the infrastructure (components and services) required to enable those technology capabilities. It would be wonderful and desirable to lay all of that out in the context of a rationalization effort, but those things take time and investment, and to the extent you are planning to replace and retire a potentially significant portion of what you have, it’s better to reduce the clutter and duplication first (assuming your footprint largely supports and aligns to your business needs) and then clean up and streamline your infrastructure as a secondary priority, with only the retained assets in scope.
In the rare situation where technology is fundamentally believed to be misaligned to the core business needs, it could be necessary and appropriate to start with the business strategy and go top-down from there, but I would assume this would be the exception in most case. Said differently: If you can get your rationalization effort done with the simplest tools you have (e.g., Microsoft Excel), go ahead, just make sure the data is accurate. Buy and leverage a more robust platform later, preferably when you know how you are planning to use it and commit to what it will take to maintain the data, because that is ultimately where their value is established and proven over time.
Scope
What is an application?
One of the deceptive things about rationalization work is how this simple this question appears when you haven’t gone through the exercise before. The problem is that we use a host of things in the course of doing work, built with various technologies in multiple ways, and the way we determine scope in the interest of simplification matters.
Specifically, here is a list of things that potentially you should consider in a rationalization effort and my point of view on whether I’d normally consider them to be in scope:
Business applications (ERPs, CRM, MES, etc.): This is a given and generally the primary focus.
Tools (Microsoft Word, Alteryx, Tableau): Generally no. Tools produce content. They generally don’t enable business processes, which is what I consider core to an “application”.
Third-Party Websites and Platforms (WordPress, PluralSight): In scope, to the degree they are supporting an essential business function or been customized to provide required capabilities
Citizen-Developed Applications: Generally yes, to the degree there is associated cost
Analytics/BI Solutions: Generally no. While data marts, warehouses, and so on provide business functionality, I consider analytics and applications to be two distinct technology domains that should be analyzed and rationalized separately, while being integrated into a cohesive overall enterprise architecture strategy
SharePoint sites: No. SharePoint is used to manage content, not provide functionality.
SharePoint applications: Generally yes, because there is an associated workflow and business process being enabled.
Robotic Process Automation (RPA): Generally no. RPA tools tend to act as utilities that automate simple tasks, but don’t provide robust capabilities at the level of an application. There could be exceptions to this, but I would be concerned if an RPA tool was providing a critical capability and wasn’t actually architected, designed, and built as an application to begin with. That is a mismatch from an EA standpoint and likely I’d want to investigate migrating to a more robust and well-architected solution
Agentic AI Solutions: Yes. While this may be limited today, it will become more prevalent in the coming months and the relationship to existing solutions needs to be understood.
AI Solutions/Packages: Yes. In this case, by comparison with agentic solutions overlapping applications in a footprint, I’d be interested in looking for duplication and redundancy that may occur because AI adoption is relatively new, governance models are largely immature (if they exist at all) and the probability of having multiple tools that perform essentially the same function in medium- to large-organization is or will be relatively high, very soon.
Vibe-Coded Solutions: Absolutely yes. These need to be tracked particularly from a security exposure standpoint given how new these technologies are and the associated risk for putting them into production at this stage of the technology’s evolution.
Mobile Applications: If it is a standalone application, yes, likely should be included. If it is a different form of presentment on a web-enabled application, it theoretically should be included as part of the source application, so no. Depending on the criticality of mobility in the enterprise technology strategy, whether an app is mobile enabled could be part of the inventory data gathered, but only if it is critical to the strategy, otherwise I would leave it out
IoT Devices: No. Physical assets and devices should be managed and rationalized separately as part of a device strategy (again, that integrates with an overall enterprise architecture)
So, the list above contains more than “business applications”, which is why I said scope can be tricky in a simplification / rationalization effort.
Beyond the considerations mentioned above, a key question to consider on whether any of these additional types of assets is in scope is: is there associated cost to maintain and support the asset, is there cyber security exposure, or are there compliance or privacy-related considerations with it. Ultimately, any or all of these dimensions need to be considered in the exercise, because simplification not only should reduce complexity and cost, it should reduce security exposure and business risk.
Wrapping Up
From here, the focus will pivot to the process itself and a practical example to help illustrate the concepts put into more of a “real world” scenario.
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
It ought to be easier (and cheaper) to run a business than this…
Complexity and higher than desirable operating cost are prevalent in most medium- to large-scale organizations. With that, generally some interest follows in exploring ways to reduce and simplify the technology footprint, to reduce ongoing expenses, mitigate risk and limit security exposure, and free up capital either to reinvest in more differentiated and value-added activity, or to contribute directly to the bottom line overall.
The challenge is really in trying to find the right approach to simplification that is analytically sound while providing insight at speed so you can get to the work and not spend more time “analyzing” than is required at any step of the process.
