Overview
It’s impossible to scroll through a news feed and miss the energy surrounding AI and its potential to transform. The investment in technology as a strategic differentiator is encouraging to see, particularly as a person who thrives on change and innovation. It is, however, also concerning that the ways in which it is often described are reminiscent of other technology advances of the past… CRM, BigData, .com… where there was an immediate surge in spending without a clear set of outcomes in mind, operating approach, or business architecture established for how to leverage it effectively. Consequently, while a level of experimentation is always good in the interest of learning and exploring, a lot of money and time can be wasted (and technical debt created) without necessarily creating any meaningful business value through the process.
For the purposes of this article, I’m going to focus on five dimensions of AI and how I’m thinking about them:
- Framing the Problem – Thinking about how AI will be used in practice
- The Role of Compute – Considering the needs for processing moving forward
- Revisiting Data Strategy – Putting AI in the context of the broader data landscape
- Simplifying “Intelligence” – Exploring the end user impact of AI
- Thinking About Multi-Cloud – Contemplating how to approach AI in a distributed environment
This topic is very extensive, so I’ll try to keep the thoughts at a relatively high-level to start and dive into more specifics in future articles as appropriate.
Framing the Problem
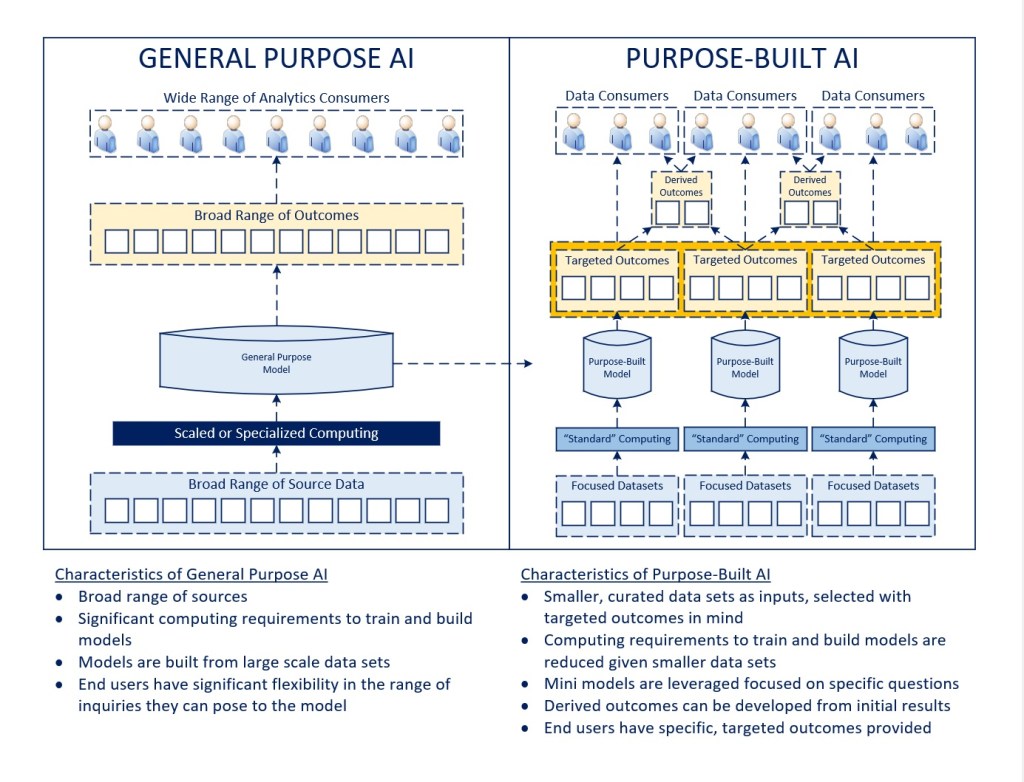
Considering the Range of Opportunities
While a lot of the attention surrounding Generative AI over the last year has been focused on content generation for research, communication, software development, and other purposes, I believe the focus for how AI can create business value will shift substantially to be more outcome-driven and directed at specific business problems. In this environment, smaller, more focused data sets (e.g., incorporating process, market, equipment, end user, and environmental data) will be analyzed to understand causal relationships in the interest of producing desired business outcomes (e.g., optimizing process efficiency, improving risk management, increasing safety) and content (e.g., just in time training, adaptive user experiences). Retrieval-Augmented Generation (RAG) models are an example of this today, with a purpose-built model leveraging a foundational large language model to establish context for a more problem-specific solution.
