Why does it take so much time to do anything strategic?
This not an uncommon question to hear in technology and, more often than not, the answer is relatively simple: because the focus in the organization is delivering projects and not establishing an environment to facilitate accelerated delivery at scale. Those are two very different things and, unfortunately, it requires more thought, partnership, and collaboration between business and technology teams than headlines like “let’s implement product teams” or “let’s do an Agile transformation” imply. Can those mechanisms be part of how you execute in a scaled environment? Absolutely, but choosing an operating approach and methodology shouldn’t precede or take priority over having a blueprint to begin with, and that’s the focus of this article.
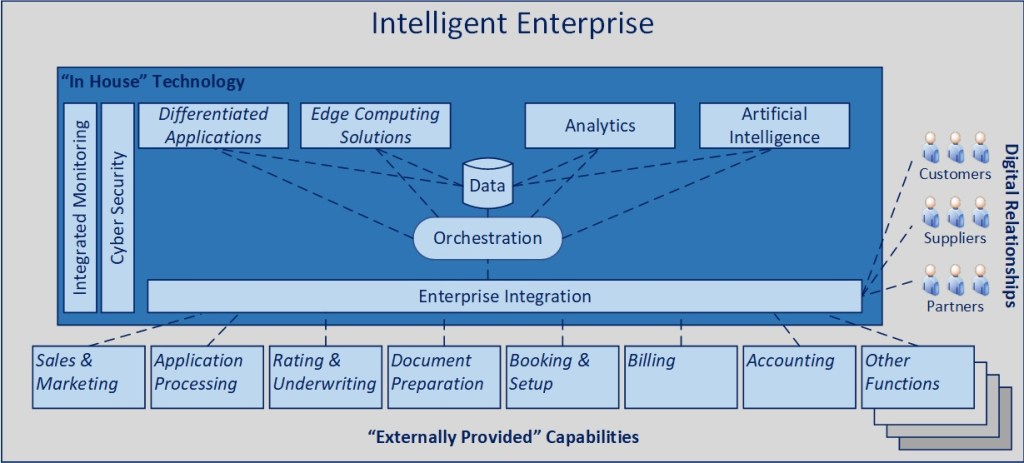
This is the second post in a series focused on where I believe technology is heading, with an eye towards a more harmonious integration and synthesis of applications, AI, and data… what I previously referred to in March of 2022 as “The Intelligent Enterprise”. The sooner we begin to operate off a unified view of how to align, integrate, and leverage these oftentimes disjointed capabilities today, the faster an organization will leapfrog others in their ability to drive sustainable productivity, profitability, and competitive advantage.
Design Dimensions
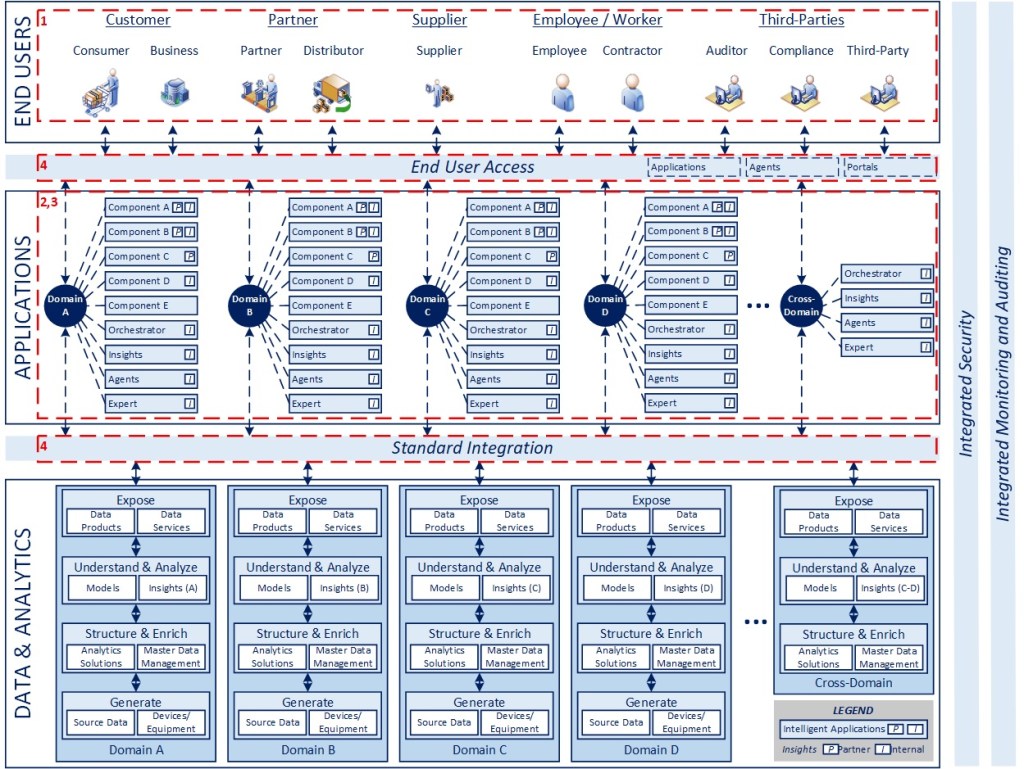
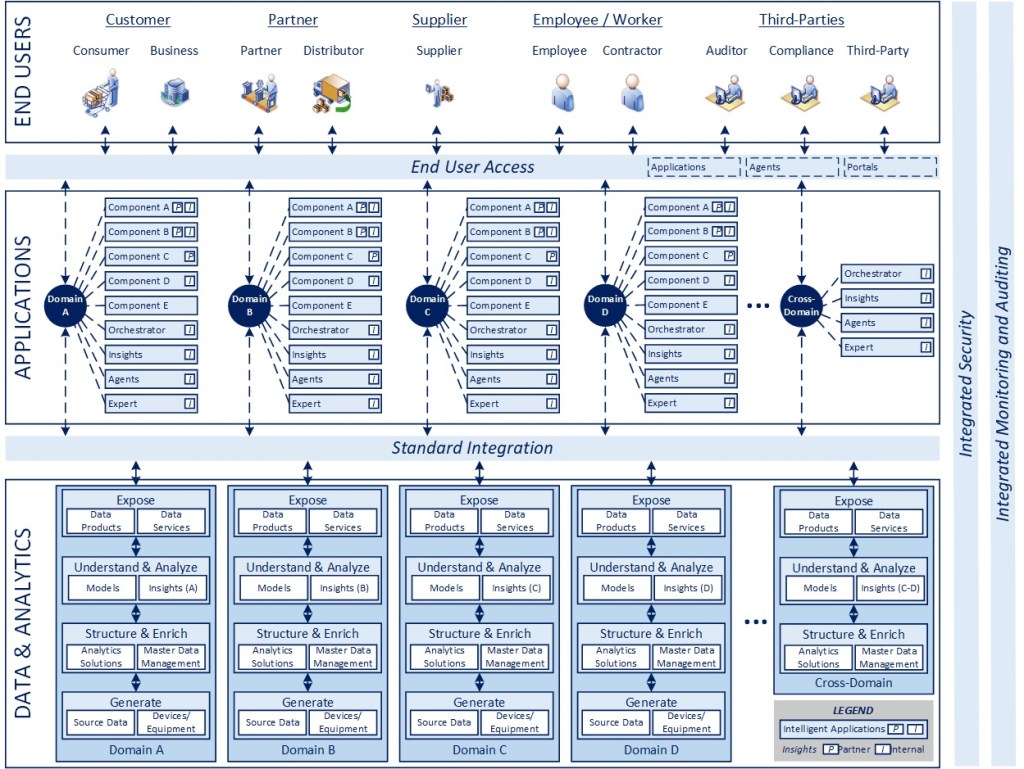
In line with the blueprint above, articles 2-5 highlight key dimensions of the model in the interest of clarifying various aspects of the conceptual design. I am not planning to delve into specific packages or technologies that can be used to implement these concepts as the best way to do something always evolves in technology, while design patterns tend to last. The highlighted areas and associated numbers on the diagram correspond to the dimensions described below.
User-Centered Design (1)
A firm conducts a research project on behalf of a fast-food chain. There is always a “coffee slick” in the drive thru, where customers stop and pour out part of their beverage. Is there something wrong with the coffee? No. Customers are worried about burning themselves. The employees are constantly overfilling the drink, assuming that they are being generous, but actually creating a safety concern by accident. Customers don’t want to spill their coffee, so that excess immediately goes to waste.
In the world of technology, the idea of putting enabling technology in the hands of “empowered” end users or delivering that one more “game changing” tool or application is tempting, but often doesn’t deliver the value that is originally expected. This can occur for a multitude of reasons, but what can often be the case is an inadequate understanding of the end user’s mental model, approach to performing their work, or a fundamental misunderstanding that more technology in the hands of a user is always a good thing (when it definitely isn’t the case).
Two learnings that came out of the dotcom era were, first, the value to be derived from investing in user-centered design, thinking through their needs and workflow, and designing experiences around that. The other common practice was assuming that a disruptive technology (the internet in this case) was cause to spin out a separate organization (the “eBusiness” teams of the time) meant to incubate and accelerate development of capabilities that embraced the new technology. These teams generally lacked a broader understanding of the “traditional” business and its associated operating requirements, and thus began the ”bricks versus clicks” issues and channel conflict that eventually led to these capabilities being folded back into the broader organization, but only after having spent time and (in many cases) a considerable amount of money experimenting without producing sustainable business value.
In the case of artificial intelligence, it’s tempting to want to stand up new organizations or repurpose existing ones to mobilize the technology or to assume everything will eventually be relegated to a natural language-based interface where a user provides a description of what they want into an agent acting at their personal virtual assistant, with system deriving the appropriate workflow and orchestrating the necessary actions to support the request. While that may be a part of our future reality, taking an approach similar to the dotcom era would be a mistake and there will lost opportunity where this is the chosen path.
To be effective in a future digital world with AI, we need to think of how we want things integrated at the outset, starting with that critical understanding of the end user and how they want to work. Technology is meant to enable and support them, not the other way around, and leading with technology versus a need is never going to be an optimal approach… a lesson we’ve been shown many times over the years, no matter how disruptive the technology advancement has been.
I will address some of the organizational implications of the model in the seventh article in this series, so the remainder of this post will be on the technology framework itself.
Designing Around Connected Ecosystems (2)
Domain-driven design is not a new concept in technology.
As I mentioned in the first article, the technology footprint of most medium- to large-scale organizations is complex and normally steeped in redundancies, varied architectures, unclear boundaries between custom and purchased software, hosted and cloud-based based environments, hard coded integrations, and standard ways of moving data within and across domains.
While package solutions offer some level of logical separation of concerns between different business capabilities, the natural tendency in the product and platform space is to move towards more vertically or horizontally integrated solutions that create customer lock in and make interoperability very challenging, particularly in the ERP space. What also tends to occur is that an organization’s data model is biased to conform to what works best for a package or platform, but not necessarily the best representation of their business or their consumers of technology (something I will address in article 5 on Data & Analytics).
In terms of custom solutions, given they are “home grown”, there is a reasonable probability that, unless they were well-architected at the outset, they very likely provide multiple capabilities, without clear separation of concerns in ways that make them difficult to integrate with other systems in “standard” ways.
While there is nothing unique about these kinds of challenges, the problem comes when new technology capabilities like AI are available and we want to either replace or integrate things in a different way. This is where the lack of enterprise-level design and a broader, component-based architecture takes its toll, because there likely will be significant remediation, refactoring, and modernization required to enable existing systems to interoperate with the new capabilities. These things take time, add risk, and ultimately cost to our ability to respond when these opportunities arise, and no one wants to put new plumbing in a house that is already built with a family living in it.
On the other hand, in an environment with defined, component-based ecosystems that uses standard integration patterns, replacing individual components becomes considerably easier and faster, with much less disruption at both a local- and an enterprise-level. In a well-defined, component-based environment, I should be able to replace my Talent Acquisition application without having to impact my Performance Management, Learning & Development, or Compensation & Benefits solutions from an HR standpoint. Similarly, I shouldn’t need to make changes to my Order Management application within my Sales ecosystem because I’m transitioning to a different CRM package. To the extent that you are using standard business objects to support integration across systems, the need to update downstream systems in other domains should be minimized as well. Said differently, if you want to be fast, be disciplined in your design.
Modular, Composable, Standardized (3)
Beyond designing towards a component-based environment, it is also important to think about capabilities independent of a given process so you have more agility in how you ultimately leverage and integrate different things over time.
Using a simple example from personal lines insurance, I want to be able to support a third-party rating solution by exposing a “GetQuote” function that takes necessary customer information and coverage-related parameters and sends back a price. From a carrier standpoint, the process may involve ordering credit and pulling a DMV report (for accidents and violations) as inputs to the process. I don’t necessarily want these capabilities to be developed internal to the larger “GetQuote”, because I may want to leverage them for any one of a number of other reasons, so that smaller grained (more atomic) transactions should also be defined as services that can be leveraged by the larger one. While this is a fairly trivial case, there are often situations where delivery efforts move at such a rapid pace that things are tightly coupled or built together that really should be discreet and separate, providing more flexibility and leverage of those individual services over time.
This also can occur in the data and analytics space, where there are normally many different tools and platforms between the storage and consumption layers and ideally you want to optimize data movement and computing resources such that only the relevant capabilities are included in a data pipeline based on specific customer needs.
The flexibility described above is predicated on a well-defined architecture that is service-based and composable, with standard integration patterns, that leverages common business objects for as many transactions as practical. That isn’t to say that there are times where the economics make sense to custom code something or to leverage point-to-point integration, rather that thinking about reuse and standardized approaches up front is a good delivery practice to avoid downstream cost and complexity, especially when the rate of new technologies being introduced is as high as it is today.
Leveraging Standard Integration (4)
Having mentioned standard integration above, my underlying assumption is that we’re heading towards a near real-time environment where streaming infrastructure and publish and subscribe models are going to be critical infrastructure to enable delivery of key insights and capabilities to consumers of technology. To the extent that we want that infrastructure to scale and work efficiently and consistently, there is a built-in incentive to be intentional about the data we transmit (whether that is standard business objects or smaller data sets coming from connected equipment and devices) as well as the ways we connect to these pipelines across application and data solutions. Adding a data publisher or consumer shouldn’t require rewriting anything per se, any more than plugging in a new appliance to a power outlet in your home should require you to either unplug something else or change the circuit board and wiring itself (except in extreme cases).