In starting to outline the content for this article, aside from identifying the steps in a rationalization process and working through a practical example to illustrate some scenarios that can occur, I also started noting some other, more intangible aspects to the work that have come up in my experience. When that list reached ten different dimensions, I realized that I needed to split what was intended to be a single article on this topic into two parts: one that addresses the process aspects of simplification and one that addresses the more intangible and organizational/change management-oriented dimensions. This piece is focused on the intangibles, because the environment in which you operate is critical to setting the stage for the work and ultimate results you achieve.
The Remainder of this Article…
The dimensions that came to mind fell into three broader categories, into which they are organized below, they are:
Leading and Managing Change
Guiding the Process and Setting Goals
Planning and Governance
For each dimension, I’ll try to provide some perspective on why it matters and some potential ideas to consider in the interest of addressing them in the context of a simplification effort overall.
Leading and Managing Change
At its core, simplification is a change management and transformational activity and needs to be approached as such. It is as much about managing the intangibles and maintaining healthy relationships as anything to do with the process you follow or opportunities you surface. Certainly, the structural aspects and the methodology matter, but without giving attention to the items below, likely you will have either some very rough sledding in execution, suboptimize your outcomes, or fail altogether. Said differently: the steps you follow are only part of the work, improving your operating environment is critically important.
Leadership and Culture Matter
Like anything else that corresponds to establishing excellence in technology, courageous leadership and an enabling culture are fundamental to a simplification activity. The entire premise associated with this work rests in change and, wherever change is required,there will be friction and resistance, and potentially significant resistance at that.
Some things to consider:
Putting the purpose and objective of the change front and center and reinforcing it often (likely reducing operating expense in the interest of improving profitability or freeing up capital for discretionary spending)
Working with a win-win mindset, looking for mutual advantage, building partnerships, listening with empathy, and seeking to enroll as many people in the cause as possible over time
Being laser-focused on impact, not solely on “delivery”, as the outcomes of the effort matter
Remaining resilient, humble (to the extent that there will be learnings along the way), and adaptable, working with key stakeholders to find the right balance between speed and value
It’s Not About the Process, It’s About Your Relationships
Much like portfolio management, it is easy to become overly focused on the process and data with simplification work and lose sight of the criticality of maintaining a healthy business/technology partnership. If IT has historically operated in an order taker mode, suggesting potentially significant changes to core business applications that involve training large numbers of end users (and the associated productivity losses and operating disruptions that come with that) may go nowhere, regardless of how analytically sound your process is.
Some things to consider:
Know and engage your customer. Different teams have different needs, strategies, priorities, risk tolerance, and so on
You can gather data and analyze your environment (to a degree) independent of your business partners, but they need to be equally invested in the vision and plan for it to be successful
Establishing a cadence, individually and collectively, with key stakeholders, aligned to the pace of the work, minimally to maintain a healthy, transparent, and open dialogue on objectives, opportunities, risks, and required inventions and support, is important
Be a Historian as Much as You are an Auditor
Back to the point above on improving the operating environment being as important as your process/ methodology, it is important to recognize something up front in the simplification process: you need to understand how you got where you are as part of the exercise, or you may end right back there as you try to make things “better”. It could be that complexity is a result of a sequence of acquisitions, a set of decentralized decisions without effective oversight or governance, functional or capability gaps in enterprise solutions being addressed at a “local” level, underlying culture or delivery issues, etc. Knowing the root causes matters.
As an example, I once saw a situation where two teams implemented different versions of the same application (in different configurations) purely because the technology leaders didn’t want to work with each other. The same application could’ve supported both organizations, but the decisions were made without enterprise-level governance, the operating complexity and TCO increased, and the subsequent cost to consolidate into a single instance was deemed “lower priority” than continuing work. While this is a very specific example, the point is that understanding how complexity is created can be very important in pivoting to a more streamlined environment.
Some things to consider:
As part of the inventory activity, look beyond pure data collection to having an opportunity to understand how the various portfolios of applications came about over time, the decisions that led to the complexity that exists, the pain points, and what is viewed as working well (and why)
Use the insights obtained to establish a set of criteria to consider in the formation of the vision and roadmap for the future so you have a sense whether the changes you’re making will be sustainable. These considerations could also help identify risks that could surface during implementation that could reintroduce the kind of complexity in place today
What Defines “Success”
Normally, a simplification strategy is based on a snapshot of a point in time, with an associated reduction in overall cost (or shift in overall spend distribution) and/assets (applications, data solutions, etc.). This is generally a good way to establish the case for change and desired outcome of the activity itself, but it doesn’t necessarily cover what is “different” about the future state beyond a couple core metrics. I would argue that it is also important to consider what I mentioned in the previous point, which is how the organization developed a complex footprint to begin with.
As an example, if complexity was caused by a rapid series of acquisitions, even if I do a good job of reducing or simplifying the footprint in place, if I continue to acquire new assets, I will end up right back where I was, with a higher operating cost than I’d like. In this case, part of your objective could be to have a more effective process for integrating acquisitions.