This is not to suggest that general purpose models will decline in utility, but rather that I believe those applications will be better understood, mature, and become integrated where they create the most value (in relatively short order). The focus will then shift towards areas where more direct business value can be obtained through an evolution of these technologies.
For that to occur, the fundamentals of business process analysis need to regain some momentum to overcome the ‘silver bullet’ mentality that seems largely prevalent with these technologies today. It is, once again, a rush towards “the cool versus the useful” towards my opening remark about how current AI discussions feel a lot like conversations at the start of the .com era, and the sooner we shift towards a disciplined approach to leveraging these technology advancements, the better.
The opportunity will be to look at how we can leverage what these models provide, in terms of understanding multi-dimensional relationships across large sets of data, but then extending the concept to become more deterministic in terms of what decisions under a given set of conditions are most likely to bring about desired outcomes (i.e., causal models). This is not where we are today, but is where I believe these technologies are meant to go in the near future. Ultimately, we don’t just want to produce content, we want to influence processes and business results with support from artificial intelligence.
As purpose-built models evolve, I believe there will be a base set of business insights that are made available across communities of end users, and then an emergence of secondary insights that are developed in a derivative fashion. In this way, rather than try to summit Mount Everest in a direct ascent, we will establish one of more layers of outcomes (analogous to having multiple base camps) that facilitate the eventual goal.
Takeaways
- General purpose AI and large language models (LLMs) will continue to be important and become integrated with how we work and consume technology, but reach a plateau of usefulness fairly rapidly in the next year or so
- Focus will shift towards integrating transactional, contextual, and process data with the intention of predicting business outcomes (causal AI) in a much more targeted way
- The overall mindset will pivot from models that do everything to ones that do something much more specific, with a desired outcome in mind up front
The Role of Compute
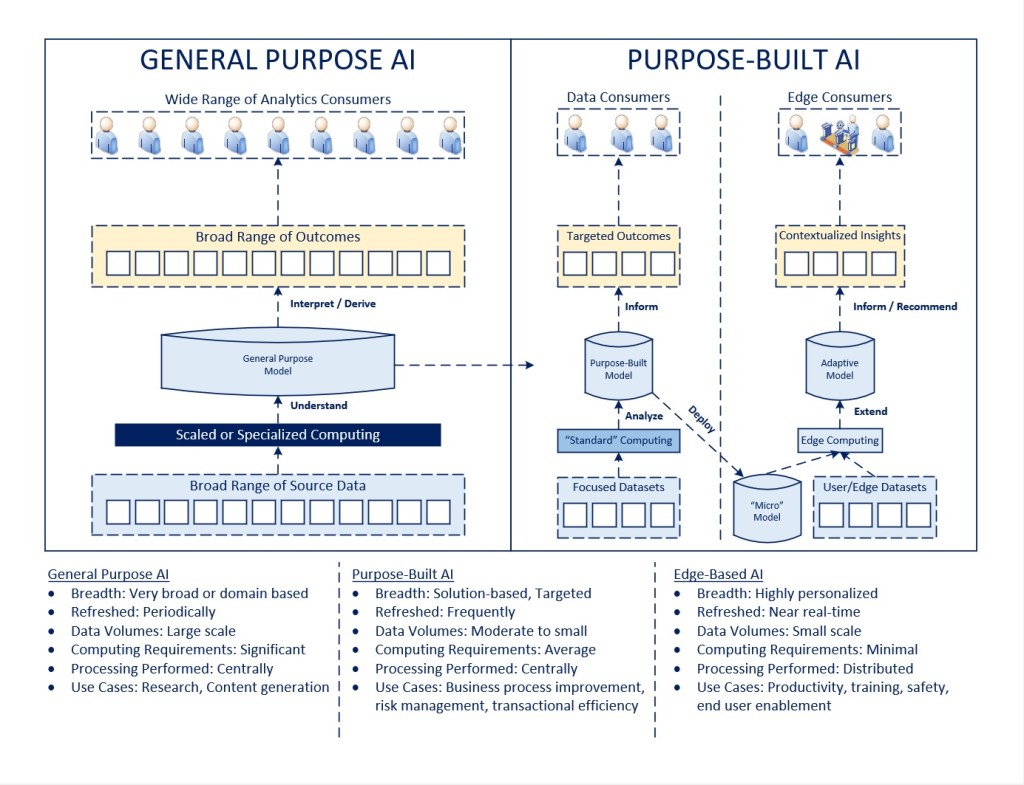
Considering the Spectrum of Needs
Having set the context of general versus purpose-built AI and the desire to move from content to more outcome-focused intelligence, the question is what this means for computing. There is a significant amount of attention going to specialized processors (e.g., GPUs) at the moment, with the presumption that there are significant computing requirements to generate models based on large sets of data in a reasonable amount of time. That being said, while content-focused outcomes may be based on a large volume of data and only need to be refreshed on a periodic basis, the more we want AI to assist in the performance of day-to-day tasks, the more we need the insights to be produced on a near-real time basis and available on a mobile device or embedded on a piece of digital equipment.