Summing Up
I began this article with the observation about delivering projects by comparison with establishing an environment for delivering repeatably at scale. In my experience, depending on the scale of an organization, there will be some level of many of the things I’ve mentioned above in place, but then a potentially large set of pain points and opportunities across the footprint where things are suboptimized.
This is not about boiling the ocean or suggesting we should start over. The point of starting with the framework itself is to raise awareness that the way we establish the overall environment has a significant ripple effect into our ability to do things we want to do downstream to leverage new capabilities and get the most out of our technology investments later on. The time spent in design is well worth the investment, so long as it doesn’t become analysis paralysis.
To that end, in summary:
Design from the end user and their needs first
Think and design with connected ecosystems in mind
Be purposeful in how you design and layer services to promote reuse and composability
Leverage standards in how you integrate solutions to enable near real-time processing
It is important to note that, while there are important considerations in terms of hosting, security, and data movement across platforms, I’m focusing largely on the organization and integration of the portfolios needed to support an organization. From a physical standpoint, the conceptual diagram isn’t meant to suggest that any or all of these components or connected ecosystems need to be managed and/or hosted internal to an organization. My overall belief is that, the more we move to a service-driven environment, the more of a producer/consumer model will emerge where corporations largely act as an integrator and orchestrator (aka “consumer”) of services provided by third-parties (the “producers”). To the extent that the architecture and standards referenced above are in place, there shouldn’t be any significant barriers to moving from a more insourced and hosted environment to a more consumption-based, outsourced, and cloud-native environment in the future.
With the overall framework in place, the next three articles will focus on the individual elements of the environment of the future, in terms of AI, applications, and data.
Up Next: Integrating Artificial Intelligence
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
The challenges involved in managing a technology footprint today at any medium to large organization are very high for a multitude of reasons:
Proliferation of technologies and solutions that are disconnected or integrated in inconsistent ways, making simplification or modernization efforts difficult to deliver
Mergers and acquisitions that bring new systems into the landscape that aren’t rationalized with or migrated to existing systems, creating redundancy, duplication of capabilities, and cost
“Speed-to-market” initiatives involving unique solution approaches that increase complexity and cost of ownership
A blend of in-house and purchased software solutions, hosted across various platforms (including multi-cloud), increasing complexity and cost of security, integration, performance monitoring, and data movement
Technologies advancing at a rate, especially with the introduction of artificial intelligence (AI), that organizations can’t integrate them quickly enough to do so in a consistent manner
Decentralized or federated technology organizations that operate with relative autonomy, independent of standards, frameworks, or governance, which increases complexity and cost
The result of any of the above factors can be enough cost and complexity that the focus within a technology organization can shift from innovation and value creation to struggling to keep the lights on and maintaining a reliable and secure operating environment.
This article will be the first in a series focused on where I believe technology is heading, with an eye towards a more harmonious integration and synthesis of applications, AI, and data… what I previously referred to in March of 2022 as “The Intelligent Enterprise”. The sooner we begin to operate off a unified view of how to align, integrate, and leverage these oftentimes disjointed capabilities today, the faster an organization will leapfrog others in their ability to drive sustainable productivity, profitability, and competitive advantage.
Why It Matters
Before getting into the dimensions of the future state, I wanted to first clarify how these technology challenges manifest themselves in meaningful ways, because complexity isn’t just an IT problem, it’s a business issue, and partnership is important in making thoughtful choices in how we approach future solutions.
Lost Productivity
A leadership team at a manufacturing facility meets first thing in the morning. It is the first of multiple they will have throughout the course of a day. They are setting priorities for the day collectively because the systems that support them: a combination of applications, analytics solutions, equipment diagnostics, and AI tools, are all providing different perspectives on priorities and potential issues, but in disconnected ways, and it is now on the leadership team to decide which of these should receive attention and priority in the interest of making their production targets for a day. Are they making the best choices in terms of promoting efficiency, quality, and safety? There’s no way to know.
Is this an unusual situation? Not at all. Today’s technology landscape is often a tapestry of applications with varied levels of integration and data sharing, data apps and dashboards meant to provide insights and suggestions, and now AI tools to “assist” or make certain activities more efficient for an end user.
The problem is what happens when all these pieces end up on someone’s desktop, browser, or mobile device and they are left to copy data from one solution to the other, arbitrate which of various alerts and notifications is most important, identify dependencies to help make sure they are taking the right actions in the right sequence (in a case like directed work activity), and quite often that time is lost productivity in itself, regardless of which path they take, which may amplify the impact further, given retention and/or high turnover are real issues in some jobs that reduce the experience available to navigate these challenges successfully.
Lower Profitability
The result of this lost productivity and ever-expanding technology footprint is both lost revenue (to the extent it hinders production or effective resource utilization) and higher operating cost, especially to the degree that organizations introduce the next new thing without retiring or replacing what was already in place, or integrating things effectively. Speed-to-market is a short-term concept that tends to cause longer-term cost of ownership issues (as I previously discussed in the article “Fast and Cheap Isn’t Good”), especially to the degree that there isn’t a larger blueprint in place to make sure such advancements are done in a thoughtful, deliberate manner.
To this end, how we do something can be as important as what we intend to do, and there is an argument for thinking through the operating implications when undertaking new technology efforts with a more holistic mindset than a single project tends to take in my experience.
Lost Competitive Advantage
Beyond the financial implications, all of the varied solutions, accumulated technologies and complexity, and custom or interim band aids built to connect one solution to the next eventually catches up in a form of what one organization used to refer to as “waxy buildup” that prevents you from moving quickly on anything. What seems on paper to be a simple addition or replacement becomes a lengthy process of analysis and design that is cumbersome and expensive, where the lost opportunity is speed-to-market in an increasingly competitive marketplace.
This is where the new market entrants thrive and succeed, because they don’t carry the legacy debt and complexity of entrenched market players who are either too slow to respond or too resistant to change to truly transform at a level that allows them to sustain competitive advantage. Agility gives way to a “death by a thousand paper cuts” of tactical decisions made that were appropriate and rational in the moment, but created significant amounts of technical debt that inevitably must be paid.
A Vision for the Future
So where does this leave us? Pack up the tent and go home? Of course not.
We are at a significant inflection point with AI technology that affords us the opportunity to examine where we are and to start adjusting our course to a more thoughtful and integrated future state where AI, applications, and data and analytics solutions work in concert and harmony with each other versus in a disconnected reality of confusion.
It begins with the consumers of these capabilities, supported by connected ecosystems of intelligent applications, enabled by insights, agents, and experts, that infuse intelligence into making people productive, businesses agile and competitive, and improve value derived from technology investments at a level disproportionate to what we can achieve today.
The remaining articles in this series will focus on various dimensions of what the above conceptual model means, as a framework, in terms of AI, applications, and data, and then how we approach that transition and think about it from an IT organizational perspective.
Up Next: Establishing the Framework for the future…
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
Having led and participated in many workshops and facilitated sessions over time, I wanted to share some thoughts on what tends to make them effective.
Unfortunately, there can be a perception that assembling a group of people in a room with a given topic (for any length of time) can automatically produce collaboration and meaningful outcomes. This is definitely not the case.
Before getting into the key dimensions, I suppose a definition of a “workshop” is worthwhile, given there can be many manifestations of what that means in practice. From my perspective, a workshop is a set of one or more facilitated sessions of any duration with a group of participants that is intended to foster collaboration and produce a specified set of outcomes. By this definition, a workshop could be as short as a one-hour meeting and also span many days. The point is that it is facilitated, collaborative, and produces results.
By this definition, a meeting used to disseminate information is not a workshop. A “training session” could contain a workshopcomponent, to the degree there are exercises that involve collaboration and solutioning, but in general, they would not be considered workshops because they are primarily focused on disseminating information.
Given the above definition, there are five factors that are necessary for successful workshop:
Demonstrating Agility and Flexibility
Having the Appropriate Focus
Ensuring the Right Participation
Driving Engagement
Creating Actionable Outcomes
Demonstrating Agility and Flexibility
Workshops are fluid, evolving things, where there is an ebb and flow to the discussion and to the energy of the participants. As such, beyond any procedural or technical aspect of running a workshop, it’s critically important to think about and to be aware of the group dynamics and to adjust the approach as needed.
What works:
Soliciting feedback on the agenda, objectives, and participants in advance, both to make adjustments as needed, but also to identify potential issues that could arise in the session itself
Doing pulse checks on progress and sentiment throughout to identify adjustments that may be appropriate
Asking for feedback after a session to identify opportunities for improvement in the future
What to watch out for:
The tone of discussion from participants, level of engagement, and other intangibles can tend to signal that something is off in a session
Tactics to address: Call a break, pulse check the group for feedback
Topics or issues not on the agenda that arise multiple times and have a relationship to the overall objectives or desired outcomes of the session itself
Tactics to address: Adjusting the agenda to include a discussion on the relevant topic or issue. Surface the issue, put in a parking lot to be addressed either during or post-session
Priorities or precedence order of topics not aligning in practice to how they are organized in the session agenda
Tactics to address: Reorder the agenda to align the flow of discussion to the natural order of the solutioning. Insert a segment to provide a high-level end-to-end structure, then resume discussing individual topics. Even if out of sequence, that could help contextualize the conversations more effectively
Having the Appropriate Focus
Workshops are not suitable for every situation. Topics that involve significant amounts of research, rigor, investigation, cross-organizational input, or don’t require a level of collaboration, such as detailed planning, are better handled through offline mechanisms, where workshops can be used to review, solicit input, and align outcomes from a distributed process.
What works:
Scope that is relatively well-defined, minimally at a directional level, to enable brainstorming and effective solutioning
Conduct a kick off and/or provide the participants with any pre-read material required for the session up front, along with any expectations for “what to prepare” so they can contribute effectively
Choosing topics where the necessary expertise is available and can participate in the workshop
What to watch out for:
Unclear session objectives or desired outcomes
Tactics to address: Have a discussion with the session sponsor and/or participants to obtain the necessary clarity and send out a revised agenda/objectives as needed
Topics that are too broad or too vague to be shaped or scoped by the workshop participants
Tactics to address: Same as previous issue
An agenda that doesn’t provide a clear line of sight between the scope of the session or individual agenda items and desired outcomes
Tactics to address: Map the agenda topics to specific outcomes or deliverables and ensure they are connected in a tangible way. Adjust as needed
Ensuring the Right Participation
Workshops aren’t solely about producing content, they are about establishing a shared understanding and ownership. To that end, having the right people in the room to both inform the discussion and own the outcomes is critical to establishing momentum post-session
What works:
Ensuring the right level of subject matter expertise to address the workshop scope and objectives
Having cross-functional representation to identify implications, offer alternate points of view, challenge ideas, and suggest other paradigms and mental models that could foster innovation
Bringing in “outside” expertise to the degree that what is being discussed is new or there is limited organizational knowledge of the subject area where external input can enhance the discussion
What to watch out for:
People jumping in and out of sessions to the point that it either becomes a distraction to other participants or there is a loss of continuity and effectiveness in the session as a whole
Tactics to address: Manage the part-time participants deliberately to minimize disruptions. Realign sessions to try and organize their participation into consecutive blocks of time with continuous input rather than sporadic engagement or see what can be done to either solicit full participation or identify alternate contributors who can participate in a dedicated capacity.
There is a knowledge gap that makes effective discussion difficult to impossible. The lack of the right people in the discussion will tend to draw momentum out of a session
Tactics to address: Document and validate assumptions made in the absence of the right experts being present. Investigate participation of necessary subject matter experts in key sessions focused on their areas of contribution
Limiting participants to those who are “like minded”, which may constrain the outcomes
Tactics to address: Explore involving a more diverse group of participants to provide a means for more potential approaches and solutions
Driving Engagement
Having the right people in the room and the right focus is critical to putting the right foundation in place, but making the most of the time you have is where the value is created, and that’s all about energy and engagement.
What works:
Leveraging an experienced facilitator, who is both engaging and engaged. The person leading the workshop needs to have a contagious enthusiasm that translates to the participants
Ensuring an inclusive discussion where all members of the session have a chance to contribute and have their ideas heard and considered, even if they aren’t ultimately utilized
Managing the agenda deliberately so that the energy and focus in the discussion is what it needs to be to produce the desired outcomes
What to watch out for:
A lack of energy or lack of the right pace from the facilitator will likely reduce the effectiveness of the session
Tactics to address: Switch up facilitators as needed to keep the energy high, pulse check the group on how they feel the workshop is going and make adjustments as needed
A lack of collaboration or participation from all attendees
Tactics to address: Active facilitation to engage quieter voices in the room and to manage anyone who is outspoken or dominating discussion
A lack of energy “in the room” that is drawing down the pace or productivity of the session
Tactics to address: Calling breaks as needed to give the participants a disruption, balancing the amount of active engagement of the participants in the event there is too much “presentation” going on where information is being shared and not enough discussion occurring
Creating Actionable Outcomes
One of the worst experiences you can have is a highly energized session that builds excitement, but then leads to no follow up action. Unfortunately, I’ve seen and experienced this many times over the course of my career, and it’s very frustrating, both when you lead workshops and as a participant, when you spend your time and provide insights that ultimately go to waste. Workshops are generally meant to help launch, accelerate, and build momentum through collaboration. To the extent that a team comes together and uses a session to establish direction, it is critical that the work not go to waste, not only to make the most of that effort, but also to provide reassurance that future sessions will be productive as well. If workshops become about process without outcome, they will lose efficacy very quickly and people will stop taking them seriously as a mechanism to facilitate and accelerate change.
What works:
Tracking the completion of workshop objectives throughout the process itself and making adjustments to the outcomes as required
Leaving the session with clear owners of any next steps
Establishing a checkpoint post-session to take a pulse on where things stand on the outcomes, next steps, and recommended actions
What to watch out for:
Getting to the end of a workshop and having any uncertainty in terms of whether the session objectives were met
Tactics to address: Objectives should be reviewed throughout the workshop to ensure alignment of the participants and commitment to the desired outcomes. There shouldn’t be any surprises waiting by the end
Leaving a session not having identified owners of the next steps
Tactics to address: In the event that no one “signs up” to own next steps or the means to perform the assignment is unclear for some reason, the facilitator can offer to review the next steps with the workshop sponsor and get back to the group with how the next steps will be taken forward
Assigning ownership of next steps without any general timeframe in which those actions were intended to be taken
Tactics to address: Setting a checkpoint at a specified point post-session to understand progress, review conflicting priorities, clear barriers, etc.
Wrapping Up
Going back to the original reason for writing this article, I believe workshops are an invaluable tool for defining vision, designing solutions, and facilitating change. Taking steps to ensure they are effective, engaging, and create impact is what ultimately drives their value.
