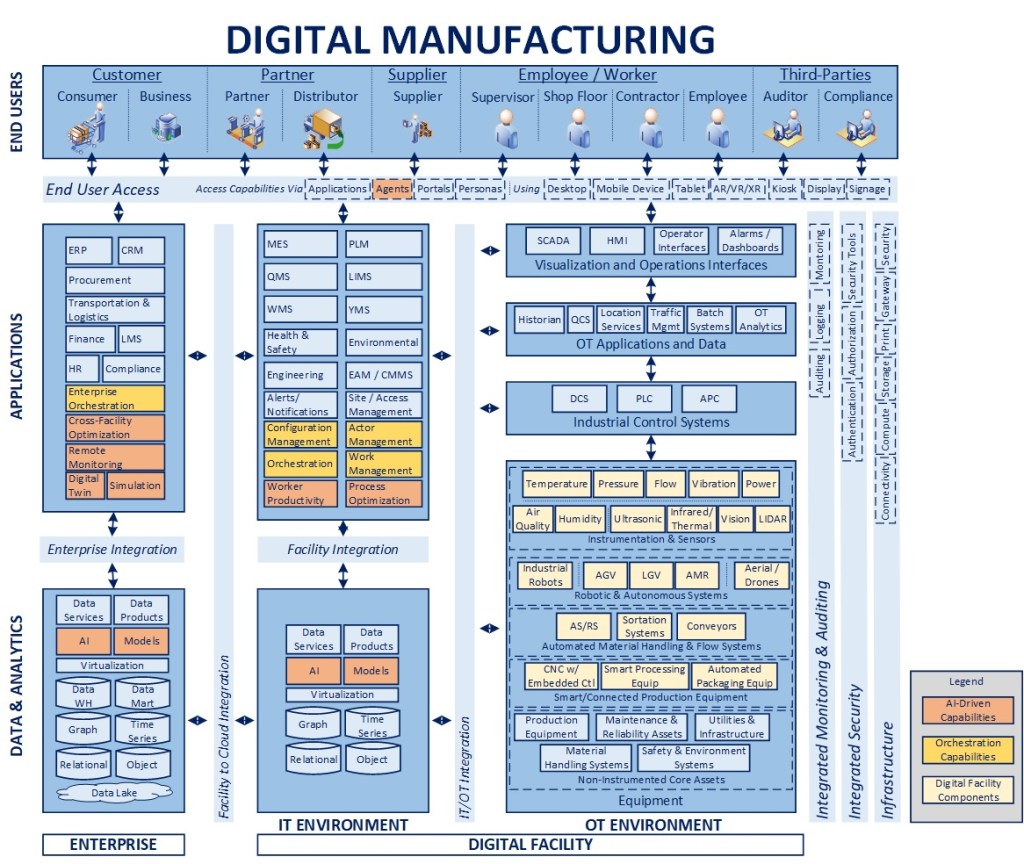
What It Is: Creating a digitally connected manufacturing environment that enables modernization and optimization requires a clear integration strategy that can align, leverage, and synthesize new and existing elements in a thoughtful and deliberate way
Why It Matters: It is often the case that we are in a “brownfield” environment where we don’t have the opportunity to “start from scratch” when it comes to modernization because of the sunk cost that exists in facilities across an enterprise. By leveraging strategic integration, we maximize existing investments, provide resiliency, and create agility that will more rapidly generate ROI on new investments over time
Key Concepts
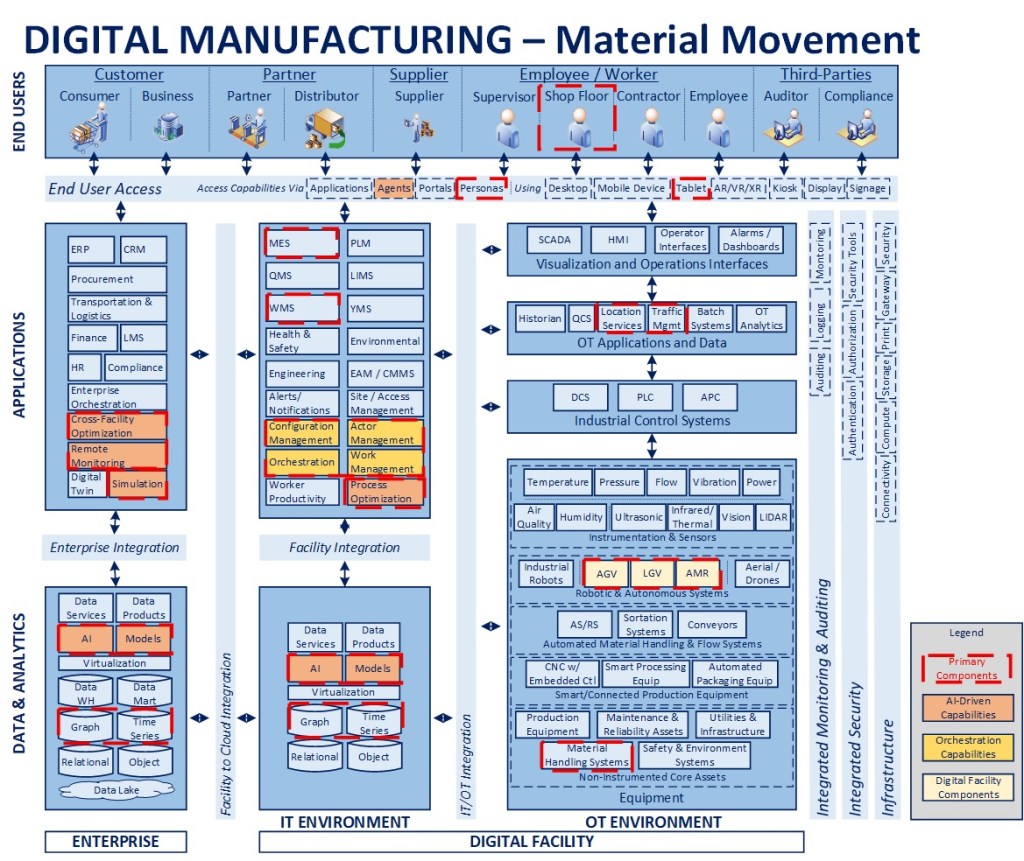
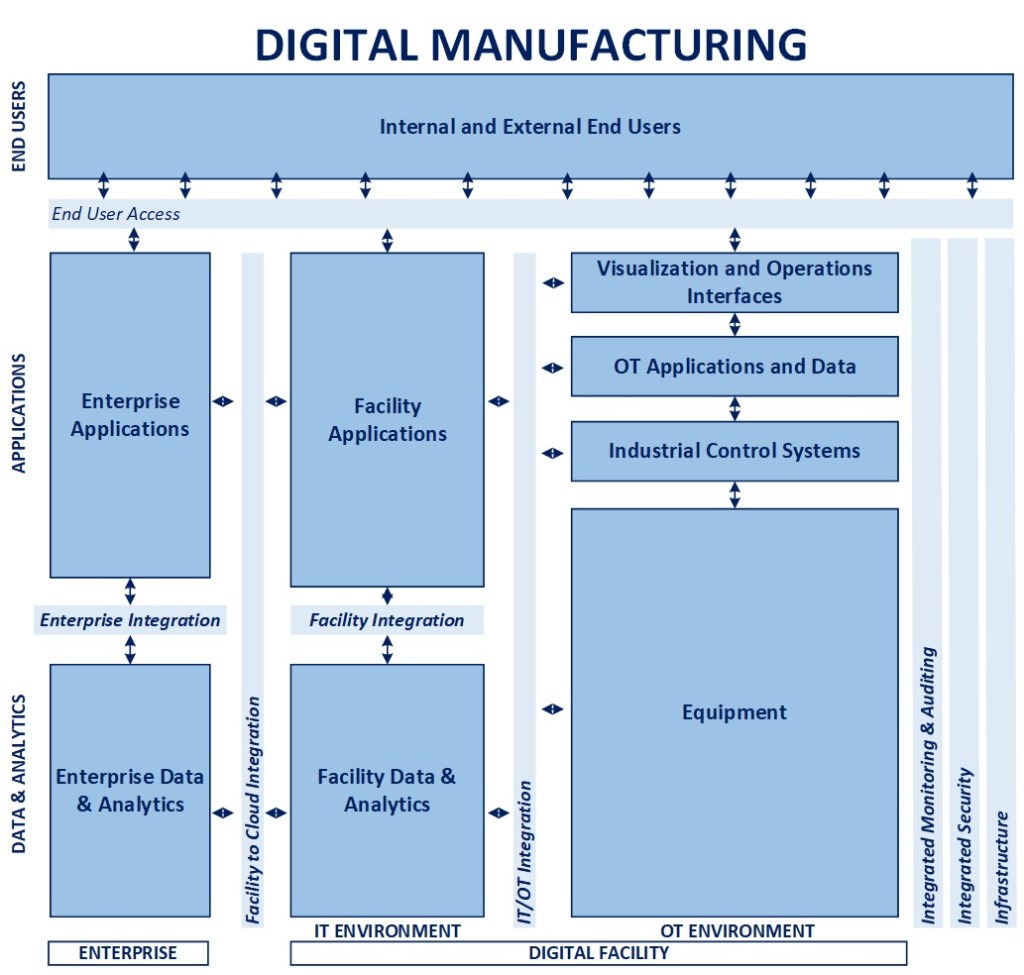
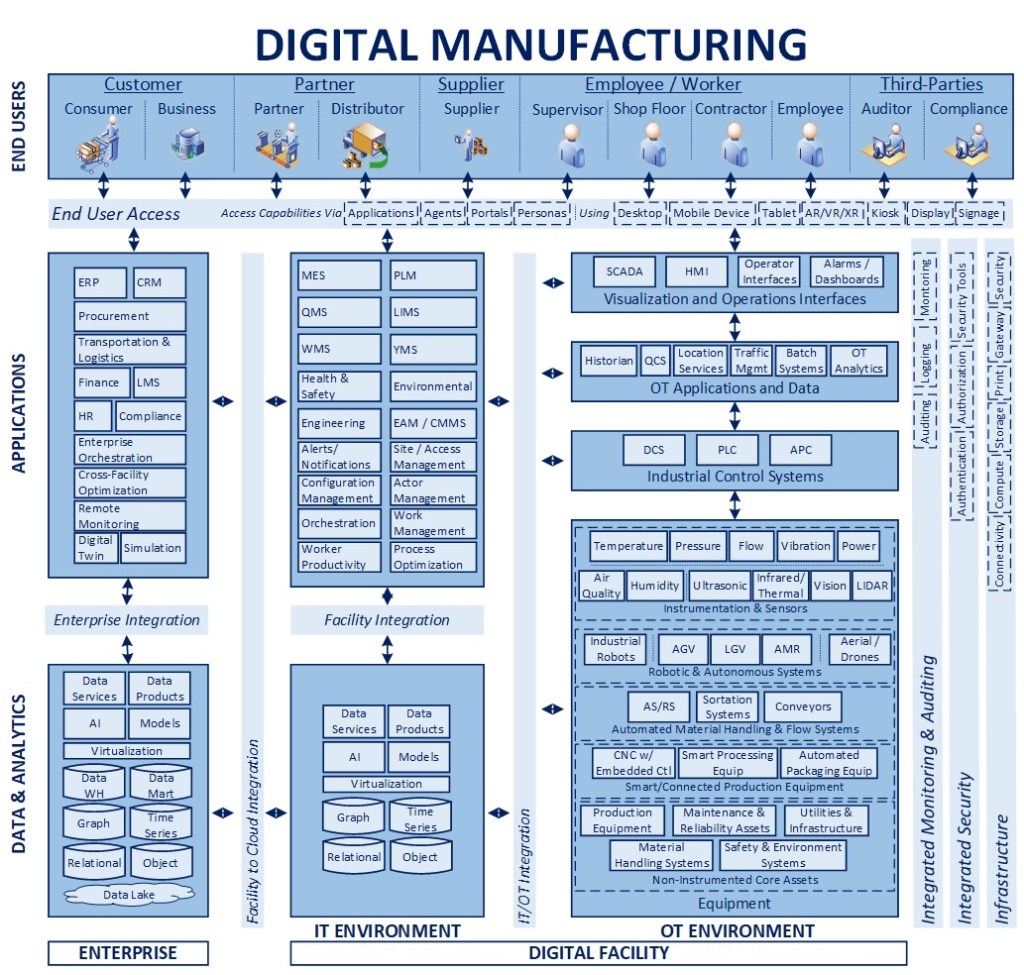
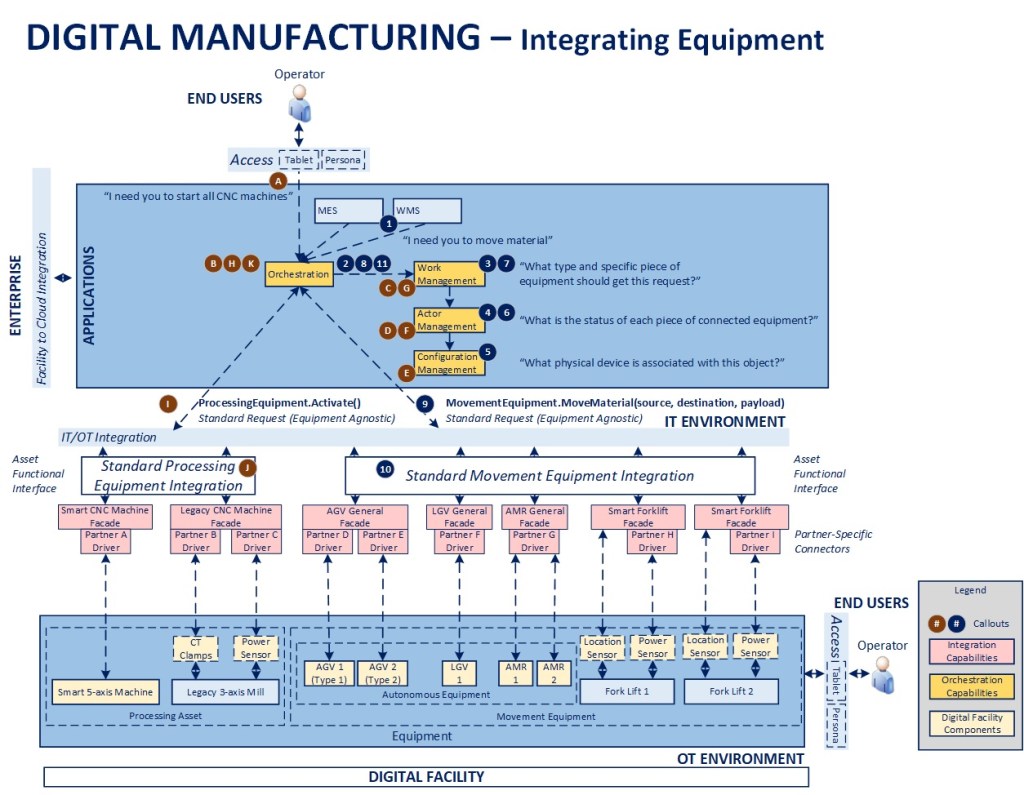
The above diagram will be used as a reference for the remainder of this article. I have specifically left out facility data and enterprise components to focus largely on configuration management and integration. To understand the blueprint overall and concepts related to orchestration, please see the links at the bottom of this article. As there are many levels to this topic, I will focus on the main points in the interest of communicating the concepts overall.
- Framework-Driven Design – The foundation of the overall blueprint is the premise that manufacturing facilities can be treated as a configuration of logical components that can be managed through orchestration as part of a digitally connected ecosystem
- Building the right bridges – Considerable integration is built on a point-to-point basis, hard-wiring one component to the next, making things brittle, adding maintenance cost, and making change extremely difficult. The goal in this approach is to identify processes where value can be created, selectively moving from a hard-wired to a model-driven integration approach that maximizes existing investments, increasing resiliency, and promotes longer-term agility