Some things to consider:
Beyond the financial and operating targets, identify any necessary process or organizational changes needed to facilitate sustainability of the environment overall
This could involve something as simple as reviewing enterprise-level governance processes, or more structural changes in how the underlying technology footprint is managed
Guiding the Process and Setting Goals
A Small Amount of Good Data is Considerably Better than a Lot of Bad
As with any business situation, it’s tempting to assume that having more data is automatically a good thing. In the case of maintaining an asset inventory, the larger and more diverse an organization is, the more difficult it is to maintain the data with any accuracy. To that end, I’m a very strong believer in maintaining as little information as possible, doing deep dives into detail only as required to support design-level work.
As an example, we could start the process by identifying functional redundancies (at a category/component level) and spend allocations within and across portfolios as a means to surface overall savings opportunity and target areas for further analysis. That requires a critical, minimum set of data, but at a reasonable level of administrative overhead. Once specific target areas are identified and prioritized, further data gathering in the interest of comparing different solutions, performing gap analyses, and identifying candidate future state solutions can be done as a separate process. This approach is prioritizing going broad (to Define opportunities) versus going deep (to Design the solution), and I would argue it is a much more effective and efficient way to go about simplification, especially if the underlying footprint has any level of volatility where the more detailed information will become outdated relatively quickly.
Some things to consider:
Prioritize a critical, minimum set of data (primary functions served by an application, associated TCO, level of criticality, businesses/operating units supported, etc.) to understand spend allocation in relation to the operating and technology footprint
Deep dive into more particulars (functional differences across similar systems within a given category) as part of a specific design activity downstream of opportunity identification
Be Greedy, But Realistic
The simplification process is generally going to be iterative in nature, insofar as there may be a conceptual target for complexity and spend reduction/reallocation at the outset, some analysis is performed, the data provides insight on what is possible, the targets are adjusted, further analysis or implementation is performed, the picture is further refined, and so on.
In general, my experience is that there are always going to be issues in what you can practically pursue, and therefore, it is a good idea to overshoot your targets. By this, I mean that we should strive to identify more than our original savings goals because if we limit the level of opportunities we identify to a preconceived goal or target, we may either suboptimize the business outcome if things go well, or fall short of expectations in the event we are able to pursue only a subset of what is originally identified for various business, technology, or implementation-related issues.
Some things to consider:
Review opportunities, asking what would be different if you could only pursue smaller, incremental efforts, had a target that was twice what you’ve identified, could start from scratch and completely redefine your footprint with an “optimal case” in mind… and consider what, if anything would change about your scope and approach
Planning and Governance
Approach Matters
Part of the challenge with simplification is knowing where to begin. Do you cover all of the footprint, the fringe (lower priority assets), the higher cost/core systems? The larger an organization is, the more important it is to target the right opportunities quickly in your approach and not try to boil the ocean. That generally doesn’t work.
I would argue that the primary question to understand in terms of targeting a starting point is where you are overall from a business standpoint. The first iteration of any new process tends to generate learnings and improvements, so there will be more disruption than expected the first time you execute the process end-to-end. To that point, if there is a significant amount of business risk to making widespread, foundational changes, it may make sense to start on lower risk, clean up type activities on non-core/supporting applications (e.g., Treasury, Tax, EH&S, etc.) by comparison with core solutions (like an ERP, MES, Underwriting, Policy Admin, etc.). On the other hand, if simplification is meant to help streamline core processes, enable speed-to-market and competitive advantage, or some form of business growth, it could be that focusing on core platforms first is the right approach to take.
The point is that the approach should not be developed independent of the overall business environment and strategy, they need to align with each other.
Some things to consider:
As part of the application portfolio analysis, understand the business criticality of each application, level of planned changes and enhancements, how those enable upcoming strategic business goals, etc.
Consider how the roadmap will enable business outcomes over time; whether that is ideally a slow, build process of incremental gains, or more of a big bets, high impact changes that materially affect business value and IT spend
Accuracy is More Important Than Precision
This point may seem to contradict what I wrote earlier in terms of having a smaller amount of good data, but the point here is that it’s important to acknowledge in a transformation effort that there is a directly proportional relationship between the degree of change involved in the effort and the associated level of uncertainty in the eventual outcome. Said differently: the more you change, the less you can predict the result with any precision.
This is true because there is a limited level of data generally available in terms of the operating impact of changes to people, process, and technology. Consequently, the more you change in terms of one or more of those elements, your ability to predict the exact outcome from a metrics standpoint (beyond a more anecdotal/conceptual level) will be limited. In line with the concepts that I shared in the recent “Intelligent Enterprise 2.0” series, with orchestration and AI, I believe we can gather, analyze, and leverage a greater base of this kind of data, but the infrastructure to do this largely doesn’t exist in most organizations I’ve seen today.
Some things to consider:
Be mindful not to “overanalyze” the impact of process changes up front in the simplification effort. The business case will generally be based on the overall reduction in assets/ complexity, changes in TCO, and shifts (or reductions) in staffing levels from the current state
It is very difficult to predict the end state when a large number of applications are transitioned as part of a simplification program, so allow for a degree of contingency in the planning process (in schedule and finances) rather than spending time. Some things that may not appear critical generally will reveal themselves to be only in implementation, some applications that you believe you can decommission will remain for a host of reasons, and so on. The best laid plans on paper rarely prove out exactly in the course of execution depending on the complexity of the operating environment and culture in place
Expect Resistance and Expect a Mess
Any large program in my experience tends to go through an “optimism” phase, where you identify a vision and fairly significant, transformative goal, the business case and plan looks good, it’s been vetted and stakeholders are aligned, and you have all the normal “launch” related events that generate enthusiasm and momentum towards the future… and then reality sets in, and the optimism phase ends.