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
In my most recent articles on Approaching Artificial Intelligence and Transformation, I highlight the importance of discipline in achieving business outcomes. To that end, governance is a critical aspect of any large-scale transformation or delivery effort because it both serves to reduce risk and inform change on an ongoing basis, both of which are an inevitable reality of these kinds of programs.
The purpose of this article is to discuss ways to approach governance overall, to avoid common concerns, and to establish core elements that will increase the probability it will be successful. Having seen and established many PMOs and governance bodies over time, I can honestly say that they are difficult to put in place for as many intangible reasons as anything mechanical, hopefully the nature of which will be addressed below.
Have the Right Mindset
Before addressing the execution “dos” and “don’ts”, success starts with understanding that governance is about successful delivery, not pure oversight. Where delivery is the priority, the focus is typically on enablement and support. By contrast, where the focus is the latter, emphasis can be placed largely on controls and intervention. The reality is that both are needed, which will be discussed more below, but starting with an intention to help delivery teams generally should translate into a positive and supportive environment, where collaboration is encouraged. If, by comparison, the role of governance is relegated to finding “gotchas” and looking for issues without providing teams will guidance or solutions, the effort likely won’t succeed. Healthy relationships and trust are critical to effective governance, because they encourage transparent and open dialogue. Without that, likely the process will break down or be ineffective somewhere along the way.
In a perfect world, delivery teams should want to participate in a governance process because it helps them do their work.
Addressing the Challenges
Suggesting that you want to initiate a governance process can be a very uncomfortable conversation. As a consultant, clients can feel like it is something being done “to” them, with a third-party reporting on their work to management. As a corporate citizen, it can feel like someone is trying to exercise a level of control over their peers in a leadership team and, consequently, limiting individual autonomy and empowerment in some way. This is why relationships and trust are critically important. Governance is a partnership and it is about increasing the probability of successful outcomes, not adding a layer of management over people who are capable of doing their jobs with the right level of support.
That being said, three things are typically said when the idea of establishing governance is introduced: that it will slow things down, hinder value creation, and add unnecessary overhead to teams that are already “too busy” or rushing to a deadline. I’ll focus on each of these in turn, along with what can be done to address the concerns in how you approach things.
It Slows Things Down
As I wrote in my article on Excellence by Design, delivering at speed matters. Lack of oversight can lead to efforts going off the rails without the timely interventions and support that cause delays and budget overruns. That being said, if the process slows everything down, you aren’t necessarily helping teams deliver either.
A fundamental question is whether your governance process is meant to be a “gate” or a “checkpoint”.
In the case of a gate, they can be very disruptive, so there should be compliance or risk-driven concerns (e.g., security or data privacy) that necessitate stopping or delaying some or all of a project until certain defined criteria or standards are met. If a process is gated, then this should be factored into estimation and planning at the outset, so expectations are set and managed accordingly, and to avoid the “we don’t have time for this” discussion that otherwise could happen. Gating criteria and project debriefs / retrospectives should also be reviewed to ensure standards and guidelines are updated to help both mitigate risk and encourage accelerated delivery, which is a difficult balance to strike. In principle, the more disciplined an environment is, the less “gating” should be needed, because teams are already following standards, doing proper quality assurance, and so on, and risk management should be easier on an average effort.
When it comes to “checkpoints”, there should be no difference in terms of the level of standards and guidelines in place, it’s about how they are handled in the course of the review discussion itself. When critical criteria are missed in a gate, there is a “pause and adjust” approach, whereas a checkpoint would note the exception and requested remedy, ideally along with a timeframe for doing so. The team is allowed to continue forward, but with an explicit assumption that they will make adjustments so the overall solution integrity is maintained in line with expectations. This is where a significant amount of technical debt and delivery issues are created. There is a level of trust involved in a checkpoint process, because the delivery team may choose not to remediate any issues, in which case the purpose and value of standards can be undermined, and a significant amount of complexity and risk is introduced as a result. If this becomes a pattern over time, it may make sense to shift towards a more gated process if things like security, privacy, or other critical issues are being created.
Again, the goal of governance is to remove barriers, provide resources where required, and to enable successful delivery, but there is a handshake involved to the degree that the process integrity needs to be managed overall. My general point of view is to trust teams to do the right thing and to leverage a checkpoint versus a gated process, but that is predicated on ensuring standards and quality are maintained. To the delivery discipline isn’t where it needs to be, a stronger process may be appropriate.
It Erodes Value
To the extent that the process is perceived to be pure overhead, it is important to clarify the overall goals of the process and, to the extent possible, to identify some metrics that can be used to signal whether it is being effective in helping to promote a healthy delivery environment.
At an overall level, the process is about reducing risk, promoting speed and enablement, and increasing the probability of successful delivery. Whether that is measured in changes in budget and schedule variance, issues remediated pre-deployment, or by a downstream measure of business value created through initiatives delivered on time, there should be a clear understanding of what the desired outcomes are and a sanity check that they are being met.
Arguably, where standards are concerned, this can be difficult to evaluate and measure, but certainly the increase in technical debt that is created in an environment that lacks standards and governance, cost of operations, and percentage of effort directed and build versus run on an overall level can be monitored and evaluated.
It Adds Overhead
I remember taking an assignment to help clean up the governance of a delivery environment many years ago where the person leading the organization was receiving a stack of updates every week that was literally three feet of documents when printed, spanning hundreds of projects. It goes without saying that all of that reporting provided nothing actionable, beyond everyone being able to say that they were “reporting out” on their delivery efforts on an ongoing basis. It was also the case that the amount of time project and program managers were focused on updating all that documentation was substantial. This is not governance. This is administration and a waste of resources. Ultimately, by changing the structure of the process, defining standards, and level of information being reported, the outcome was a five-page summary that covered critical programs, ongoing maintenance, production, and key metrics that was produced with considerably less effort and provided much better transparency into the environment.
The goal of governance is providing support, not producing reams of documentation. Ideally, there should be a critical minimum amount of information requested from teams to support a discussion on what they are doing, where they are in the delivery process, the risks or challenges they are facing, and what help (if any) they may need. To the degree that you can leverage artifacts the team is already producing so there is little to no extra effort involved in preparing for a discussion, even better. And, as another litmus test, everything included in a governance discussion should serve a purpose and be actionable. Anything else likely is a waste of time and resources.
Making Governance Effective
Having addressed some of the common concerns and issues, there are also things that should be considered that increase the probability of success.
Allow for Evolution
As I mentioned in the opening, the right mindset has a significant influence on making governance successful. Part of that is understanding it will never be perfect. I believe very strongly in launching governance discussions and allowing feedback and time to mature the process and infrastructure given real experience with what works and what everyone needs.
One of the best things that can be done is to track and monitor delivery risks and technology-related issues and use those inputs to guide and prioritize the standards and guidelines in place. Said differently, you don’t need governance to improve things you already do well, you leverage it (primarily) to help you address risks and gaps you have and to promote quality.
Having seen an environment where a team was “working on” establishing a governance process over an extended period of time versus one that was stood up inside 30 days, I’d rather have the latter process in place and allow for it to evolve than one that is never launched.
Cover the Bases
In the previous section, I mentioned leveraging a critical minimum amount of information to facilitate the process, ideally utilizing artifacts a team already has. Again, it’s not about the process, it’s about the discussion and enabling outcomes.
That being said, since trust and partnership are important, even in a fairly bare bones governance environment, there should be transparency into what the process is, when it should be applied, who should attend, expectations of all participants, and a consistent cadence with which it is conducted.
It should be possible to have ad-hoc discussions if needed, but there is something contradictory to suggesting that governance is a key component to a disciplined environment and not being able to schedule the discussions themselves consistently. Anecdotally, when we conducted project review discussions in my time at Sapient, it was commonly understood that if a team was ever “too busy” to schedule their review, they probably needed to have it as soon as possible, so the reason they were overwhelmed or too busy was clear.
Satisfy Your Stakeholders
The final dimension to consider in making governance effective is understanding and satisfying the stakeholders surrounding it, starting with the teams. Any process can and should evolve, and that evolution should be based on experience obtained executing the process itself, monitoring operating metrics on an ongoing basis, and feedback that is continually gathered to make it more effective.
That being said, if the process never surfaces challenges and risks, it likely isn’t working properly, because governance is meant to do exactly that, along with providing teams with the support they need. Satisfying stakeholders doesn’t mean painting an unrealistically positive picture, especially if there are fundamental issues in the underlying environment.
I have seen situations where teams were encouraged to share inaccurate information about the health of their work in the interest of managing perceptions and avoiding difficult conversations that were critically needed. This is why having an experienced team leading the conversations and a healthy, supportive, and trusting environment is so important. Governance is needed because things do happen in delivery. Technology work is messy and complicated and there are always risks that materialize. The goal is to see them and respond before they have consequential impact.
Wrapping Up
Hopefully I’ve managed to hit some of the primary points to consider when establishing or evaluating a governance process. There are many dimensions, but the most important ones are first, focusing on value and, second, on having the right mindset, relationships, and trust. The process is too often the focus, and without the other parts, it will fail. People are at the center of making it work, nothing else.
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
In my first blog article back in 2021, I wrote that “we learn to value experience only once we actually have it”… and one thing I’ve certainly realized is that it’s much easier to do something quickly than to do it well. The problem is that excellence requires discipline, especially when you want to scale or have sustainable results, and that often comes into conflict with a natural desire to achieve speed in delivery.
There is a tremendous amount of optimism in the transformative value AI can create across a wide range of areas. While much continues to be written about various tools, technologies, and solutions, there is value in having a structured approach to developing AI strategy and how we will govern it once it is implemented across an organization.
Why? We want results.
Some historical examples on why there is a case for action:
Many organizations have leveraged SharePoint as a way to manage documents. Because it’s relatively easy to use, access to the technology generally is provided to a broad set of users, with little or no guidance on how to use it (e.g., metatagging strategy), and over time there becomes a sprawl of content that may contain critical, confidential, or proprietary information with limited overall awareness of what exists and where
In the last number of years, Citizen Development has become popular, with the rise of low code, no code, and RPA tools, creating accessibility to automation that is meant to enable business (and largely non-technical) resources to rapidly create solutions, from the trivial to relatively complex. Quite often these solutions aren’t considered part of a larger application portfolio, are managed with little or no oversight, and become difficult to integrate, leverage, or support effectively
In data and analytics, tools like Alteryx can be deployed across a broad set of users who, after they are given access to requested data sources, create their own transformations, dashboards, and other analytical outputs to inform ongoing business decisions. The challenge occurs when the underlying data changes, is not understood properly (and downstream inferences can be incorrect), or these individuals leave or transition out of their roles and the solutions they built are not well understood or difficult for someone else to leverage or support
What these situations have in common is the introduction of something meant to serve as an enabler that has relative ease of use and accessibility across a broad audience, but where there also may be a lack of standards and governance to make sure the capabilities are introduced in a thoughtful and consistent manner, leading to inefficiency, increased cost, and lost opportunity. With the amount of hype surrounding AI, the proliferation of tools, and general ease of use that they provide, the potential for organizations to create a mess in the wake of their experimentation with these technologies seems very significant.
The focus of the remainder of this article is to explore some dimensions to consider in developing a strategy for the effective use and governance of AI in an organization. The focus will be on the approach, not the content of an AI strategy, which can be the subject of a later article. I am not suggesting that everything needs to be prescriptive, cumbersome, or bureaucratic to the point that nothing can get done, but I believe it is important to have a thoughtful approach to avoid the pitfalls that are common to these situations.
To the extent that, in some organizations, “governance” implies control versus enablement or there are historical real or perceived IT delivery issues, there may be concern with heading down this path. Regardless of how the concepts are implemented, I believe they are worth considering sooner rather than later, given we are still relatively early in the adoption process of these capabilities.
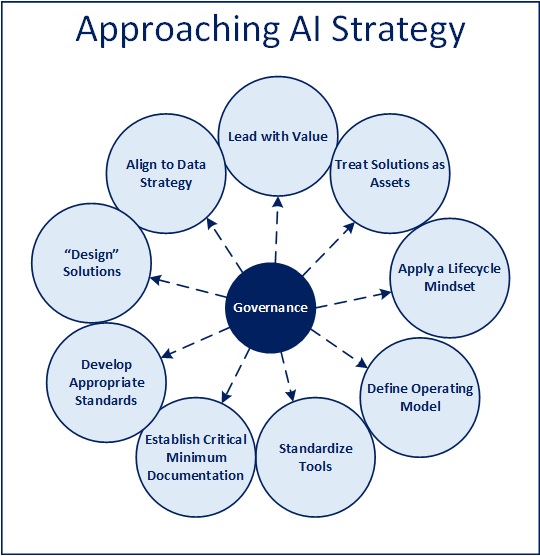
Dimensions to Consider
Below are various aspects of establishing a strategy and governance process for AI that are worth consideration. I listed them somewhat in a sequential manner, as I’d think about them personally, though that doesn’t imply you can’t explore and elaborate as many as are appropriate in parallel, and in whatever order makes sense. The outcome of the exercise doesn’t need to be rigid mandates, requirements, or guidelines per se, but nearly all of these topics likely will come up implicitly or otherwise as we delve further into leveraging these technologies moving forward.
Lead with Value
The first dimension is probably the most important in forming an AI strategy, which is to articulate the business problems being solved and value that is meant to be created. It is very easy with new technologies to focus on the tools and not the outcomes and start implementing without a clear understanding of the impact that is intended. As a result, measuring the value created and governing the efficacy of the solutions delivered becomes extremely difficult.
As a person who does not believe in deploying technology for technology’s sake, identifying, tracking, and measuring impact is important in knowing we will ultimately make informed decisions in how we leverage new capabilities and invest in them appropriately over time.
Treat Solutions as Assets
Along the lines of the above point, there is risk associated with being consumed by what is “cool” versus what is “useful” (something I’ve written about previously), and treating new technologies like “gadgets” versus actual business solutions. Where we treat our investments as assets, the associated discipline we apply in making decisions surrounding them should be greater. This is particularly important in emerging technology because the desire to experiment and leverage new tools could quickly become unsustainable as the number of one-off solutions grows and is unsupportable, eventually draining resources from new innovation.
Apply a Lifecycle Mindset
When leveraging a new technical capability, I would argue that we should look for opportunities to think of the full product lifecycle when it comes to how we identify, define, design, develop, manage, and retire solutions. In my experience, the identify (finding new tools) and develop (delivering new solutions) aspects of the process receive significant emphasis in a speed-to-market environment, but the others much less so, and often to the overall detriment of an organization when they quickly are saddled with the resulting technical debt that comes from neglecting some of the other steps in the process. This doesn’t necessarily imply a lot of additional steps, process overhead, or time/effort to be expended, but there is value created in each step of a product lifecycle (particularly in the early stages) and all of them need to be given due consideration if you want to establish a sustainable, performant environment. The physical manifestation of some these steps could be as simple as a checklist to make sure there aren’t blind spots that arise later on that were avoidable or that create business risk.