- Wrap existing assets – To the maximum extent possible, accelerate the modernization process by instrumenting and adding a digital wrapper around legacy equipment to allow it to integrate seamlessly with more modern digital capabilities and equipment
- Standardize integration – Create an Asset Functional Interface (AFI) that establishes a “manage-by-contract” environment where APIs and data exchanged are standardized to insulate the central orchestration framework from the underlying equipment executing the instructions. These standards then enable a much more plug-and-play and “certified” environment where partner components can be aligned to the specs, deemed compliant, and integrated more rapidly and seamlessly over time
- Leveraging a Unified Namespace (UNS) – Pivoting from a hard-wired to a more standardized integration architecture also creates the opportunity to shift relevant transactions towards a more modern, event-driven architecture that is more resilient and plug-and-play, where messaging and data standards can evolve over time, leveraging a topic structure that is partner-neutral and allows for ongoing modernization
- Layered integration – Equipment integration itself is accomplished first through a set of façades that are configured to expose and subscribe to the relevant portions of the AFI for a specific piece of connected equipment. There is then a secondary layer of partner-specific drivers that provide for any additional data transformation required across various partner-specific devices or versions of devices that may be in place over time. One important point to note from an implementation standpoint is to consider the latency involved in data publication across equipment, as downstream analytics will need a relatively consistent baseline to benchmark operating metrics. Overall, the goal would be to have streaming data available as close to “near-real-time” regardless of the integration pattern as possible