Having written more than once on Transformation, the reality is that it is messy and challenging, for a multitude of reasons, starting with patience, adaptability, and tenacity it takes to really facilitate change at a systemic level. Status quo feels safe and comforting, it is known, and upsetting that reality will necessarily lead to friction, resistance, and obstacles throughout the process.
Some things to consider:
Set realistic goals for the program at the outset, acknowledge that it is a journey, that sustainable change takes time, the approach will evolve as you deliver and learn, and that engagement, communication, and commitment are the non-negotiables you need throughout to help inform the right decisions at the right time to promote success
Plan with the 30-, 60-, and 90-day goals in mind, but acknowledge that any roadmap beyond the immediate execution window will be informed by delivery and likely evolve over time. I’ve seen quite a lot of time wasted on detailed planning more than one year out where a goal-based plan with conceptual milestones would’ve provided equal value from a planning and CBA standpoint
Govern Efficiently and Adjust Responsively
Given the scale and complexity of simplification efforts, it would be relatively easy to “over-report” on a program of this type and cause adverse impact on the work itself. In line with previous articles that I’ve written on governance and transparency, my point of view is that the focus needs to be on enabling delivery and effective risk management, not administrative overhead.
Some things to consider:
Establish a cadence for governance early on to review ongoing delivery, identify interventions and support needed, learnings that can inform future planning, and adjust goals as needed
Large programs succeed or fail in my experience based on maintaining good transparency to where you are, identifying course corrections when needed, and making those adjustments quickly to minimize the cost of “the turns” when they inevitably happen. Momentum is so critical in transformation efforts that minimizing these impacts is really important to keeping things on track
Wrapping Up
Overall, the reason for separating the process from the change in addressing simplification was deliberate, because both aspects matter. You can have a thoughtful, well executed process and accomplish nothing in terms of change and you can equally be very mindful of the environment and changes you want to bring about, but the execution model needs to be solid, or you will lose any momentum and good will you’ve built in support of your effort.
Ultimately, recognizing that you’re both engaging in a change and a delivery activity is the critical takeaway. Most medium- to large-scale environments end up complex for a host of reasons. You can change the footprint, but you need to change the environment as well, or it’s only a matter of time before you’ll find yourself right back where you started, perhaps with a different set of assets, but a lot of same problems you had in the first place.
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
I remember a situation where an organization decided to aggressively offshore work to reduce costs. The direction to IT leaders was no different than that of the Gold Rush above. Leaders were given a mandate, a partner with whom to work, and a massive amount of contracting ensued. The result? A significant number of very small staff augmentation agreements (e.g., 1-3 FTEs), a reduction in fixed, but a disproportionate increase in variable operating expenses, and a governance and administrative nightmare. How did it happen? Well, there was leadership support, a vision, and a desired benefit, but no commonly understood approach, plan, or governance. The organization then spent a considerable amount of time transitioning all of the agreements in place to something more deliberate, establishing governance, and optimizing what quickly became a very expensive endeavor.
The requirements of transformation are no different today than they ever have been. You need a vision, but also the conditions to promote success, and that includes an enabling culture, a clear approach, and governance to keep things on track and make adjustments where needed.
This is the final post in a series focused on where I believe technology is heading, with an eye towards a more harmonious integration and synthesis of applications, AI, and data… what I previously referred to in March of 2022 as “The Intelligent Enterprise”. The sooner we begin to operate off a unified view of how to align, integrate, and leverage these oftentimes disjointed capabilities today, the faster an organization will leapfrog others in their ability to drive sustainable productivity, profitability, and competitive advantage.
Overall Approach
Writing about IT operating models can be very complex for various reasons, and mostly because there are many ways to structure IT work based on the size and complexity of an organization,and there is nothing wrong with that in principle. A small- to medium-size IT organization, as an example, likely has little separation of concerns and hierarchy, people playing multiple roles, a manageable project portfolio, and minimal coordination required in delivery. Standardization is not as complex and requires considerably less “design” than a multi-national or large-scale organization, where standardization and reuse needs to be weighed against the cost of coordination and management involved as the footprint scales. There can also be other considerations, such as one I experienced where simplification of a global technology footprint was driven off of operating similarities across countries rather than geographic or regional considerations.
What tends to be common across ways of structuring and organizing is the various IT functions that exist (e.g., portfolio management, enterprise architecture, app development, data & analytics, infrastructure, IT operations), just at different scales and levels of complexity. These can be capability-based, organized by business partner, with some centralized capabilities and some federated, etc. but the same essential functions likely are in place, at varying levels of maturity and scale based on the needs of the overall organization. In multi-national or multi-entity organizations/conglomerates, these functions likely will be replicated across multiple IT organizations with some or no shared capability existing at the parent/holding company or global level.