Define Operating Model
Introducing new capabilities, especially ones where the barrier to entry/ease of use allows for a wide audience of users can cause unintended consequences if not managed effectively. While it’s tempting to draw a business/technology dividing line, my experience has been that there can be very technically capable business consumers of technology and very undisciplined technologists who implement it as well. The point of thinking through the operating model is to identify roles and responsibilities in how you will leverage new capabilities so that expectations and accountability is clear, along with guidelines for how various teams are meant to collaborate over the lifecycle mentioned above.
Whether the goal is to “empower end users” by fully distributing capabilities across teams, with some level of centralized support and governance, or fully centralizing with decentralized demand generation (or any flavor in between), the point is to understand who is best positioned to contribute at different steps of the process and promote consistency to an appropriate level so performance and efficacy of both the process and eventual solutions is something you can track, evaluate, and improve over time. As an example, it would likely be very expensive and ineffective to hire a set of “prompt engineers” that operate in a fully distributed manner in a larger organization by comparison with having a smaller, centralized set of highly skilled resources who can provide guidance and standards to a broader set of users in a de-centralized environment.
Following onto the above, it is also worthwhile to decide whether and how these kinds of efforts should show up in a larger portfolio management process (to the extent one is in place). Where AI and agentic solutions are meant to displace existing ways of working or produce meaningful business outcomes, the time spent delivering and supporting these solutions should likely be tracked so there is an ability to evaluate and manage these investments over time.
Standardize Tools
This will likely be one of the larger issues that organizations face, particularly given where we are with AI in a broader market context today. Tools and technologies are advancing at such a rapid rate that having a disciplined process for evaluating, selecting, and integrating a specific set of “approved” tools is and will be challenging for some time.
While asking questions of a generic large language model like ChatGPT, Grok, DeepSeek, etc. and changing from one to the other seems relatively straightforward, there is a lot more complexity involved when we want to leverage company-specific data and approaches like RAG to produce more targeted and valuable outcomes.
When it comes to agentic solutions, there is also a proliferation of technologies at the moment. In these cases, managing the cost, complexity, performance, security, and associated data privacy issues will also become complex if there aren’t “preferred” technologies in place and “known good” ways in which they can be leveraged.
Said differently, if we believe effective use of AI is critical to maintaining competitive advantage, we should know that the tools we are leveraging are vetted, producing quality results, and that we’re using them effectively.
Establish Critical Minimum Documentation
I realize it’s risky to use profanity in a professional article, but documentation has to be mentioned if we assume AI is a critical enabler for businesses moving forward. Its importance can probably be summarized if you fast forward one year from today, hold a leadership meeting, and ask “what are all the ways we are using artificial intelligence, and is it producing the value we expected a year ago?” If the response contains no specifics and supporting evidence, there should be cause for concern, because there will be significant investment made in this area over the next 1-2 years, and tracking those investments is important to realizing the benefits that are being promised everywhere you look.
Does “documentation” mean developing a binder for every prompt that is created, every agent that’s launched, or every solution that’s developed? No, absolutely not, and that would likely be a large waste of money for marginal value. There should be, however, a critical minimum amount of documentation that is developed in concert with these solutions to clarify their purpose, intended outcome/use, value to be created, and any implementation particulars that may be relevant to the nature of the solution (e.g. foundational model, data sets leveraged, data currency assumptions, etc.). An inventory of the assets developed should exist, minimally so that it can be reviewed and audited for things like security, compliance, IP, and privacy-related concerns where applicable.
Develop Appropriate Standards
There are various types of solutions that could be part of an overall AI strategy and the opportunity to develop standards that promote quality, reuse, scale, security, and so forth is significant. Whether it takes the form of a “how to” guide for writing prompts, to data sourcing and refresh standards with RAG-enabled solutions, reference architecture and design patterns across various solution types, or limits to the number of agents that can be developed without review for optimization opportunities… In this regard, something pragmatic, that isn’t overly prescriptive but that also doesn’t reflect a total lack of standards would be appropriate in most organizations.
In a decentralized operating environment, the chance that solutions will be developed in a one-off fashion, with varying levels of quality, consistency, and standardization is highly probable and that could create issues with security, scalability, technical debt, and so on. Defining the handshake between consumers of these new capabilities and those developing standards, along with when it is appropriate to define them, could be important things to consider.
Design Solutions
Again, as I mentioned in relation to the product lifecycle mindset, there can be a strong preference to deliver solutions without giving much thought to design. While this is often attributed to “speed to market” and a “bias towards action”, it doesn’t take long for tactical thinking to lead to a considerable amount of technical debt, an inability to reuse or scale solutions, or significant operating costs that start to slow down delivery and erode value. These are avoidable consequences when thought is given to architecture and design up front and the effort nearly always pays off over time.
Align to Data Strategy
This topic could be an article in itself, but suffice is to say that having an effective AI strategy is heavily dependent on an organization’s overall data strategy and the health of that portfolio. Said differently: if your underlying data isn’t in order, you won’t be able to derive much in terms of meaningful insights from it. Concerns related to privacy and security, data sourcing, stewardship, data quality, lineage and governance, use of multiple large language models (LLMs), effective use of RAG, the relationship of data products to AI insights and agents, and effective ways of architecting for agility, interoperability, composability, evolution, and flexibility are all relevant topics to be explored and understood.
Define and Establish a Governance Process
Having laid out the above dimensions in terms of establishing and operationalizing an AI strategy, there needs to be a way to govern it. The goal of governance is to achieve meaningful business outcomes by promoting effective use and adoption of the new capabilities, while managing exposure related to introducing change into the environment. This could be part of an existing governance process or set up in parallel and coordinated with others in place, but the point is that you can’t optimize what you don’t monitor and manage, and the promise of AI is such that we should be thoughtful about how we govern its adoption across an organization.
“I believe that this nation should commit itself to achieving the goal, before this decade is out, of landing a man on the moon and returning him safely to the Earth.” – John F Kennedy, May 25, 1961
When JFK made his famous pronouncement in 1961, the United States was losing in the space race. The Soviet Union was visibly ahead, to the point that the government shuffled the deck, bringing together various agencies to form NASA, and set a target far out ahead of where anyone was focused at the time: landing on the Moon. The context is important as the U.S. was not operating from a position of strength and JFK didn’t shoot for parity or to remain in a defensive posture. Instead, he leaned in and set an audacious goal that redefined the playing field entirely.
I spoke at a town hall fairly recently about “The Saturn V Story”, a documentary that covers the space race and journey leading to the Apollo 11 moon landing on July 20, 1969. The scale and complexity of what accomplished in a relatively short timeframe was truly incredible and feels like a good way to introduce a Transformation discussion. The Apollo program engaged 375,000 people at its peak, required extremely thoughtful planning and coordination (including the Mercury and Gemini programs that preceded it), and presented a significant number of engineering challenges that needed to be overcome to achieve its ultimate goal. It’s an inspiring story, as any successful transformation effort should be.
The challenge is that true transformation is exceptionally difficult and many of these efforts fail or fall short of their stated objectives. The remainder of this article will highlight some key dimensions that I believe are critical in increasing the probability of success.
Transformation is a requirement of remaining competitive in a global digital economy. The disruptions (e.g., cloud computing, robotics, orchestration, artificial intelligence, cyber security exposure, quantum computing) have and will continue to occur, and success will be measured, in part, based on an organization’s ability to continuously transform, leveraging advanced capabilities to its’ maximum strategic benefit.
Successful Transformation
Culture versus Outcome
Before diving into the dimensions themselves, I want to emphasize the difference I see between changing culture and the kind of transformation I’m referencing in this article. Culture is an important aspect to affecting change, as I will discuss in the context of the dimensions themselves, but a change in culture that doesn’t lead to a corresponding change in results is relatively meaningless.
To that end, I would argue that it is important to think about “change management” as a way to transition between the current and desired ways of working in a future state environment, but with specific, defined outcomes attached to the goal.
It is insufficient, as an example, to express “we want to establish a more highly collaborative workplace that fosters innovation” without also being able to answer the questions: “To what end?” or “In the interest of accomplishing what?” Arguably, it is the desired outcome that sets the stage for the nature of the culture that will be required, both to get to the stated goal as well as to operate effectively once those goals are achieved. In my experience, this balance isn’t given enough thought when change efforts are initiated, and it’s important to make sure culture and desired outcomes are both clear and aligned with each other.
For more on the fundamental aspects of a healthy environment, please see my article on The Criticality of Culture.
What it Takes
Successful transformation efforts require focus on many levels and in various dimensions to manage what ultimately translates to risk.
The set that come to mind as most critical are having:
An audacious goal
Transformation is, in itself, a fundamental (not incremental) change in what an organization is able to accomplish
To the extent that substantial change is difficult, the value associated with the goal needs to outweigh the difficulties (and costs) that will be required to transition from where you are to where you need to be
If the goal also isn’t compelling enough, likely there won’t be the requisite level of individual and collective investment required to overcome the adversity that is typically part of these efforts. This is not just about having a business case. It’s a reason for people to care… and that level of investment matters where transformation is the goal
Courageous, committed leadership
Change is, by its’ nature, difficult and disruptive. There will be friction and resistance that comes from altering the status quo
The requirements of leadership in these efforts tend to be very high, because of the adversity and risk that can be involved, and a degree of fearlessness and willingness to ride through the difficulties is important
Where this level of leadership isn’t present, it will become easy to focus on obstacles versus solutions and to avoid taking risks that lead to suboptimized results or overall failure of the effort. If it was easy to transform, everyone would be doing it all the time
It is worth noting that, in the case of the Apollo missions, JFK wasn’t there to see the program through, yet it survived both his passing and significant events like the Apollo fire without compromising the goal itself
A question to consider in this regard: Is the goal so compelling that, if the vision holder / sponsor were to leave, the effort would still move forward? There are many large-scale efforts I’ve seen over the years where a change in leadership affects the commitment to a strategy. There may be valid reasons for this to be the case, but arguably both a worthy goal and strong leadership are necessary components in transformation overall
An aligned and supportive culture
There is a significant aspect of accomplishing a transformational agenda that places a burden on culture
On this point, the going-in position matters in the interest of mapping out the execution approach, because anything about the environment that isn’t conducive to facilitating and enabling collaboration and change will ultimately create friction that needs to be addressed and (hopefully) overcome
To the extent that the organization works in silos or that there is significant and potentially unhealthy internal competition within and across leaders, the implications of those conflicts need to be understood and mitigated early on (to the degree possible) so as to avoid what could lead to adverse impacts on the effort overall
As a leader said to me very early in my career, “There is room enough in success for everybody.” Defining success at an individual and collective level may be a worthwhile activity to consider depending on the nature of where an organization is when starting to pursue change
On this final point, I have been in the situation more than once professionally where a team worked to actively undermine transformation objectives because those efforts had an adverse impact to their broader role in an organization. This speaks, in part, to the importance of engaged, courageous leadership to bring teams into alignment, but where that leadership isn’t present, it definitely makes things more difficult. Said differently, the more established the status quo is, the harder it may resist change
A thoughtful approach
“Rome was not built in a day” is probably the best way to summarize this point
Depending on the level of complexity and degree of change involved, the more thought and attention that needs to be paid to planning out the approach itself
The Apollo program is a great example of this, because there were countless interim stages in the development of the Saturn V rocket, creating a safe environment for manned space flight, procedures for rendezvous and docking of the spacecraft, etc.
In a technology delivery environment, these can be program increments in a scaled Agile environment, selective “pilots” or “proof-of-concept” efforts, or interim deliveries in a more component-based (and service-driven) architecture. The overall point being that it’s important to map out the evolution of current to future state, allowing for testing and staging of interim goals that help reduce risk on the ultimate objectives
In a different example, when establishing an architecture capability in a large, complex organization, we established an operating model to define roles and responsibilities, but then operationalized the model in layers to help facilitate change with defined outcomes spread across multiple years. This was done purposefully and deliberately in the interest of making the changes sustainable and to gradually shift delivery culture to be more strategically-aligned, disciplined, and less siloed in the process
Agility and adaptiveness
The more advanced and innovative the transformation effort is, the more likely it will be that there is a higher degree of unknown (and knowledge risk) associated with the effort
To that end, it is highly probable that the approach to execution will evolve over time as knowledge gaps are uncovered and limitations and constraints need to be addressed and overcome
There are countless examples of this in the Apollo program, one of the early ones being the abandonment of the “Nova” rocket design, which involved a massive vehicle that ultimately was eliminated in deference to the multi-stage rocket and lunar lander / command module approach. In this case, the means for arriving at and landing on the moon was completely different than it was at the program’s inception, but the outcome was ultimately the same
I spend some time discussing these “points of inflection” in my article On Project Health and Transparency, but the important concept is not to be too prescriptive when planning a transformation effort, because execution will definitely evolve
Patience and discipline
My underlying assumption is that the level of change involved in transformation is significant and, as such, it will take time to accomplish
The balance to be struck is ultimately in managing interim deliveries in relation to the overall goals of the effort. This is where patience and discipline matter, because it is always tempting to take short cuts in the interest of “speed to market” while compromising fundamental design elements that are important to overall quality and program-level objectives (something I address in Fast and Cheap, Isn’t Good)
This isn’t to say that tradeoffs can’t or shouldn’t be made, because they often are, but rather that these be conscious choices, done through a governance process, and with a full understanding of the implications of the decisions on the ultimate transformation objectives
A relentless focus on delivery
The final dimension is somewhat obvious, but is important to mention, because I’ve encountered transformative efforts in the past that spent so much energy either on structural or theoretical aspects to their “program design” that they actually failed to deliver anything
In the case of the Apollo program, part of what makes the story so compelling is the number of times the team needed to innovate to overcome issues that arose, particularly to various design and engineering challenges
Again, this is why courageous, committed leadership is so important to transformation. The work is difficult and messy and it’s not for the faint of heart. Resilience and persistence are required to accomplish great things.
Wrapping Up
Hopefully this article has provided some areas to consider in either mapping out or evaluating the health of a transformational effort. As I covered in my article On Delivering at Speed, there are always opportunities to improve, even when you deliver a complex or high-risk effort. The point is to be disciplined and thoughtful in how you approach these efforts, so the bumps that inevitably occur are more manageable and the impact they have are minimized overall.