- Providing standardization in a non-standard world – By decoupling, integrating, and orchestrating high value processes between core systems and across critical assets, we create a strategic, reusable set of infrastructure assets that can work with new and old equipment, across facilities, and that can also be integrated with one or more ERP, MES, WMS, EAM, and other systems that may be in place across a heterogeneous facilities environment. The speed-to-market for delivering new capabilities and ROI on investments associated with this level of reusable infrastructure is considerably higher over time than working within the highly constrained, tightly coupled and diverse environments in place across many manufacturing organizations today
- Enabling agentic integration – Moving to an API-centric environment that supports orchestration for critical, high value operations sets the stage for agentic integration for operators and end users. Agents can only initiate and orchestrate processes and transactions that are exposed, and putting this core infrastructure in place would be a stepping stone towards an enterprise-ready agentic infrastructure environment within manufacturing facilities
Key Components
While the previous article on the power of orchestration covers the conceptual role of these components, I wanted to review these four in the interest of setting up the two example scenarios that will follow:
- Configuration Management – Foundational to the model is the concept that each facility will have an asset registry that serves as the single source of truth on all connected components and key characteristics that are necessary to leverage them as part of a digitally connected and orchestrated ecosystem. This asset registry then acts as a conceptual facility DNS that helps map the logical entities to the physical environment for the purposes of enabling orchestration. Example attributes would be the logical component type, specific type of underlying equipment, product manufacturer and associated version (as appropriate), any connected devices (e.g., a legacy forklift may have multiple smart devices connected to it), etc.