Said differently, as our focus shifts to smaller and more specific business problems, so should the data sets involved, making it possible to develop purpose-built models on more “standard” computing platforms that are commercially available, where the models are refreshed on a more frequent basis, taking into account relevant environmental conditions, whether that’s production plans or equipment status in manufacturing, market conditions in financial services, or weather patterns or other risk factors in insurance.
The Argument for a “Micro-Model”
Assuming a purpose-built model can be developed with a particular business outcome or process in mind, where things could take an interesting leap forward would be extending those models into edge computing environments, like a digital worker in a manufacturing facility, where the specific end user knowledge and skills, geo-location, environmental conditions, equipment status could be fed into a purpose-built model and then extended to create a more adaptive model that provides a user-specific set of insights and instructions to drive productivity, safety, and effectiveness.
Ultimately, AI needs to be focused on the individual and run on something as accessible as a mobile device to truly realize it’s potential. The same would also be true for extending models that could be embedded within a piece of industrial equipment to run as part of a digital facility. That is beyond anything we can do today, it makes insights personalized and specific to an individual, and that concept holds a significant amount more business value than targeting a specific user group or persona from an application development standpoint. Said differently, the concept is similar to integrating personalization, workflow, presentation, and insights into one integrated technology.
With this in mind, perhaps the answer will ultimately still result in highly specialized computing, but before rushing in the direction of quantum computing and buying a significant number of GPUs, I’d definitely consider the ultimate outcome we want, which is to put the power of insights in the hands of end users in day-to-day activities, but being much more effective in what they are able to do. That is not a once-a-month refresh of a massive amount of data. It is a constantly evolving model that is based on learnings from the past, but the current realities and conditions of the moment and the specific individual taking action on those things.
Takeaways
- Computing requirements will shift from centralized processing of large data volumes to smaller, curated data sets that are refreshed more often and targeted to specific business goals
- Ultimately, the goal should be to enable end users with a highly personalized model that is focused on them, the tasks they need to accomplish, and the current conditions under which they are operating
- Processing for artificial intelligence will therefore be distributed across a spectrum of environments from large scale centralized methods to distributed edge appliances and mobile devices
Revisiting Data Strategy

Business Implications of AI
The largest risk with artificial intelligence that I see today is no different than anything else in regards to data: the value of new technology is only as good as the underlying data quality, and that’s a business issue (for the most part).
Said differently, in the case of AI, if the underlying data sets upon which models are developed has data quality issues and there is a lack of data management and data governance in place, the inferences drawn will likely be of limited value.
Ultimately, the more we move from general purpose to purpose-built solutions, the ability to identify relevant and necessary data to be incorporated into a model can be a significant accelerator of value. This is because the “give me all the data” approach would likely both increase time to develop and produce models as well as introduce significant overhead in ensuring data quality and governance to confirm the usefulness of the resulting models.
If, as an example, I wanted to use AI to ingest all the training materials developed across a set of manufacturing facilities in the interest of synthesizing, standardizing, and optimizing them across an enterprise, the underlying quality of those materials becomes critically important in deriving the right outcomes. There may be out of date procedures, unique steps specific to a location, quality issues in some of the source content, etc. The technology itself doesn’t solve these issues. Arguably, a level of data wrangling or quality tools could be helpful in identifying and surfacing these issues, but the point is that data governance and curation are required before the infrastructure would produce the desired business outcomes.
Technology Implications of AI
As the diagram intends to indicate, whether AI lives as a set of intelligent agents that run as separate stove pipes in parallel with existing applications and data solutions, the direction for how things will evolve is an important element of data strategy to consider, particularly in a multi-cloud environment (something I’ll address in the final section).