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
Having had multiple recent discussions related to portfolio management, I thought I’d share some thoughts relative to disciplined operations, in terms of the aforementioned subject and on the associated toolsets as well. This is a substantial topic, but I’ll try to hit the main points and address more detailed questions as and when they arise.
In getting started, given all the buzz around GenAI, I asked ChatGPT “What are the most important dimensions of portfolio management in technology?” What was interesting was that the response aligned with most discussions I’ve had over time, which is to say that it provided a process-oriented perspective on strategic alignment, financial management, and so on (a dozen dimensions overall), with a wonderfully summarized description of each (and it was both helpful and informative). The curious part was that it missed the two things I believe are most important: courageous leadership and culture.
The remainder of this article will focus more on the process dimensions (I’m not going to frame it the same as ChatGPT for simplicity), but I wanted to start with a fundamental point: these things have to be about partnership and value first and process second. If the focus becomes the process, there is generally something wrong in the partnership or the process is likely too cumbersome in how it is designed (or both).
Portfolio Management
Partnership
Portfolio management needs to start with a fundamental partnership and shared investment between business and technology leaders on the intended outcome. Fortunately, or unfortunately, where the process tends to get the most focus (and part of why I’ve heard it so much in the last couple years) is in a difficult market/economy where spend management is the focus, and the intention is largely related to optimizing costs. Broadly speaking, when times are good and businesses grow, the processes for prioritization and governance can become less rigorous in a speed-to-market mindset, the demand for IT services increases, and a significant amount of inefficiency, delivery and quality issues can arise as a result. The reality is that discipline should always be a part of the process because it’s in the best interest of creating value (long- and short-term) for an organization. That isn’t to suggest artificial constraints, unnecessary gates in a process, or anything to hinder speed-to-market. Rather, the goal of portfolio management should be to have a framework in place to manage demand through delivery in a way that facilitates predictable, timely, and quality delivery and a healthy, secure, robust, and modern underlying technology footprint that creates significant business value and competitive advantage over time. That overall objective is just as relevant during a demand surge as it is when spending is constrained.
This is where courageous leadership becomes the other critical overall dimension. It’s never possible to do everything and do it well. The key is to maintain the right mix of work, creating the right outcomes, at a sustainable pace, with quality. Where technology leaders become order takers is where a significant amount of risk can be introduced that actually hurts a business over time. The primary results being that taking on too much without thoughtful planning can result in critical resources being spread too thin, missed delivery commitments, poor quality, and substantial technical debt, all of which eventually undermine the originally intended goal of being “responsive”. This is why partnership and mutual investment in the intended outcomes matters. Not everything has to be “perfect” (and the concept itself doesn’t really exist in technology anyway), but the point is to make conscious choices on where to spend precious company resources to optimize the overall value created.
End-to-End Transparency
Shifting focus from the direction to the execution, portfolio management needs to start with visibility in three areas:
Demand management – the work being requested
Delivery monitoring – the work being executed
Value realization – the impact of what was delivered
In demand management, the focus should ideally be on both internal and external factors (e.g., business priorities, customer needs, competitive and industry trends), a thoughtful understanding of the short- and long-term value of the various opportunities, the requirements (internal and external) necessary to make them happen, and the desired timeframe for those results to be achieved. From a process standpoint, notice of involvement and request for estimate (RFE) processes tend to be important (depending on the scale and structure of an organization), along with ongoing resource allocation and forecast information to evaluate these opportunities as they arise.
Delivery monitoring is important, given the dependencies that can and do exist within and across efforts in a portfolio, the associated resource needs, and the expectations they place on customers, partners, or internal stakeholders once delivered. As and when things change, there should be awareness as to the impact of those changes on upcoming demand as well as other efforts within a managed portfolio.
Value realization is a generally underserved, but relatively important part of portfolio management, especially in spending constrained situations. This level of discipline (at an overall level) is important for two primary reasons: first, to understand the efficacy of estimation and planning processes in the interest of future prioritization and planning and, second, to ensure investments were made effectively in the right priorities. Where there is no “retrospective”, a lot of learnings may be being lost in the interest of continuous improvement and operational efficiency and effectiveness over time (ultimately having an adverse impact on business value created).
Maintaining a Balanced Portfolio
Two concepts that I believe are important to consider in how work is ultimately allocated/prioritized within an IT portfolio:
Portfolio allocation – the mix of work that is being executed on an ongoing basis
Prioritization – how work is ultimately selected and the process for doing so
A good mental model for portfolio allocation is a jigsaw puzzle. Some pieces fit together, others don’t, and whatever pieces are selected, you ultimately are striving to have an overall picture that matches what you originally saw “on the box”. While you also can operate in multiple areas of a puzzle at the same time, you also generally can’t focus in on all of them concurrently and expect to be efficient on the whole.
What I believe a “good” portfolio should include is four key areas (with an optional fifth):
Innovation – testing and experimenting in areas where you may achieve significant competitive advantage or differentiation
Business Projects – developing solutions that create or enable new or enhanced business capabilities
Modernization – using an “urban renewal” mindset to continue to maintain, simplify, rationalize, and advance your infrastructure to avoid significant end of life, technical debt, or other adverse impacts from an aging or diverse technology footprint
Security – continuing to leverage tools and technologies that manage the ever increasing exposure associated with cyber security threats (internal and external)
Compliance (where appropriate) – investing in efforts to ensure appropriate conformance and controls in regulatory environments / industries
I would argue that, regardless of the level of overall funding, these categories should always be part of an IT portfolio. There can obviously be projects or programs that provide forward momentum in more than one category above, but where there isn’t some level of investment in the “non-business project” areas, likely there will be a significant correction needed at some point of time that could be very disruptive from a business standpoint. It is probably also worth noting that I am not calling out a “technology projects” category above on purpose. From my perspective, if a project doesn’t drive one of the other categories, I’d question what value it creates. There is no value in technology for technology’s sake.
From a prioritization standpoint, I’ve seen both ends of the spectrum over the course of time: environments where there is no prioritization in place and everything with a positive business case (and even some without) are sent into execution to ones where there is an elaborate “scoring” methodology, with weights and factors and metrics organized into highly elaborate calculations that create a false sense of “rigor” in the efficacy of the process. My point of view overall is that, with the above portfolio allocation model in place, ensuring some balance in each of the critical categories of spend, a prioritization process should include some level of metrics, with an emphasis on short- and long-term business/financial impact as well as a conscious integration of the resource commitments required to execute the effort by comparison with other alternatives. As important as any process, however, is the discussions that should be happening from a business standpoint to ensure the engagement, partnership, and overall business value being delivered through the portfolio (the picture on the box) in the decisions made.
Release Management
Part of arriving at the right set of work to do also comes down to release management. A good analogy for release management is the game Tetris. In Tetris, you have various shaped blocks dropping continually into a grid, with the goal of rotating and aligning them to fit as cleanly with what is already on the radar as possible. There are and always will be gaps and the fit will never be perfect, but you can certainly approach Tetris in a way that is efficient and well-aligned or in a way that is very wasteful of the overall real estate with which you have to work.
This is great mental model for how project planning should occur. If you do a good job, resources are effectively utilized, outcomes are predictable, there is little waste, and things run fairly smoothly. If you don’t think about the process and continually inject new work into a portfolio without thoughtful planning as to dependencies and ongoing commitments, there can and likely will be significant waste, inefficiency, collateral impact, and issues in execution.
Release management comes down to two fundamental components:
Release strategy – the approach to how you organize and deliver major and minor changes to various stakeholder groups over time
Release calendar – an ongoing view of what will be delivered at various times, along with any critical “T-minus” dates and/or delivery milestones that can be part of a progress monitoring or gating process used in conjunction with delivery governance processes
From a release strategy standpoint, it is tempting in a world of product teams, DevSecOps, and CI/CD pipelines to assume everything comes down to individual product plans and their associated release schedules. The two primary issues here are the time and effort it generally takes to deploy new technology and the associated change management impact to the end users who are expected to adopt those changes as and when they occur. The more fragmented the planning process, the more business risk there is that ultimately end users or customers will be either under or overserved at any given point in time, where a thoughtful release strategy can help create predictable, manageable, and sustainable levels of change over time across a diverse set of stakeholders being served.
The release calendar, aside from being an overall summary of what will be delivered when and to whom, also should ideally provide transparency into other critical milestones in the major delivery efforts so that, in the event something moves off plan (which is a very normal occurrence in technology and medium to larger portfolios), the relationship to other ongoing efforts can be evaluated from a governance standpoint to determine whether any rebalancing or slotting of work is required.
Change Management
While I won’t spend a significant amount of time on this point, change management is often an area where I’ve seen the process managed very well and relatively poorly. The easy part is generally managing change relative to a specific project or program and that governance often exists in my experience. The issue that can arise is when the leadership overseeing a specific project is only taking into account the implications of change on that effort alone, and not the potential ripple effect of a schedule, scope, or financial adjustment on the rest of the portfolio, future demand, or on end users in the event that releases are being adjusted.
On Tooling
Pivoting from processes to tools, at an overall level, I’m generally not a fan of over-engineering the infrastructure associated with portfolio management. It is very easy for such an infrastructure to take a life of its own, become a significant administrative burden that creates little value (beyond transparency), or contain outdated and inaccurate information to the degree that the process involves too much data without underlying ownership and usage of the data obtained.
The goal is the outcome, not the tools.
To the extent that a process is being established, I’d generally want to focus on transparency (demand through delivery) and a healthy ongoing discussion of priorities in the interest of making informed decisions. Beyond that, I’ve seen a lot of reporting that doesn’t generally result in any level of actions being taken, which I consider to be very ineffective from a leadership and operational standpoint.
Again, if the process is meant to highlight a relationship problem, such as a dashboard being created requiring a large number of employees to capture timesheets to be rolled up, marked to various projects, all to have a management discussion to say “we’re over allocated and burning out our teams”, my question would be why all of that data and effort was required to “prove” something, whether there is actual trust and partnership, whether there are other underlying delivery performance issues, and so on. The process and tools are there to enable effective execution and the creation of business value, not drain effort and energy that could better be applied in delivery with administrivia.
Wrapping Up
Overall, having spent a number of years seeing well developed and executed processes as well as less robust versions of the same, effective portfolio management comes down to value creation. When the focus becomes about the process, the dashboard, the report, the metrics, something is amiss in my experience. It should about informing engaged leadership, fostering partnership, enabling decisions, and creating value. That is not to say that average utilization of critical resources (as an example) isn’t a good thing to monitor and keep in mind, but it’s what you do with that information that matters.
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
Having covered a couple future-oriented topics on Transforming Manufacturing and The Future of IT, I thought it would good to come back to where we are with Enterprise Architecture as a critical function for promoting excellence in IT.
Overall, there is a critical balance to be struck in technology strategy today: technology-driven capabilities are advancing faster than any organization can reasonably adopt and integrate them (as is the exposure in cyber security), even if you could, the change management issues you’d cause on end users would be highly disruptive, and thereby undermine your desired business outcomes, and, in practice rapidly evolving, sustainable change is the goal, not any one particular “implementation” of the latest thing. This is what Relentless Innovation is about, referenced in my article on Excellence by Design.
Connecting Architecture back to Strategy
In the article, Creating Value Through Strategy, I laid out a framework for thinking about IT strategy at an overall level that can be used to create some focal points for enterprise architecture efforts in practice, namely:
Innovate – leveraging technology advancements in ways that promote competitive advantage
Accelerate – increasing speed to market/value to be more responsive to changing needs
Optimize – improving the value/cost ratio to drive return on technology investments overall
Inspire – creating a workplace that promotes retention and enables the above objectives
Perform – ensuring reliability, security, and performance in the production environment
The remainder of this article will focus on how enterprise architecture (EA) plays a role in enabling each of these dimensions given the pace of change today.
Breaking it Down
Innovate
Adopting new technologies for maximum business advantage is certainly the desired end game in this dimension, but unless there is a very unique, one-off situation, the role of EA is fairly critical in making these advancements leverageable, scalable, and sustainable. It’s worth noting, by the way, that I’m specifically referring to “enterprise architecture” here, not “solution architecture”, which I would consider to be the architecture and design of a specific business solution. One should not exist without the other and, to the degree that solution architecture is emphasized without a governing enterprise architecture framework in place, the probability of significant technical debt, delivery issues, lack of reliability, and a host of other issues will skyrocket.
Where EA plays a role in promoting innovation is minimally in exploring market trends and looking for enabling technologies that can promote competitive advantage, but also, and very critically in establishing the standards and guidelines by which new technologies should be introduced and integrated into the existing environment.
Using a “modern” example, I’ve seen a number of articles of late on the role of GenAI in “replacing” or “disrupting” application development, from the low-code/no code type solutions to the SaaS/package software domain, to everywhere. While this sounds great in theory, it shouldn’t take long for the enterprise architecture questions to surface:
How do I integrate that accumulated set of “point solutions” in any standard way?
How do I meaningfully run analytics on the data associated with these applications?
How do I secure these applications in a way that I’m not exposed to vulnerabilities that I would with any open-source technology (i.e., they are generated by an engine that may have inherent security gaps)?
How do I manage the interoperability between these internally-developed/generated solutions and standard packages (ERP, CRM, etc.) that are likely a core part of any sizeable IT environment?
In the above example, even if I find way to replace existing low-code/no code solutions with a new technology, it doesn’t mean that I don’t have the same challenges as exist with leveraging those technologies today.
In the case of innovation, the highest priorities for EA are therefore: looking for new disruptive technologies in the market, defining standards to enable their effective introduction and use, and then governing that delivery process to ensure standards are followed in practice.
Accelerate
Speed to market is a pressing reality in any environment I’ve seen, though it can lead to negative consequences as I discussed in Fast and Cheap… Isn’t Good. Certainly, one of the largest barriers to speed is complexity, and complexity can come in many forms depending on the makeup of the overall IT landscape, the standards, processes, and governance in place related to delivery, and the diversity in solutions, tools, and technologies that are involved in the ecosystem as a whole.
While I talk about standards, reuse, and governance in the broader article on IT strategy, I would argue that the largest priority for EA in terms of accelerating delivery is in rationalization of solutions, tools, and technologies in use overall.
The more diverse the enterprise ecosystem is, the more difficult it becomes to add, replace, or integrate new solutions over time, and ultimately this will slow delivery efforts down to a snail’s pace (not to mention making them much more expensive and higher risk over time).