- Actor Management – Once assets are registered and connected via Configuration Management, this component keeps the active state of all equipment, whether it is in service, requires maintenance, is awaiting work, its current workload/request queue, telemetry data, etc.
- Work Management – This component acts as an intelligent dispatcher, defining rules for what equipment should be used to accomplish different tasks based on status provided by Actor Management and various operating conditions associated with the request. For example, only forklifts are used to service requests for certain zones in a warehouse, or in the event that no AMRs are available in a given zone to process requests, a forklift is automatically dispatched as a secondary approach to minimize production downtime
- Orchestration – This is the “brains” of the facility, driving and coordinating critical processes, ensuring service-level assumptions are met, and that desired outcomes are achieved, leveraging work management to assign tasks that are part of configured workflows
Two Examples
In the interest of showing the relationships across components from a process standpoint, here are two simplified examples (I’m not trying to call out all the technical detail or steps, just the base concepts).
Start Up
First, assume that there are two CNC machines in a facility, one older piece of equipment and one smart CNC machine. The legacy machine is fitted with a “digital backpack” of sensors and a gateway and registered, along with the smart CNC machine, so that they appear as two devices in the facility configuration. Their state is tracked in the Actor Management component on a continual basis.
Scenario 1 – There was a recent shutdown and an operator wants to restart all connected CNC equipment (STEPS A-K in the diagram)
- The operator initiates a request though their connected device (assuming their persona has the necessary permissions)