To that end, I am going to explore how I think about integrating the future state concepts described in the earlier articles of this series in terms of an approach and conceptual framework that, hopefully, can be applied to a broad range of IT organizations, regardless of their actual structure.
The critical challenge with moving from our current environment to one where AI, apps, and data are synthesized and integrated is doing it in a way that follows a consistent approach and architecture while not centralizing so much that we either constrain progress or limit innovation that can be obtained by spreading the work across a broader percentage of an organization (business teams included). This is consistent with the templatized approach discussed in the prior article on Transition, but there can be many ways that that effort is planned and executed based on the scale and complexity of the organization undertaking the transformation itself.
Key Considerations
Define the Opportunities, Establish the Framework, Define the Standards
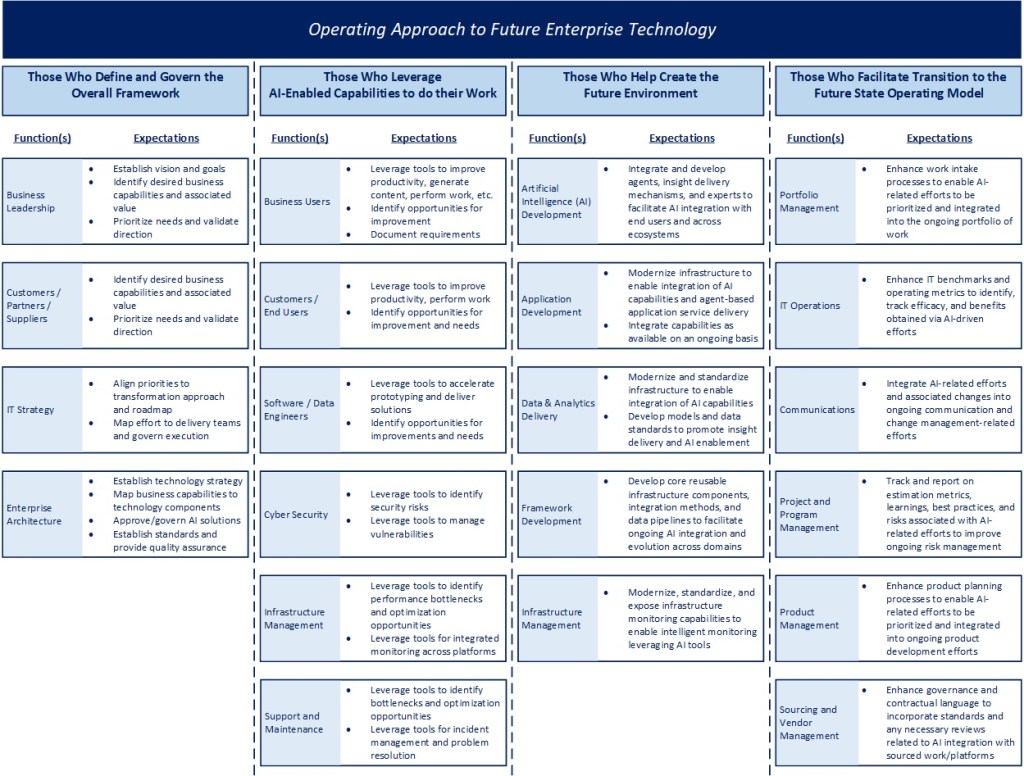
Before being concerned with how to organize and execute, we first need to have a mental model for how teams will engage with an AI-enabled technology environment in the future. Minimally, I believe that will manifest itself in four ways:
Those who define and govern the overall framework
Those who leverage AI-enabled capabilities to do their work
Those who help create the future environment
Those who facilitate transition to the future state operating model
I will explore the individual roles in the next section, but an important first step is defining the level of standardization and reuse that is desirable from an enterprise architecture standpoint. That question becomes considerably more complex in organizations with multiple entities, particularly when there are significant differences in the markets they serve, products/services they provide, etc. That doesn’t mean, however, that reuse and optimization opportunities don’t exist, but rather that they need to be more thoughtfully defined and developed so as not to slow any individual organization down in their ability to innovate and promote competitive advantage. There may be opportunities to look for common capabilities that make more sense to develop centrally and reuse that can actually accelerate speed-to-market if built in a thoughtful manner.
Regardless of whether capabilities in a larger organization are designed and developed in a highly distributed manner, having a common approach to the overall architecture and standards (as discussed in the Framework article in this series) could be a way to facilitate learning and optimization in the future (within and across entities), which will be covered in the third portion of this article.
Clarify the Roles and Expectations, Educate Everyone
The table below is not meant to be exhaustive, but rather to act as a starting point to consider how different individuals and teams will engage with the future enterprise technology environment and highlight the opportunity to clarify those various roles and expectations in the interest of promoting efficiency and excellence.
While I’m not going to elaborate on the individual data points in the diagram itself, a few points to note in relation to the table.