Using an example of a company that has performed many acquisitions over time, looking for opportunities to simplify and standardize core systems (e.g., moving to a single ERP versus having multiple instances and running consolidations through a separate tool) can lead to significant reduction in complexity over time, not to mention making it possible to redeploy resources to new capability development versus being spread across multiple redundant production solutions.
Optimize
In the case of increasing the value/cost ratio, the ability to rationalize tools and solutions should definitely lead to reduced cost of ownership (beyond the delivery benefit mentioned above), but the largest priority should be in identifying ways to modernize on a continual basis.
Again, in my experience, modernization is difficult to prioritize and fund until there is an end-of-life or end-of-support scenario, at which point it becomes a “must do” priority, and causes a significant amount of delivery disruption in the process.
What I believe is a much better and healthier approach to modernization is a more disciplined, thoughtful approach that is akin to “urban renewal”, where there is an annual allocation of work directed at modernization on a prioritized basis (the criteria for which should be established through EA, given an understanding of other business demand), such that significant “events” are mitigated and it becomes a way of working on a sustained basis. In this way, the delineation between “keep the lights on” (KTLO) support, maintenance (which is where modernization efforts belong), and enhancement/ build-related work is important. In my experience, that second maintenance bucket is too often lumped into KTLO work, it is underserved/underfunded, and ultimately that creates periodic crises in IT to remediate things that should’ve been addressed far sooner (as a much lower cost) if a more disciplined portfolio management strategy was in place.
Inspire
In the interest of supporting the above objectives, having the right culture and skills to support ongoing evolution is imperative. To that end, the role of EA should be in helping to inform and guide the core skills needed to “lean forward” into advanced technology, while maintaining the right level of competency to support the footprint in place.
Again, this is where having a focus on modernization can help, as it creates a means to sunset legacy tools and technologies, to enable that continuous evolution of the skills the organization needs to operate (whether internally or externally sourced).
Perform
Finally, the role of EA in the production setting could be more or less difficult depending on how well the above capabilities are defined and supported in an enterprise. To the degree standards, rationalization, modernization, and the right culture and skills are in place, the role of EA would be helping to “tune” the environment to perform better and at a lower cost to operate.
Where there is a priority need for EA is ensuring there is an integrated approach to cyber security that aligns to development processes (e.g., DevSecOps) and a comprehensive, integrated strategy to monitor and manage performance in the production environment so that production incidents (using ITIL-speak) can be minimized and mitigated to the maximum degree possible.
Wrapping Up
Looking back on the various dimensions and priorities outlined above in relation to the role of EA, perhaps there isn’t much that I can argue is very different than what the role entailed five or ten years ago… establish standards, simplify / rationalize, modernize, retool, govern… that being said, the pace at which these things need to be accomplished and the criticality of doing them well is more important than ever with the increasing role technology plays in the digital enterprise. Like other dimensions required to establish excellence in IT, courageous leadership is where this needs to start, because it takes discipline to do things “right” while still doing them at a pace and with an agility that discerns the things that matter to an enterprise versus those that are simply ivory tower thinking.
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
I’ve been thinking about writing this article for a while, with the premise of “what does IT look like in the future?” In a digital economy, the role of technology in The Intelligent Enterprise will certainly continue to be creating value and competitive business advantage. That being said, one can reasonably assume a few things that are true today for medium to large organizations will continue to be part of that reality as well, namely:
The technology footprint will be complex and heterogenous in its makeup. To the degree that there is a history of acquisitions, even more so
Cost will always be a concern, especially to the degree it exceeds value delivered (this is explored in my article on Optimizing the Value of IT)
Agility will be important in adopting and integrating new capabilities rapidly, especially given the rate of technology advancement only appears to be accelerating over time
Talent management will be complex given the variety of technologies present will be highly diverse (something I’ve started to address in my Workforce and Sourcing Strategy Overview article)
My hope is to provide some perspective in this article on where I believe things will ultimately move in technology, in the underlying makeup of the footprint itself, how we apply capabilities against it, and how to think about moving from our current reality to that environment. Certainly, all of the five dimensions of what I outlined in my article on Creating Value Through Strategy will continue to apply at an overall strategy level (four of which are referenced in the bullet points above).
A Note on My Selfish Bias…
Before diving further into the topic at hand, I want to acknowledge that I am coming from a place where I love software development and the process surrounding it. I taught myself to program in the third grade (in Apple Basic), got my degree in Computer Science, started as a software engineer, and taught myself Java and .Net for fun years after I stopped writing code as part of my “day job”. I love the creative process for conceptualizing a problem, taking a blank sheet of paper (or white board), designing a solution, pulling up a keyboard, putting on some loud music, shutting out distractions, and ultimately having technology that solves that problem. It is a very fun and rewarding thing to explore those boundaries of what’s possible and balance the creative aspects of conceptual design with the practical realities and physical constraints of technology development.
All that being said, insofar as this article is concerned, when we conceptualize the future of IT, I wanted to put a foundational position statement forward to frame where I’m going from here, which is:
Just because something is cool and I can do it, doesn’t mean I should.
That is a very difficult thing to internalize for those of us who live and breathe technology professionally. Pride of authorship is a real thing and, if we’re to embrace the possibilities of a more capable future, we need to apply our energies in the right way to maximize the value we want to create in what we do.
The Producer/Consumer Model
Where the Challenge Exists Today
The fundamental problem I see in technology as a whole today (I realize I’m generalizing here) is that we tend to want to be good at everything, build too much, customize more than we should, and throw caution to the wind when it comes to things like standards and governance as inconveniences that slow us down in the “deliver now” environment in which we generally operate (see my article Fast and Cheap, Isn’t Good for more on this point).
Where that leaves us is bloated, heavy, expensive, and slow… and it’s not good. For all of our good intentions, IT doesn’t always have the best reputation for understanding, articulating, or delivering value in business terms and, in quite a lot of situations I’ve seen over the years, our delivery story can be marred with issues that don’t create a lot of confidence when the next big idea comes along and we want to capitalize on the opportunity it presents.
I’m being relatively negative on purpose here, but the point is to start with the humility of acknowledging the situation that exists in a lot of medium to large IT environments, because charting a path to the future requires a willingness to accept that reality and to create sustainable change in its place. The good news, from my experience, is there is one thing going for most IT organizations I’ve seen that can be a critical element in pivoting to where we need to be: a strong sense of ownership. That ownership may show up as frustration in the status quo depending on the organization itself, but I’ve rarely seen an IT environment where the practitioners themselves don’t feel ownership for the solutions they build, maintain, and operate or have a latent desire to make them better. There may be a lack of a strategy or commitment to change in many organizations, but the underlying potential to improve is there, and that’s a very good thing if capitalized upon.
Challenging the Status Quo
Pivoting to the future state has to start with a few critical questions:
Where does IT create value for the organization?
Which of those capabilities are available through commercially available solutions?
To what degree are “differentiated” capabilities or features truly creating value? Are they exceptions or the norm?
Using an example from the past, a delivery team was charged with solving a set of business problems that they routinely addressed through custom solutions, even though the same capabilities could be accomplished through integration of one or more commercially available technologies. From an internal standpoint, the team promoted the idea that they had a rapid delivery process, were highly responsive to the business needs they were meant to address, etc. The problem is that the custom approach actually cost more money to develop, maintain, and support, was considerably more difficult to scale. Given solutions were also continually developed with a lack of standards, their ability to adopt or integrate any new technologies available on the market was non-existent. Those situations inevitably led to new custom solutions and the costs of ownership skyrocketed over time.
This situation begs the question: if it’s possible to deliver equivalent business capability without building anything “in house”, why not do just that?
In the proverbial “buy versus build” argument, these are the reasons I believe it is valid to ultimately build a solution:
There is nothing commercially available that provides the capability at a reasonable cost
I’m referencing cost here, but it’s critical to understand the TCO implications of building and maintaining a solution over time. They are very often underestimated.
There is a commercially available solution that can provide the capability, but something about privacy, IP, confidentiality, security, or compliance-related concerns makes that solution infeasible in a way that contractual terms can’t address
I mention contracting purposefully here, because I’ve seen viable solutions eliminated from consideration over a lack of willingness to contract effectively, and that seems suboptimal by comparison with the cost of building alternative solutions instead
Ultimately, we create value in business capability enabled through technology, “who” built them doesn’t matter.
Rethinking the Model
My assertion is that we will obtain the most value and acceleration of business capabilities when we shift towards a producer/consumer model in technology as a whole.
What that suggests is that “corporate IT” largely adopts the mindset of the consumer of technologies (specifically services or components) developed by producers focused purely on building configurable, leverageable components that can be integrated in compelling ways into a connected ecosystem (or enterprise) of the future.
What corporate IT “produces” should be limited to differentiated capabilities that are not commercially available, and a limited set of foundational capabilities that will be outlined below. By trying to produce less and thinking more as a consumer, this should shift the focus internally towards how technology can more effectively enable business capability and innovation and externally towards understanding, evaluating, and selecting from the best-of-breed capabilities in the market that help deliver on those business needs.
The implication, of course for those focused on custom development, would be to move towards those differentiated capabilities or entirely towards the producer side (in a product-focused environment), which honestly could be more satisfying than corporate IT can be for those with a strong development inclination.
The cumulative effect of these adjustments should lead to an influx of talent into the product community, an associated expansion of available advanced capabilities in the market, and an accelerated ability to eventually adopt and integrate those components in the corporate environment (assuming the right infrastructure is then in place), creating more business value than is currently possible where everyone tries to do too much and sub-optimizes their collective potential.
Learning from the Evolution of Infrastructure
The Infrastructure Journey
You don’t need to look very far back in time to remember when the role of a CTO was largely focused on managing data centers and infrastructure in an internally hosted environment. Along the way, third parties emerged to provide hosting services and alleviate the need to be concerned with routine maintenance, patching, and upgrades. Then converged infrastructure and the software-defined data center provided opportunities to consolidate and optimize that footprint and manage cost more effectively. With the rapid evolution of public and private cloud offerings, the arguments for managing much of your own infrastructure beyond those related specifically to compliance or legal concerns are very limited and the trajectory of edge computing environments is still evolving fairly rapidly as specialized computing resources and appliances are developed. The learning being: it’s not what you manage in house that matters, it’s the services you provide relative to security, availability, scalability, and performance.
Ok, so what happens when we apply this conceptual model to data and applications? What if we were to become a consumer of services in these domains as well? The good news is that this journey is already underway, the question is how far we should take things in the interest of optimizing the value of IT within an organization.
The Path for Data and Analytics
In the case of data, I think about this area in two primary dimensions:
How we store, manage, and expose data
How we apply capabilities to that data and consume it
In terms of storage, the shift from hosted data to cloud-based solutions is already underway in many organizations. The key levers continue to be ensuring data quality and governance, finding ways to minimize data movement and optimize data sharing (while facilitating near real-time analytics), and establishing means to expose data in standard ways (e.g., virtualization) that enable downstream analytic capabilities and consumption methods to scale and work consistently across an enterprise. Certainly, the cost of ingress and egress of data across environments is a key consideration, especially where SaaS/PaaS solutions are concerned. Another opportunity continues to be the money wasted on building data lakes (beyond archival and unstructured data needs) when viable platform solutions in that space are available. From my perspective, the less time and resources spent on moving and storing data to no business benefit, the more energy that can be applied to exposing, analyzing, and consuming that data in ways that create actual value. Simply said, we don’t create value in how or where we store data, we create value in how consume it.
On the consumption side, having a standards-based environment with a consistent method for exposing data and enabling integration will lend itself well to tapping into the ever-expanding range of analytical tools on the market, as well as swapping out one technology for another as those tools continue to evolve and advance in their capabilities over time. The other major pivot being to minimize the amount of “traditional” analytical reporting and business intelligence solutions to more dynamic data apps that leverage AI to inform meaningful end-user actions, whether that’s for internal or external users of systems. Compliance-related needs aside, at an overall level, the primary goal of analytics should be informed action, not administrivia.
The Shift In Applications
The challenge in the applications environment is arbitrating the balance between monolithic (“all in”) solutions, like ERPs, and a fully distributed component-based environment that requires potentially significant management and coordination from an IT standpoint.
Conceptually, for smaller organizations, where the core applications (like an ERP suite + CRM solution) represent the majority of the overall footprint and there aren’t a significant number of specialized applications that must interoperate with them, it likely would be appropriate and effective to standardize based on those solutions, their data model, and integration technologies.
On the other hand, the more diverse and complex the underlying footprint is for a medium- to large-size organization, there is value in looking at ways to decompose these relatively monolithic environments to provide interoperability across solutions, enable rapid integration of new capabilities into a best-of-breed ecosystem, and facilitate analytics that span multiple platforms in ways that would be difficult, costly, or impossible to do within any one or two given solutions. What that translates to, in my mind, is an eventual decline of the monolithic ERP-centric environment to more of a service-driven ecosystem where individually configured capabilities are orchestrated through data and integration standards with components provided by various producers in the market. That doesn’t necessarily align to the product strategies of individual companies trying to grow through complementary vertical or horizontal solutions, but I would argue those products should create value at an individual component level and be configurable such that swapping out one component of a larger ecosystem should still be feasible without having to abandon the other products in that application suite (that may individually be best-of-breed) as well.
Whether shifting from a highly insourced to a highly outsourced/consumption-based model for data and applications will be feasible remains to be seen, but there was certainly a time not that long ago when hosting a substantial portion of an organization’s infrastructure footprint in the public cloud was a cultural challenge. Moving up the technology stack from the infrastructure layer to data and applications seems like a logical extension of that mindset, placing emphasis on capabilities provided and value delivered versus assets created over time.
Defining Critical Capabilities
Own Only What is Essential
Making an argument to shift to a consumption-oriented mindset in technology doesn’t mean there isn’t value in “owning” anything, rather it’s meant to be a call to evaluate and challenge assumptions related to where IT creates differentiated value and to apply our energies towards those things. What can be leveraged, configured, and orchestrated, I would buy and use. What should be built? Capabilities that are truly unique, create competitive advantage, can’t be sourced in the market overall, and that create a unified experience for end users. On the final point, I believe that shifting to a disaggregated applications environment could create complexity for end users in navigating end-to-end processes in intuitive ways, especially to the degree that data apps and integrated intelligence becomes a common way of working. To that end, building end user experiences that can leverage underlying capabilities provided by third parties feels like a thoughtful balance between a largely outsourced application environment and a highly effective and productive individual consumer of technology.