As discussed in The Intelligent Enterprise, I believe that the eventual direction for AI (as we already see somewhat evidenced with Copilot in Microsoft Office 365), is to move from separate agents and data apps (“intelligent agents”) to having those capabilities integrated into the workflow of applications themselves (making them “intelligent applications”), where they can create the most overall value.
What this suggests to me is that transaction data from applications will make its way into models, and be exposed back into consuming applications via AI services. Whether the data ultimately moves into a common repository that can handle both the graph and relational data within the same data solution remains to be seen, but having personally developed an integrated object- and relational-database for a commercial software package thirty years ago at the start of my career, I can foresee that there may be benefits in thinking through the value of that kind of solution.
Where things get more complicated on an enterprise level is when you scale these concepts out. I will address the end user and multi-cloud aspects of this in the next two sections, but it’s critically important in data strategy to consider how too many point solutions in the AI domain could significantly increase cost and complexity (not to mention have negative quality consequences). As data sets and insights are meant to extend outside an individual application to cross-application and cross-ecosystem levels, the ways in which that data is stored, accessed, and exposed likely will become significant. My article on Perspective on Impact-Driven Analytics attempted to establish a layered approach to how to think about the data landscape, from production to consumption, that may provide a starting point for evaluating alternatives in this regard.
Takeaways
- While AI provides new technology capabilities, business ownership / stewardship of data and the processes surrounding data quality, data management, and data governance are extremely critical in an AI-enabled world
- As AI capabilities move within applications, the need to look across applications for additional insights and optimization opportunities will emerge. To the extent that can be designed and architected in a consistent approach, it will be significantly more cost-effective and create more value over time at an enterprise level
- Experimentation is appropriate in the AI domain for the foreseeable future, but it is important to consider how these capabilities will ultimately become integrated with the application and data ecosystems in medium to larger organizations in the interest of getting the most long-term value from the investments
Simplifying “Intelligence”
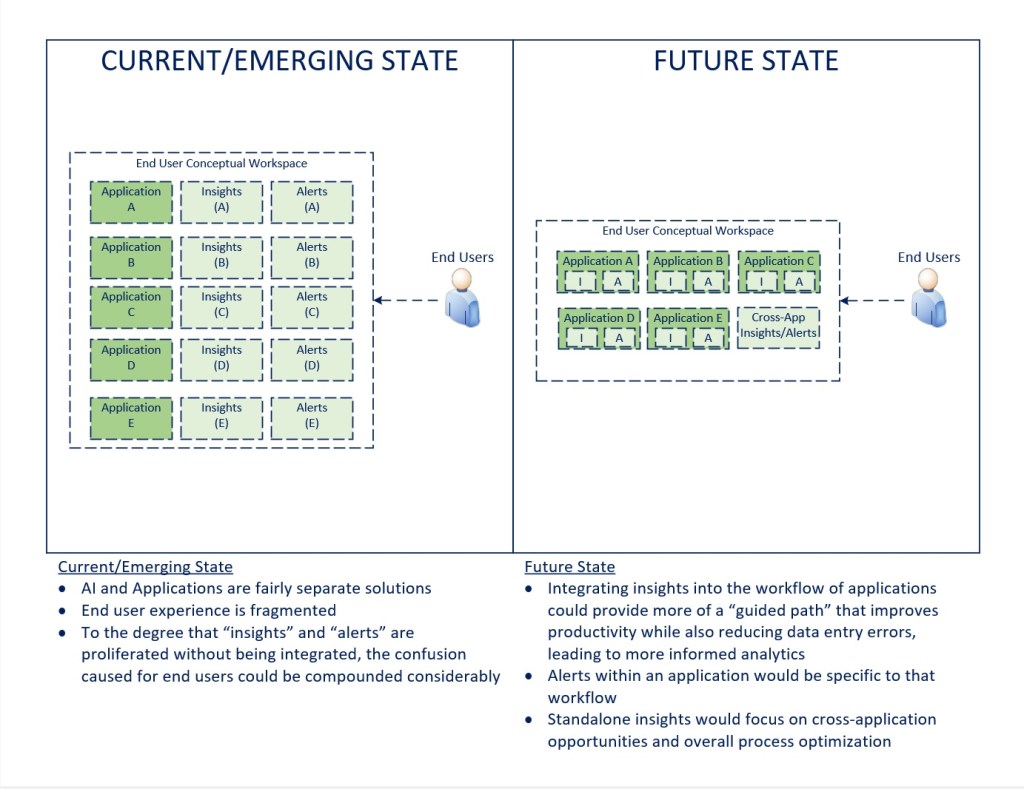
Avoiding the Pitfalls of Introducing New Technologies to End Users
The diagram above is meant to help conceptualize what could ultimately occur if AI capabilities are introduced as various data apps or intelligent agents, running separate from applications versus becoming an integrated part of the way intelligent applications behave over time.