There is a key assumption that AI-related tools will be vetted, approved, and governed across an enterprise (in the above case, by the Enterprise Architecture function). This is to promote consistency and effectiveness, manage risk, and consider issues related to privacy, IP-protection, compliance, security, and other critical concerns that otherwise would be difficult to manage without some formal oversight.
It is assumed that “low hanging fruit” tools like Copilot, LLMs, and other AI tools will be used to improve productivity and look for efficiency gains while implementing a broader, modern and integrated future state technology footprint with integrated agents, insights, and experts. The latter of these things has touchpoints across an organization, which is why having a defined framework, standards, and governance are so important in creating the most cost-effective and rapid path to transforming the environment to one that create disproportionate value and competitive advantage.
Finally, there are adjustments to be made in various operating aspects of running IT, which is to reinforce the idea that AI should not be a separate “thing” or a “silver bullet”, it needs to become an integrated part of the way an organization leverages and delivers technology capabilities. To the extent it is treated as something different or special and separated from the ongoing portfolio of work and operational monitoring and management processes, it will eventually fail to integrate well, increase costs, and underdeliver on value contributions that are widely being chased after today. Everyone across the organization should also be made aware of the above roles and expectations, along with how these new AI-related capabilities are being leveraged so they can help identify continuing opportunities to leverage and improve their adoption across the enterprise.
Govern, Coordinate, Collaborate, Optimize
With a model in place and organizational roles and responsibilities clarified, there needs to be a mechanism to collect learnings, facilitate improvements to the “templatized approach” referenced in the previous article in this series, and drive continuous improvement in how the organization functions and leverages these new capabilities.
This can be manifest in several approaches when spread across a medium to large organization, namely:
Teams can work in partnership or in parallel to try a new process or technology and develop learnings together
One team can take the lead to attempt a new approach or innovation and share learnings with other in a fast-follower based approach
Teams can try different approaches to the same type of solution (when there isn’t a clear best option), benchmark, and select the preferred approach based on the learning across efforts
The point is that, to achieve maximum efficiency, especially when there is scale, centralizing too much can hamper learning and innovation, and it is better to develop coordinated approaches that can be governed and leveraged than to have a “free for all” where the overall opportunity to innovate and capture efficiencies is compromised.
Summing Up
As I mentioned at the outset, the challenge in discussing IT implications from establishing a future enterprise environment with integrated AI is that there are so many possibilities for how companies can organize around it. That being said, I do believe a framework for the future intelligent enterprise should be defined, roles across the organization should be clarified, and transition to that future state should be governed with an eye towards promoting value creation, efficiency, and learning.
This concludes the series on my point of view related to the future of enterprise technology with AI, applications, and data and analytics integrated into one, aligned strategy. No doubt the concepts will evolve as we continue to learn and experiment with these capabilities, but I believe there is always room for strategy and a defined approach rather than an excess of ungoverned “experimentation”. History has taught us that there are no silver bullets, and that is the case with AI as well. We will obtain the maximum value from these new technologies when we are thoughtful and deliberate in how we integrate them with how we work and the assets and data we possess. Treating them as something separate and distinct will only suboptimize the value we create over time and those who want to promote excellence will be well served to map out their strategy sooner rather than later.
I hope the ideas across this series were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
A compelling vision will stand the test of time, but it will also evolve to meet the needs of the day.
There are inherent challenges with developing strategy for multiple reasons:
It is difficult to balance the long- and short-term goals of an organization
It generally takes significant investments to accomplish material outcomes
The larger the change, the more difficult it can be to align people to the goals
The time it takes to mobilize and execute can undermine the effort
The discipline needed to execute at scale requires a level of experience not always available
Seeking “perfection” can be counterproductive by comparison with aiming for “good enough”
The factors above, and other too numerous to list, should serve as reminders that excellence, speed, and agility require planning and discipline, they don’t happen by accident. The focus of this article will be to break down a few aspects of transitioning to an integrated future state in the interest of increasing the probability of both achieving predictable outcomes, but also in getting there quickly and in a cost-effective way, with quality. That’s a fairly tall order, but if we don’t shoot for excellence, we are eventually choosing obsolescence.
This is the sixth post in a series focused on where I believe technology is heading, with an eye towards a more harmonious integration and synthesis of applications, AI, and data… what I previously referred to in March of 2022 as “The Intelligent Enterprise”. The sooner we begin to operate off a unified view of how to align, integrate, and leverage these oftentimes disjointed capabilities today, the faster an organization will leapfrog others in their ability to drive sustainable productivity, profitability, and competitive advantage.
Key Considerations
Create the Template for Delivery
My assumption is that we care about three things in transitioning to a future, integrated environment:
Rapid, predictable delivery of capabilities over time (speed-to-market, competitive advantage)
Optimized costs (minimal waste, value disproportionate to expense)
Seamless integration of new capabilities as they emerge (ease of use and optimized value)
What these three things imply is the need for a consistent, repeatable approach and a standard architecture towards which we migrate capabilities over time. Articles 2-5 of this series explore various dimensions of that conceptual architecture from an enterprise standpoint, the purpose here will be to focus in on approach.