Recognize Orchestration is King
Workflow and business process management is not a new concept in the integration space, but it’s been elusive (in my experience) for many years for a number of reasons. What is clear at this point is that, with the rapid expansion in technology capabilities continuing to hit the market, our ability to synthesize a connected ecosystem that blends these unique technologies with existing core systems is critical. The more we can do this in consistent ways, the more we shift towards a configurable and dynamic environment that is framework-driven, the more business flexibility and agility we will provide… and that translates to innovation and competitive advantage over time. Orchestration is a critical piece of deciding which processes are critical enough that they shouldn’t be relegated to the internal workings of a platform solution or ERP, but taken in-house, mapped out, and coordinated with the intention of creating differentiated value that can be measured, evaluated, and optimized over time. Clearly the scalability and performance of this component is critical, especially to the degree there is a significant amount of activity being managed through this infrastructure, but I believe the transparency, agility, and control afforded in this kind of environment would greatly outweigh the complexity involved in its implementation.
Put Integration in the Center
In a service-driven environment, clearly the infrastructure for integration, streaming in particular, along with enabling a publish and subscribe model for event-driven processing, will be critical for high-priority enterprise transactions. The challenge in integration conversations in my experience tends to be defining the transactions that “matter”, in terms of facilitating interoperability and reuse, and those that are suitable for point-to-point, one off connections. There is ultimately a cost for reuse when you try to scale, and there is discipline needed to arbitrate those decisions to ensure they are appropriate to business needs.
Reassess Your Applications/Services
With any medium to large organization, there is likely technology sprawl to be addressed, particularly if there is a material level of custom development (because component boundaries likely won’t be well architected) and acquired technology (because of the duplication it can cause in solutions and instances of solutions) in the landscape. Another complicating factor could be the diversity of technologies and architectures in place, depending on whether or not a disciplined modernization effort exists, the level of architecture governance in place, and rate and means by which new technologies are introduced into the environment. All of these factors call for a thoughtful portfolio strategy, to identify critical business capabilities and ensure the technology solutions meant to enable them are modern, configurable, rationalized, and integrated effectively from an enterprise perspective.
Leverage Data and Insights, Then Optimize
With analytics and insights being a critical capability to differentiated business performance, an effective data governance program with business stewardship, selecting the right core, standard data sets to enable purposeful, actionable analytics, and process performance data associated with orchestrated workflows are critical components of any future IT infrastructure. This is not all data, it’s the subset that creates significant business value to justify the investment in making it actionable. As process performance data is gathered through the orchestration approach, analytics can be performed to look for opportunities to evolve processes, configurations, rules, and other characteristics of the environment based on key business metrics to improve performance over time.
Monitor and Manage
With the expansion of technologies and components, internal and external to the enterprise environment, having the ability to monitor and detect issues, proactively take action, and mitigate performance, security, or availability issues will become increasingly important. Today’s tools are too fragmented and siloed to achieve the level of holistic understanding that is needed between hosted and cloud-based environments, including internal and external security threats in the process.
Secure “Everything”
While zero trust and vulnerability management risk is expanding at a rate that exceeds an organization’s ability to mitigate it, treating security as a fundamental requirement of current and future IT environments is a given. The development of a purposeful cyber strategy, prioritizing areas for tooling and governance effectively, and continuing to evolve and adapt that infrastructure will be core to the DNA of operating successfully in any organization. Security is not a nice to have, it’s a requirement.
The Role of Standards and Governance
What makes the framework-driven environment of the future work is ultimately having meaningful standards and governance, particularly for data and integration, but extending into application and data architecture, along with how those environments are constructed and layered to facilitate evolution and change over time. Excellence takes discipline and, while that may require some additional investment in cost and time during the initial and ongoing stages of delivery, it will easily pay itself off in business agility, operating cost/ cost of ownership, and risk/exposure to cyber incidents over time.
The Lending Example
Having spent time a number of years ago understanding and developing strategy in the consumer lending domain, the similarities in process between direct and indirect lending, prime and specialty / sub-prime, from simple products like credit card to more complex ones like mortgage is difficult to ignore. That being said, it isn’t unusual for systems to exist in a fairly siloed manner, from application to booking, from document preparation, into the servicing process itself.
What’s interesting, from my perspective, is where the differentiation actually exists across these product sets: in the rules and workflow being applied across them, while the underlying functions themselves are relatively the same. As an example, one thing that differentiates a lender is their risk management policy, not necessarily the tool they use to assess to implement their underwriting rules or scoring models per se. Similarly, whether pulling a credit score is part of the front end of the process in something like credit card and an intermediate step in education lending, having a configurable workflow engine could enable origination across a diverse product set with essentially the same back-end capabilities and likely at a lower operating cost.
So why does it matter? Well, to the degree that the focus shifts from developing core components that implement relatively commoditized capability to the rules and processes that enable various products to be delivered to end consumers, the speed with which products can be developed, enhanced, modified, and deployed should be significantly improved.
Ok, Sounds Great, But Now What?
It Starts with Culture
At the end of the day, even the best designed solutions come down to culture. As I mentioned above, excellence takes discipline and, at times, patience and thoughtfulness that seems to contradict the speed with which we want to operate from a technology (and business) standpoint. That being said, given the challenges that ultimately arise when you operate without the right standards, discipline, and governance, the outcome is well worth the associated investments. This is why I placed courageous leadership as the first pillar in the five dimensions outlined in my article on Excellence by Design. Leadership is critical and, without it, everything else becomes much more difficult to accomplish.
Exploring the Right Operating Model
Once a strategy is established to define the desired future state and a culture to promote change and evolution is in place, looking at how to organize around managing that change is worth consideration. I don’t necessarily believe in “all in” operating approaches, whether it is a plan/build/run, product-based orientation, or some other relatively established model. I do believe that, given leadership and adaptability are critically needed for transformational change, looking at how the organization is aligned to maintaining and operating the legacy environment versus enabling establishment and transition to the future environment is something to explore. As an example, rather than assuming a pure product-based orientation, which could mushroom into a bloated organization design where not all leaders are well suited to manage change effectively, I’d consider organizing around a defined set of “transformation teams” that operate in a product-oriented/iterative model, but basically take on the scope of pieces of the technology environment, re-orient, optimize, modernize, and align them to the future operating model, then transition those working assets to different leaders that maintain or manage those solutions in the interest of moving to the next set of transformation targets. This should be done in concert with looking for ways to establish “common components” teams (where infrastructure like cloud platform enablement can be a component as well) that are driven to produce core, reusable services or assets that can be consumed in the interest of ultimately accelerating delivery and enabling wider adoption of the future operating model for IT.
Managing Transition
One of the consistent challenges with any kind of transformative change is moving between what is likely a very diverse, heterogenous environment to one that is standards-based, governed, and relatively optimized. While it’s tempting to take on too much scope and ultimately undermine the aspirations of change, I believe there is a balance to be struck in defining and establishing some core delivery capabilities that are part of the future infrastructure, but incrementally migrating individual capabilities into that future environment over time. This is another case where disciplined operations and disciplined delivery come into play so that changes are delivered consistently but also in a way that is sustainable and consistent with the desired future state.
Wrapping Up
While a certain level of evolution is guaranteed as part of working in technology, the primary question is whether we will define and shape that future or be continually reacting and responding to it. My belief is that we can, through a level of thoughtful planning and strategy, influence and shape the future environment to be one that enables rapid evolution as well as accelerated integration of best-of-breed capabilities at a pace and scale that is difficult to deliver today. Whether we’ll truly move to a full producer/consumer type environment that is service based, standardized, governed, orchestrated, fully secured, and optimized is unlikely, but falling short of excellence as an aspiration would still leave us in a considerably better place than where we are today… and it’s a journey worth making in my opinion.
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
In my article on Excellence by Design, the fifth dimension I reference is “Delivering at Speed”, basically understanding the delicate balance to be struck in technology with creating value on a predictable, regular basis while still ensuring quality.
One thing that is true is software development is messy and not for the faint of heart or risk averse. The dynamics of a project, especially if you are doing something innovative, tend to be in flux at a level that requires you to adapt on the fly, make difficult decisions, accept tradeoffs, and abandon the idea that “perfection” even exists. You can certainly try to design and build out an ivory tower concept, but the probability is that you’ll never deliver it or, in the event you do, that it will take you so long to make it happen that your solution will be obsolete by the time you finally go live.
To that end, this article is meant to share a set of delivery stories from my past. In three cases, I was told the projects were “impossible” or couldn’t be delivered at the outset. In the other two, the level of complexity or size of the challenge was relatively similar, though they weren’t necessarily labeled “impossible” at any point. In all cases, we delivered the work. What will follow, in each case, are the challenges we faced, what we did to address them, and what I would do differently if the situation happened again. Even in success, there is ample opportunity to learn and improve.
Looking across these experiences, there is a set of things I would say apply in nearly all cases:
Commitment to Success
It has to start here, especially with high velocity or complex projects. When you decide you’re going to deliver day one, every obstacle is a problem you solve, and not a reason to quit. Said differently, if you are continually looking for reasons to fail, you will.
Adaptive Leadership
Change is part of delivering technology solutions. Courageous leadership that embraces humility, accepts adversity, and adapts to changing conditions will be successful far more than situations where you hold onto original assumptions beyond their usefulness
Business/Technology Collaboration
Effective communication, a joint investment in success, and partnership make a significant difference in software delivery. The relationships and trust it takes can be an achievement in itself, but the quality of the solution and ability to deliver is definitely stronger where this is in place
Timely Decision Making
As I discuss in my article On Project Health and Transparency, there are “points of inflection” that occur on projects of any scale. Your ability to respond, pivot, and execute in a new direction can be a critical determinant to delivering
Allowing for the Unknown
With any project of scale or reasonable complexity, there will be pure “unknown” (by comparison with “known unknown”) that is part of the product scope, the project scope, or both. While there is always a desire to deliver solutions as quickly as possible with the lowest level of effort (discussed in my article Fast and Cheap Isn’t Good), including some effort or schedule time proactively as contingency for the unknown is always a good idea
Excessive Complexity
One thing that is common across most of these situations is that the approach to the solution was building a level of flexibility or capability that probably was beyond what was needed in practice. This is not unusual on new development, especially where significant funding is involved, because those bells and whistles create part of the appeal that justifies the investment to begin with. That being said, if a crawl-walk-run type approach that evolves to a more feature-rich solution is possible, the risk profile for the initial efforts (and associated cost) will likely be reduced substantially. Said differently, you can’t generate return on investment for a solution you never deliver
The remainder of this article is focused on sharing a set of these delivery stories. I’ve purposefully reordered and made them a bit abstract in the interest of maintaining a level of confidentiality on the original efforts involved. In practice, these kinds of things happen on projects all the time, the techniques referenced are applicable in many situations, and the specifics aren’t as important.
Delivering the “Impossible”
Setting the Stage
I’ll always remember how this project started. I had finished up my previous assignment and was wondering what was next. My manager called me in and told me about a delivery project I was going to lead, that it was for a global “shrink wrap” type solution, that a prototype had been developed, that I needed to design and build the solution… but not to be too concerned because the timeframe was too short, the customer was historically very difficult to work with, and there was “no way to deliver the project on time”. Definitely not a great moment for motivating and inspiring an employee, but my manager was probably trying to manage my expectations given the size of the challenge ahead.
Some challenges associated with this effort:
The nature of what was being done, in terms of automating an entirely manual process had never been done before. As such, the requirements didn’t exist at the outset, beyond a rudimentary conceptual prototype that demonstrated the desired user interface behavior
I was completely unfamiliar with the technology used for the prototype and needed to immediately assess whether to continue forward with it or migrate into a technology I knew
The timeframe was very aggressive and the customer was notorious for not delivering on time
We needed everything we developed to fit on a single 3.5-inch diskette for distribution, and it was not a small application to develop
What Worked
Regardless of any of the mechanics, having been through a failed delivery early in my career, my immediate reaction to hearing the project was doomed from the outset was that there was no way we were going to allow that to happen.
Things that mattered in the delivery:
Within the first two weeks, I both learned the technology that was used for the prototype and was able to rewrite it (it was a “smoke and mirrors” prototype) into a working, functional application. Knowing that the underlying technology could do what was needed in terms of the end user experience, we took the learning curve impact in the interest of reducing the development effort that would have been required to try and create a similar experience using other technologies we were using at the time
Though we struggled initially, eventually we brought a leader from the customer team to our office to work alongside us (think Agile before Agile) so we could align requirements with our delivery iterations and produce application sections for testing in relatively complete form
We had to develop everything as compact as possible given the single disk requirement so the distribution costs wouldn’t escalate (10s of thousands of disks were being shipped globally)
All of the above having helped, the thing that made the largest difference was the commitment of the team (ultimately me and three others) to do whatever was required to deliver. The brute force involved was substantial, and we worked increasing hours, week-after-week, until we pulled seven all night sessions in the last ten days leading up to shipping the software to the production company. It was an exceptionally difficult pace to sustain, but we hit the date, and the “impossible” was made possible.
What I Would Change
While there is a great deal of satisfaction that comes from meeting a delivery objective, especially an aggressive one, there are a number of things I would have wanted to do differently in retrospect:
We grew the team over time in a way that created additional pressure in the latter half of the project. Given we started with no requirements and were doing something that had never been done, I’m not sure how we could have estimated the delivery to know we needed more help sooner, but minimally, from a risk standpoint, there was too much work spread too thinly for too long, and it made things very challenging later on to catch up
As I mentioned above, we eventually transitioned to have an integrated business/technology team that delivered the application with tight collaboration. This should have happened sooner, but we collectively waited until it became a critical issue before it escalated to a level than anyone really addressed it. That came when we actually ran out of requirements late one night (it was around 2am) to the point that we needed to stop development altogether. The friction this created between the customer and development team was difficult to work through and is something the change in approach made much better, just too late in the project
From a software standpoint, given it was everyone on the team’s first foray into new technology (starting with me), there was a lot we could have done to design the solution better, but we were unfortunately learning on the job. This is another one that I don’t know how we could have offset, beyond bringing in an expert developer to help us work through the design and sanity check our work, but it was such new technology at the time, that I don’t know that was really a viable option or that such expertise was available
This was also my first global software solution and I didn’t appreciate the complexities of localization enough to avoid making some very basic mistakes that showed up late in the delivery process.
Working Outside the Service Lines
Setting the Stage
This project honestly was sort of an “accidental delivery”, in that there was no intention from a services standpoint to take on the work to begin with. Similar to my product development experience, there was a customer need to both standardize and automate what was an entirely manual process. Our role, and mine in particular, was to work with the customer, understand the current process across the different people performing it, then look for a way to both standardize the workflow itself (in a flexible enough way that everyone could be trained and follow that new process), then to define the opportunities to automate it such that a lot of the effort done in spreadsheets (prone to various errors and risks) could be built into an application that would make it much easier to perform the work.