- The request is published and received by the Orchestration component, which initiates a start up process. The first step is to publish a request for all stopped CNC machines
- Work Management receives the request and publishes a request for a list of all stopped CNC machines
- Actor Management receives the request and publishes a request for all registered CNC machines that is received by Configuration Management
- Configuration Management receives the request, interrogates its data store and publishes the list of connected machines back to the facility message bus
- Actor Management receives the message and checks the list against those machines presently represented in its facility model, creating new objects as required for missing items, and publishing the list of machines showing a status of “stopped” back to the queue
- Work Management receives the list, checks for any safety interlocks or other operating conditions present that would prevent starting up each item in the list, then publishes the resulting set of items back to the queue
- The Orchestrator receives the list and then sequentially processes each item
- The Orchestrator sends a standard Activate message
- The message is processed by the Façade for each piece of equipment and a result is provided in response to the request. If the machine doesn’t have the capability for an automated restart, a message is sent to the appropriate Operator via the connected worker environment to perform the activity manually
- The Orchestrator checks for any error conditions, notifies an operator and/or supervisor if required, then moves to the next piece of equipment until the process is complete. When the process is completed successfully, the transactional performance data is recorded and the workflow is completed
In an agentic future, the entire process above could be issued via voice command through a connected worker solution, including potentially remotely (depending on the infrastructure in place).