As was discussed in the article on the overall framework, the key is to start the design of the future environment around the various consumers of technology, the capabilities being provided to them, now and in the future, and prioritizing the relative value of those capabilities over time. That should be done on an internal and external level, so that individual roadmaps can be developed by domain to eventually surface and provide those capabilities as part of a portfolio management process. In the course of identifying those capabilities, some key questions will be whether those capabilities are available today, involve some level of AI services, whether those can/should be provided through a third-party or internally, and whether the data ultimately exists to enable them. This is where a significant inflection point should occur: the delivery of those capabilities should follow a consistent approach and pattern, so it can be repeated, leveraged, and made more efficient over time.
For instance, if an internally-developed AI-enabled capability is needed, the way that the data is exposed, processed, the AI service (or data product) exposed, and integrated/consumed by a package or custom application should be exactly the same from a design standpoint, regardless of what the specific capability is. That isn’t to say that the work needs to be done by only one team, as will be explored in the final article on IT organizational implications, but rather that we ideally want to determine the best “known path” to delivery, execute that repeatedly, and evolve it as required over time.
Taking this approach should provide a consistent end-user experience of services as they are brought online over time, a relatively streamlined delivery process as you are essentially mass-producing capabilities over time, and a relatively cost-optimized environment as you are eliminating the bloat and waste of operating multiple delivery silos that will eventually impede speed-to-market at scale and lead to technical debt.
From an architecture standpoint, without wanting to go too deep into the mechanics here, to the extent that the current state and future state enterprise architecture models are different, it would be worth evaluating things like virtualization of data as well as adapters/facades in the integration layer as a way to translate between the current and future models so there is logical consistency in the solution architecture even where the underlying physical implementations are varied. Our goal in enterprise architecture should always be to facilitate rapid execution, but promote standards, simplification, and reduce complexity and technical debt wherever possible over time.
Govern Standards and Quality
With a templatized delivery model and target architecture in place, the next key aspect to transition is to both govern the delivery of new capabilities to identify opportunities to develop and evolve standards, as well as to evolve the “template” itself, whether that involves adding automation to the delivery, building reusable frameworks or components that can be leveraged, or other assets that can help reduce friction and ease future efforts.
Once new capabilities are coming online, the other key aspect is to review them for quality and performance, to also look for ways to evolve the approach, adjust the architecture, and continue to refine the understanding of how these integrated capabilities can best be delivered and leveraged on an end-to-end basis.
Again, the overall premise of this entire series of articles is to chart a path towards an integrated enterprise environment for applications, data, and AI in the future. To be repeatable, we need to be consistent in how we plan, execute, govern, and evolve in the delivery of capabilities over time.
Certainly, there will be learnings that come from delivery, especially early in the adoption and integration of these capabilities. The way that we establish and enable the governance and evolution stemming from what we learn is critical in making delivery more predictable and ensuring more useful capabilities and insights over time.
Evolve in a Thoughtful Manner
With our learnings firmly in hand, the mental model I believe would be worth considering is more of a scaled Agile-type approach, where we have “increment-level”/monthly scheduled retrospectives to review the learnings across multiple sprints/iterations (ideally across multiple product/domains) and to identify opportunities to adjust estimation metrics, design patterns, develop core/reusable services, and anything else that essentially would improve efficiency, cost, quality, or predictability.
Whether these occur monthly at the outset and eventually space out to a quarterly process as the environment and standards are better defined could depend on a number of factors, but the point is not to make it too reactive to any individual implementation and to try and look across a set of deliveries to look for consistent issues, patterns, and opportunities that will have a disproportionate impact on the environment as a whole.
The other key aspect to remember in relation to evolution is that the capabilities of AI in particular are evolving very rapidly at this point, which is also a reason for thinking about the overall architecture, separation of concerns, and standards for how you integrate in a very deliberate way. A new version of a tool or technology shouldn’t require us to have to rewrite a significant portion of our footprint, it ideally should be a matter of upgrading the previous version and having the new capabilities available everywhere that service is consumed or in swapping out one technology for another, but everything on the other side of an API remaining nearly unchanged to the extent possible. This is understood as a fairly “perfect world” description of what likely would happen in practice, depending on the nature of the underlying change, but the point is that, without allowing for these changes up front in the design, the level of disruption they cause will likely be amplified and slow overall progress.
Summing Up
Change is a constant in technology. It’s a part of life given that things continue to evolve and improve, and that’s a good thing to the extent that it provides us with the ability to solve more complex problems, create more value, and respond more effectively to business needs as they evolve over time. The challenge we face is in being disciplined enough to think through the approach so that we can become effective, fast, and repeatable. Delivering individual projects isn’t the goal, it’s delivering capabilities rapidly and repeatably, at scale, with quality. That’s an exercise in disciplined delivery.
Having now covered the technology and delivery-oriented aspects of the future state concept, the remaining article will focus on how to think about the organizational implications on IT.