The point of inflection came when we completed the process redesign and, with no implementation partner in place (and no familiarity with the target technologies in the customer team), the question became “who is going to design and build this solution?” Having a limited window of time, a significant amount of seasonal business that needed to be processed, and the right level of delivery experience, I offered to shift from a business analyst to the technology lead on the project. With a substantial challenge ahead, I was again told what we were trying to do could never be done in the time we had. Having had previous success in that situation, I took it as a challenge to figure out what we needed to do to deliver.
Some challenges associated with this effort:
The timeframe was the biggest challenge, given we had to design and develop the entire application from scratch. The business process was defined, but there was no user interface design, it was built using relatively new technology, and we needed to provide the flexibility users were used to having in Excel while still enforcing a new process
Given the risk profile, the customer IT manager assumed the effort would fail and consequently provided only a limited amount of support and guidance until the very end of the project, which created some integration challenges with the existing IT infrastructure
Finally, given that there were technology changes occurring in the market as a whole, we encountered a limitation in the tools (given the volume of data we were processing) that nearly caused us to hit a full stop mid-development
What Worked
Certainly, an advantage I had coming into the design and delivery effort was that I helped develop the new process and was familiar with all the assumptions we made during that phase of the work. In that respect, the traditional disconnect between “requirements” and “solution” was fairly well mitigated and we could focus on how to design the interface, not the workflow or data required across the process.
Things that mattered in the delivery:
One major thing that we did well from the outset was work in a prototype-driven approach, engaging with the end customer, sketching out pieces of the process, mocking them up, confirming the behavior, then moving onto the next set of steps while building the back end of the application offline. Given we only had a matter of months, the partnership with the key business customer and their investment in success made a significant difference in the efficiency of our delivery process (again, very Agile before Agile)
Despite the lack of support from customer IT leadership standpoint, a key member of their team invested in the work, put in a tremendous amount of effort, and helped keep morale positive despite the extreme hours we worked for essentially the entire duration of the project
While not as pleasant, another thing that contributed to our success was managing performance actively. Wanting external expertise (and needing the delivery capacity), we pulled in additional contracting help, but had inconsistent experience with the commitment level of the people we brought in. Simply said: you can’t deliver high velocity project with a half-hearted commitment. It doesn’t work. The good news is that we didn’t delay decisions to pull people where the contributions weren’t where they needed to be
On the technology challenges, when serious issues arose with our chosen platform, I took a fairly methodical approach to isolating and resolving the infrastructure issues we had. The result was a very surgical and tactical change to how we deployed the application without needing to do a more complex (and costly) end user upgrade that initially appeared to be our only option
What I Would Change
While the long hours and months without a day off ultimately enabled us to deliver the project, there were certainly learnings from this effort that I took away despite our overall success.
Things I would have wanted to do differently in retrospect:
While the customer partnership was very effective overall, one area that where we didn’t engage early enough was with the customer analytics organization. Given the large volume of data, heavy reliance on computational models, and the capability for users to select data sets to include in the calculations being performed, we needed more support than expected to verify our forecasting capabilities were working as expected. This was actually a gap in the upstream process design work itself, as we identified the desired capability (the “feature”) and where it would occur within the workflow, but didn’t flesh out the specific calculations (the “functionality”) that needed to be built to support it. As a result, we had to work through those requirements during the development process itself, which was very challenging
From a technology standpoint, we assumed a distributed approach for managing data associated with the application. While this reduced the data footprint for individual end users and simplified some of the development effort, it actually made the maintenance and overall analytics associated with the platform more complex. Ultimately, we should have centralized the back end of the application. This is something that was done subsequent to the initial deployment, though I’m not certain if we would have been able to take that approach with the initial release and still made the delivery date
From a services standpoint, while I had the capability to lead the design and delivery of the application, the work itself was outside the core service offerings of our firm. Consequently, while we delivered for the customer, there wasn’t an ability to leverage the outcome for future work, which is important in consulting in building your business. In retrospect, while I wouldn’t have learned and gotten the experience, we should have engaged a partner in the delivery and played a different role in implementation
Project Extension
Setting the Stage
Early in my experience of managing projects, I had the opportunity to take on an effort where the entire delivery team was coming off a very difficult, long project. I was motivated and wanted to deliver, everyone else was pretty tired. The guidance I received at the outset was not to expect very much, and that the road ahead was going to be very bumpy.
Some challenges associated with this effort:
As I mentioned above, the largest challenge was a lack of motivation, which was a strength in other high pressure deliveries I’d encountered before. I was unused to dealing with it from a leadership standpoint and didn’t address it as effectively as I should have
From a delivery standpoint, the technical solution was fairly complex, which made the work and testing process challenging, especially in the timeframe we had for the effort
At a practical level, the team was larger than I had previous experience leading. Leading other leaders wasn’t something I had done before, which led me to making all the normal mistakes that comes with doing so for the first time, which didn’t help on either efficiency or sorely needed motivation
What Worked
While the project started with a team that was already burned out, the good news is that the base application was in place, the team understood the architecture, and the scope was to buildout existing capabilities on top of a reasonably strong foundation. There was a substantial amount of work to be performed in a relatively short timeframe, but the good news is that we weren’t starting from scratch and there was recent evidence that the team could deliver.
Things that mattered in the delivery:
The client partnership was strong, which helped both in addressing requirements gaps and, more importantly, in performing customer testing in both an efficient and effective manner given the accelerated timeframe
At the outset of the effort, we revisited the detailed estimates and realigned the delivery team to balance the work more effectively across sub-teams. While this required some cross-training, we reduced overall risk in the process
From a planning standpoint, we enlisted the team to try out an aggressive approach where we set all the milestones slightly ahead of their expected delivery date. Our assumption was that, by trying to beat our targets, we could create some forward momentum that would create “effort reserve” to use for unexpected issues and defects later in the project
Given the pace of the work and size of the delivery team, we had the benefit of strong technical leads who helped keep the team focused and troubleshoot issues as and when we encountered them
What I Would Change
Like other projects I’m covering in this article, the team put in the effort to deliver on our commitments, but there were definitely learnings that came through the process.
Things I would have wanted to do differently in retrospect:
Given it was my first time leading a larger team under a tight timeline, I pushed where I should have inspired. It was a learning experience that I’ve used for the benefit of others many times since. While I don’t know what impact it might have had on the delivery itself, it might have made the experience of the journey better overall
From a staffing standpoint, we consciously stuck to the team that helped deliver the initial project. Given the burnout was substantial and we needed to do a level of cross-training anyway, it might have been a good idea for us to infuse some outside talent to provide fresh perspective and much needed energy from a development standpoint
Finally, while it was outside the scope of work itself, this project was an example of a situation I’ve encountered a few times over the years where the requirements of the solution and its desired capabilities were overstated and translated into a lot of complexity in architecture and design. My guess is that we built a lot of flexibility that wasn’t required in practice
Modernization Program
Setting the Stage
What I think of as another “impossible” delivery came with a large-scale program that started off with everyone but the sponsors assuming it would fail.
Some challenges associated with this effort:
The largest thing stacked against us was two failed attempts to deliver the project in the past, with substantial costs associated with each. Our business partners were well aware of those failures, some having participated in them, and the engagement was tentative at best when we started to move into execution
We also had significant delivery issues with our primary technology partner that resulted in them being transitioned out mid-implementation. Unfortunately, they didn’t handle the situation gracefully, escalated everywhere, told the CIO the project would never be successful, and the pressure on the team to hit the first release on schedule was increased by extension
From an architecture standpoint, the decision was made to integrate new technology with existing legacy software wherever possible, which added substantial development complexity
The scale and complexity for a custom development effort was very significant, replacing multiple systems with one new, integrated platform, and the resulting planning and coordination was challenging
Given the solution replaced existing production systems, there was a major challenge in keeping capabilities in sync between the new application and ongoing enhancementsbeing implemented in parallel by the legacy application delivery team
What Worked
Things that mattered in the delivery:
As much as any specific decision or “change”, what contributed to the ultimate success of the program was our continuous evolution of the approach as we encountered challenges. With a program of the scale and complexity we were addressing, there was no reasonable way to mitigate the knowledge and requirements risks that existed at the outset. What we did exceptionally well was to pivot and work through obstacles as they appeared… in architecture, requirements, configuration management, and other aspects of the work. That adaptive leadership was critical in meeting our commitments and delivering the platform
The decision to change delivery partners was a significant disruption mid-delivery that we managed with a weekly transition management process to surface and address risks and issues on an ongoing basis. The governance we applied was very tight across all the touchpoints into the program and it helped us ultimately onboard the new partner and reduce risk on the first delivery date, which we ultimately met
To accelerate overall development across the program, we created both framework and common components teams, leveraging reuse to help reduce risk and effort required in each of the individual product teams. While there was some upfront coordination to decide how to arbitrate scope of work, we reduced the overall effort in the program substantially and could, in retrospect, have built even more “in common” than we did
Finally, to keep the new development in sync with the current production solutions, we integrated the program with ongoing portfolio management processes from work-intake and estimation through delivery as if we were already in production. This helped us avoid rework that would have come if we had to retrofit those efforts post-development in the pre-production stage of the work
The net result of a lot of adjustments and a very strong, committed set of delivery teams was that we met our original committed launch date and moved into the broader deployment of the program.
What I Would Change
The learnings from a program of this scale could constitute an article all on their own, so I’ll focus on a subset that were substantial at an overall level.
Things I would have wanted to do differently in retrospect:
As I mentioned in the point on common components above, the mix between platform and products wasn’t right. Our development leadership was drawn from the legacy systems, which helped, given they were familiar with the scope and requirements, but the downside was that the new platform ended up being siloed in a way that mimicked the legacy environment. While we started to promote a culture of reuse, we could have done a lot more to reduce scope in the product solutions and leverage the underlying platform more
Our product development approach should have been more framework-centric, being built towards broader requirements versus individual nuances and exceptions. There was a considerable amount of flexibility architected into the platform itself, but given the approach was focused on implementing every requirement as if it was an exception, the complexity and maintenance cost of the resulting platform was higher than it should have been
From a transition standpoint, we should have replaced our initial provider earlier, but given the depth and nature of their relationships and a generally risk-averse mindset, we gave them a matter of months to fail, multiple times, before making the ultimate decision to change. Given there was a substantial difference in execution once we completed transition, we waited longer than we should have
Given we were replacing multiple existing legacy solutions, there was a level of internal competition that was unhealthy and should have been managed more effectively from a leadership standpoint. The impact was that there were times the legacy teams were accelerating capabilities on systems we knew were going to be retired in what appeared to be an effort to undermine the new platform
Project Takeover
Setting the Stage
We had the opportunity in consulting to bid on a development project from our largest competitor that was stopped mid-implementation. As part of the discovery process, we received sample code, testing status, and the defect log at the time the project was stopped. We did our best to make conservative assumptions on what we were inheriting and the accuracy of what we received, understanding we were in a bidding situation and had to lean into discomfort and price the work accordingly. In practice, the situation we took over was far worse than expected.
Some challenges associated with this effort:
While the quality of solution was unknown at the outset, we were aware of a fairly high number of critical defects. Given the project didn’t complete testing and some defects were likely to be blocking the discovery of others, we decided to go with a conservative assumption that the resulting severe defect count could be 2x the set reported to us. In practice the quality was far worse and there were 6x more critical defects than were reported to us at the bidding stage
In concert with the previous point, while the testing results provided a mixed sense of progress, with some areas being in the “yellow” (suggesting a degree of stability) and others in the “red” (needing attention), in practice, the testing regimen itself was clearly not thorough and there wasn’t a single piece of the application that was better than a “red” status, most of them more accurately “purple” (restart from scratch), if such a condition even existed.
Given the prior project was stopped, there was a very high level of visibility, and the expectation to pick up and use what was previously built was unrealistic to a large degree, given the quality of work was so poor
Finally, there was considerable resource contention with the client testing team not beingdedicated to the project and, consequently, it became very difficult to verify the solution as we progressed through stabilizing the application and completing development
What Worked
While the scale and difficulty of the effort was largely underrepresented at the outset of the work, as we dug in and started to understand the situation, we made adjustments that ultimately helped us stabilize and deliver the program.
Things that mattered in the delivery:
Our challenges in testing aside, we had the benefit of a strong client partnership, particularly in program management and coordination, which helped given the high level of volatility we had in replanning as we progressed through the effort
Given we were in a discovery process for the first half of the project, our tracking and reporting methods helped manage expectations and enable coordination as we continued to revise the approach and plan. One specific method we used was showing the fix rate in relation to the level of undiscovered defects and then mapping that additional effort directly to the adjusted plan. When we visibly accounted for it in the schedule, it helped build confidence that we actually were “on plan” where we had good data and making consistent progress where we had taken on additional, unforeseen scope as well. Those items were reasonably outside our control as a partner, so the transparency helped us given the visibility and pressure surrounding the work was very high
Finally, we mitigated risk in various situations by making the decision to rewrite versus fix what was handed over at the outset of the project. The code quality being as poor as it was and requirements not being met, we had to evaluate whether it was easier to start over and work with a clean slate versus trying to reverse engineer something we knew didn’t work. These decisions helped us reduce effort and risk, and ultimately deliver the program
What I Would Change
Things I would have wanted to do differently in retrospect:
As is probably obvious, the largest learning was that we didn’t make conservative enough assumptions in what we were inheriting with the project, the accuracy of testing information provided, or the code samples being “representative” of the entire codebase. In practice, though, had we estimated the work properly and attached the actual cost for doing the project, we might not have “sold” the proposal either…
We didn’t factor changing requirements into our original estimates properly, partially because we were told the project was mid-testing, and largely built prior to our involvement. This added volatility into the project as we already needed to stabilize the application without realizing the requirements weren’t frozen. In retrospect, we should have done a better job probing on this during the bidding process itself
Finally, we had challenges maintaining momentum where a dedicated client testing team would have made the iteration process more efficient. It may have been necessary to lean on augmentation or a partner to help balance ongoing business and the project, but the cost of extending the effort was substantial enough that it likely was worth investigating
Wrapping Up
As I said at the outset, having had the benefit of delivering a number of “impossible” projects over the course of my career, I’ve learned a lot about how to address the mess that software development can be in practice, even with disciplined leadership. That being said, the great thing about having success is that it also tends to make you a lot more fearless the next time a challenge comes up, because you have an idea what it takes to succeed under adverse conditions.
I hope the stories were worth sharing. Thanks for spending the time to read them. Feedback is welcome as always.