At an overall level, expecting users to arbitrate new capabilities without integrating them thoughtfully into the workflow and footprint that exists creates the conditions for significant change management and productivity issues. This is always true when introducing change, but the expectations associated with the disruptive potential of AI (at the moment) are quite high, and that could set the stage for disappointment if there isn’t a thoughtful design in place for how the solutions are meant to make the consumer more effective on a workflow and task level.
Takeaways
- Intelligence capabilities will move inside applications rather than be adjacent to them, providing more of a “guided path” approach to end users
- To the degree that “micro-models” are eventually in place, that could include making the presentation layer of applications personalized to the individual user based on their profile, experience level, role, and operating conditions
- The role of “Intelligent Agents” will take on a higher-level, cross-application focus, which could be (as an example) optimizing notifications and alerts coming from various applications to a more thoughtful set of prioritized actions intended to maximize individual performance
Thinking About Multi-Cloud

Working Across Environments
With the introduction of AI capabilities at an enterprise level, the challenge becomes how to leverage and integrate these technologies, particularly given that data may exist across a number of hosted and cloud-based environments. For simplicity’s sake, I’m going to assume that any cloud capability required for data management and AI services can be extended to the edge (via containers), though that may not be fully true today.
At an overall level, as it becomes desirable to extend models to include data resident both in something like Microsoft Office 365 (running on Azure) and corporate transactional data (largely running in AWS if you look at market share today), the considerations and costs for moving data between platforms could be significant if not architected in a purposeful manner.
To that end, my suggestion is to look at business needs in one of three ways:
- Those that can be addressed via a single cloud platform, in which case it would likely be appropriate to design and deliver solutions leveraging the AI capabilities available natively on that platform
- To the extent a solution extends across multiple providers, it may be possible to look at layering the solutions such that each cloud platform performs a subset of the analysis, resulting in pre-processed data that could then be published to a centralized, enterprise cloud environment where the various data sets are pulled into a single enterprise model that is used to address the overall need
- If a partitioning approach isn’t possible, then some level of cost, capability, and performance analysis would likely make sense to determine where data should reside to enable the necessary integrated models to be developed
Again, the point is to step back from individual solutions and projects to consider the enterprise strategy for how data will be managed, models will be developed, and deployed overall. The alternative approach of deploying too many point solutions could lead to considerable cost and complexity (i.e., technical debt) over time.
Takeaways
- AI capabilities are already available on all the major cloud platforms. I believe they will reach relative parity from a capability standpoint in the foreseeable future, to the point that they shouldn’t be a primary consideration in how data and models are managed and deployed
- The more the environment can be designed with standards in mind, modularity, integration, interoperability, and a level of composability, the better. Technology solutions will continue to be introduced that an organization will want to leverage without having to abandon or migrate everything that is already in place
- It is extremely probably that AI models will be deployed across cloud platforms, so having a deliberate strategy for how to manage and facilitate this should be given consideration
- A lack of overall multi-cloud strategy will likely create complexity and cost that may be difficult to unwind over time
Wrapping Up
If you’ve made it this far, thank you for taking the time, hopefully some of the concepts were thought provoking. In Excellence by Design, I talk about ‘Relentless Innovation’…
Admittedly, there is so much movement in this space, that it’s very possible some of what I’ve written is obsolete, obvious, far-fetched, or some combination of all of the above, but that’s also part of the point of sharing the ideas: to encourage the dialogue. My experience in technology over the last thirty-two years, especially with emerging capabilities like artificial intelligence, is that we can lose perspective on value creation in the rush to adopt something new and the tool becomes a proverbial hammer in search of a nail.
What would be far better is to envision a desired end state, identify what we’d really like to be able to do from a business capability standpoint, and then endeavor to make that happen with advanced technology. I do believe there is significant power in these capabilities for the organizations that leverage them effectively.
I hope the ideas were worth considering. Thanks for spending the time to read them. Feedback is welcome as always.
-CJG 08/26/2024

2 thoughts on “Exploring Artificial Intelligence”