Up Next: IT Organizational Implications
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
Does having more data automatically make us more productive or effective?
When I wrote the original article on “The Intelligent Enterprise”, I noted that the overall ecosystem for analytics needed to change. In many environments, data is moved from applications to secondary solutions, such as data lakes, marts, or warehouses, enriched and integrated with other data sets, to produce analytical outputs or dashboards to provide transparency into operating performance. Much of this is reactive and ‘after-the-fact’ analysis of things we want to do right or optimize the first time, as events occur. The extension of that thought process was to move those insights to the front of the process, integrate them with the work as it is performed, and create a set of “intelligent applications” that would drive efficiency and effectiveness to different levels than we’ve been able to accomplish before. Does this eliminate the need for downstream analytics, dashboards, and reporting? No, for many reasons, but the point is to think about how we can make the future data and analytics environment about establishing a model that enables insight-driven, orchestrated action.
This is the fifth post in a series focused on where I believe technology is heading, with an eye towards a more harmonious integration and synthesis of applications, AI, and data… what I previously referred to in March of 2022 as “The Intelligent Enterprise”. The sooner we begin to operate off a unified view of how to align, integrate, and leverage these oftentimes disjointed capabilities today, the faster an organization will leapfrog others in their ability to drive sustainable productivity, profitability, and competitive advantage.
Design Dimensions
In line with the blueprint above, articles 2-5 highlight key dimensions of the model in the interest of clarifying various aspects of the conceptual design. I am not planning to delve into specific packages or technologies that can be used to implement these concepts as the best way to do something always evolves in technology, while design patterns tend to last. The highlighted areas and associated numbers on the diagram correspond to the dimensions described below.
Starting with the Consumer (1)
“Just give me all the data” is a request that isn’t unusual in technology. Whether that is a byproduct of the challenges associated with completing analytics projects, a lack of clear requirements, or something else, these situations cause an immediate issue in practice: what is the quality of the underlying data and what are we actually trying to do with it?
It’s tempting to start an analytics effort from the data storage and to work our way up the stack to the eventual consumer. Arguably, this is a central premise in being “data-centric.” While I agree with the importance of data governance and management (the next topic), it doesn’t mean everything is relevant or useful to an end consumer, and too much data very likely just creates management overhead, technical complexity, and information overload.
A thoughtful approach needs to start with identifying the end consumers of the data, their relative priority, information and insights needs, and then developing a strategy to deliver those capabilities over time. In a perfect world, that should leverage a common approach and delivery infrastructure so that it can be provided in iterations and elaborated to include broader data sets and capabilities across domains over time. The data set should be on par with having an integrated data model and consistent way of delivering data products and analytics services that can be consumed by intelligent applications, agents, and solutions supporting the end consumer.
As an interesting parallel, it is worth noting that ChatGPT is looking to converge their reasoning and large language models from 4x into a single approach for their 5x release so that end customers don’t need to be concerned with having selected the “right” model for their inquiry. It shouldn’t matter to the data consumer. The engine should be smart enough to leverage the right capabilities based on the nature of the request, and that is what I am suggesting in this regard.
Data Management and Governance (2)
Without the right level of business ownership, the infrastructure for data and analytics doesn’t really matter, because the value to be obtained from optimizing the technology stack will be limited by the quality of the data itself.
Starting with master data, it is critical to identify and establish data governance and management for the critical, minimum amount of data in each domain (e.g., customer in sales, chart of accounts in finance), and the relationship between those entities in terms of an enterprise data model.
Governing data quality has a cost and requires time, depending on the level of tooling and infrastructure in place, and it is important to weigh the value of the expected outcomes in relation to the complexity of the operating environment overall (people, process, and technology combined).
From Content to Causation (3)
Finally, with the level of attention given to Generative AI and LLMs, it is important to note the value to be realized when we shift our focus from content to processes and transactions in the interest of understanding causation and influencing business outcomes.
In a manufacturing context, the increasing level of interplay between digital equipment, digital sensors, robotics, applications, and digital workers, there is a significant opportunity to orchestrate, gather and analyze increasing volumes of data, and ultimately optimize production capacity, avoid unplanned events, and increase the safety and efficacy of workers on the shop floor. This requires deliberate and intentional design, with outcomes in mind.
The good news is that technologies are advancing in their ability to analyze large data sets and derive models to represent the characteristics and relationships across various actors in play and I believe we’ve only begun to scratch the surface on the potential for value creation in this regard.
Summing Up
Pulling back to the overall level, data is critical, but it’s not the endgame. Designing the future enterprise technology environment is about exposing and delivering the services that enable insightful, orchestrated action on behalf of the consumers of that technology. That environment will be a combination of applications, AI, and data and analytics, synthesized into one meaningful, seamless experience. The question is how long it will take us to make that possible. The sooner we begin the journey of designing that future state with agility, flexibility, and integration in mind, the better.
Having now elaborated the framework and each of the individual dimensions, the remaining two articles will focus on how to approach moving from the current to future state and how to think about the organizational implications on IT.
Up Next: Managing Transition
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.