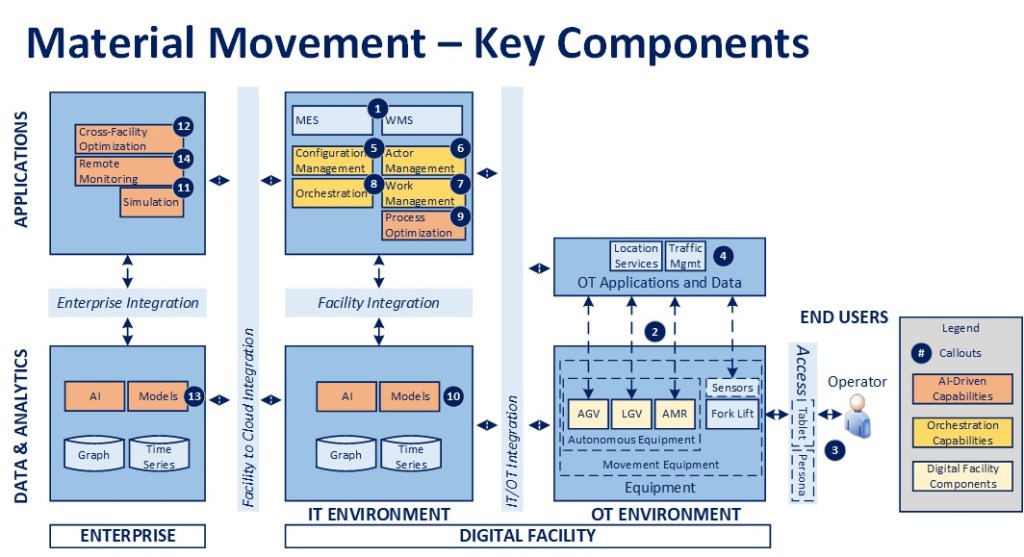
Material Movement
Second, assume that there is a fleet of material movement equipment in a facility, from 20-year-old forklifts to modern AMRs. The legacy forklifts are fitted with a “digital backpack” of sensors and a gateway and registered, along with the rest of the autonomous equipment, so that they appear as active devices in the facility configuration. Their state is tracked in the Actor Management component on a continual basis.
Scenario 2 – There is a need to move materials in the facility (STEPS 1-11)
- The MES or WMS system publishes a MoveMaterial request
- The Orchestrator receives the request, initiates a material move workflow, and publishes a request to identify the appropriate piece of equipment to service it
- Work Management receives the request, evaluates any associated conditions (e.g., location, work zone) and publishes a request to identify all equipment of the correct type (could be one or more), along with their present status, to perform the activity
- Actor Management receives the request and publishes a request for a list of all registered equipment of the specified type(s)
- Configuration Management receives the request, interrogates its data store and publishes the list of connected equipment back to the facility message bus
- Actor Management receives the message and checks the list against the equipment presently represented in its model, creating new objects as required for missing items, and publishing the list of movement equipment along with their individual status back to the message bus
- Work Management receives the list and, based on configured dispatching rules, publishes an ordered list of equipment to service the request
- Orchestration receives the list and starts with the first piece of equipment provided in the list
- Orchestration sends a standard MoveMaterial request to initiate action
- The message is processed by the Façade for the appropriate piece of equipment and a result is provided in response to the request. If the work was directed at a forklift, a message is sent to the appropriate Operator via the connected worker environment to perform the activity
- The Orchestrator checks for any error conditions. If the task assignment wasn’t completed or wasn’t taken up within a pre-defined OLA, it cancels that request, moves to the next piece of equipment in the list, and sends a new request, until the process is complete. If the task is completed successfully, the transactional performance data is recorded and material move workflow is completed
Wrapping Up
Hopefully, the above examples provide a reasonable understanding of the nature of the interactions across the core framework for orchestration and value of having a decoupled and abstracted approach to integration. Simply said: the orchestrator manages the SLAs and high value outcomes, but it isn’t concerned with the physical equipment used to support its workflows. That separation of concerns creates an incredible amount of flexibility and resiliency, particularly in the mixed environment that exists across many manufacturing organizations today.
For Additional Information: InPractice: Digital Manufacturing – The Blueprint, InPractice: Digital Manufacturing – The Power of Orchestration, InBrief: Defining Manufacturing Maturity
Excellence doesn’t happen by accident. Courageous leadership is essential.
Put value creation first, be disciplined, but nimble.
Want to discuss more? Please send me a message. I’m happy to explore with you.
-CJG 03/31/2026