Overview
I’ve spent a reasonable amount of time in recent years considering data strategy and how to architect an enterprise environment responsive and resilient to change. What’s complicated matters is the many dimensions to establishing a comprehensive data strategy and the pace with which technologies and solutions have and continue to be introduced, none of which appears to be slowing down… quite the opposite. At the same time, the focus on “data centricity” and organizations’ desire to make the most of the insights embedded within and across their enterprise systems has created a substantial pull to drive experimentation and create new solutions aimed at monetizing those insights for competitive advantage. With the recent advent of Generative AI and large language models, the fervor surrounding analytics has only garnered more attention as to the potential it may create, not all to a favorable end.
The problem with the situation is that, not unlike many other technology “gold rush” situations that have occurred over the last thirty-one years I’ve been working in the industry, the lack of structure and discipline (or an overall framework) to guide execution can lead to a different form of technical debt, suboptimized outcomes, and complexity that ultimately doesn’t scale to the enterprise. Hopefully this article will unpack the analytics environment and provide a way to think about the various capabilities that can be brought to bear in a more structured approach, along with the value in doing so.
Ultimately, analytics value is created in insight-driven, orchestrated actions taken, not on presentment or publication of data itself.
Drawing a “Real World” Comparison
The anecdotal hallmark of “traditional business intelligence” is the dashboard, which in many cases, reflects a visual representation of data contained in one or more underlying system, meant to increase end user awareness of the state of affairs, whatever the particular business need may be (this is a topic I’ve peripherally addressed in my On Project Health and Transparency article).
Having leased a new car last summer, I was both impressed and overwhelmed by the level of sophistication available to me through the various displays in the vehicle. The capabilities have come a long way from a bunch of dials on the dashboard with a couple lights to indicate warnings. That being said, there was a simplicity and accessibility to that design. You knew the operating condition of the vehicle (speed, fuel, engine temp, etc.), were warned about conditions you could address (add oil, washer fluid), and situations where expert assistance might be needed (the proverbial “check engine” light).
What impressed me about the current experience design was the level of configurability involved, what I want to see on each of the displays, from advanced operating information, to warnings (exceeding the speed limit, not that this ever happens…), to suggestions related to optimizing engine performance and fuel efficiency based on analytics run over the course of a road trip.
This isn’t very different than the analytics environment available to the average enterprise, the choices are seemingly endless, and they can be quite overwhelming if not managed in some way. The question of modeling the right experience comes down to this: starting with the questions/desired outcome, then working backwards in terms of capabilities and data that need to be brought to bear to address those needs. Historical analytics can feel like it becomes a “data- or source-forward” mental model, when the ideal environment should be defined from the “outcome-backwards”, where the ultimate solution is rooted in a problem (or use case) meant to be solved.
Where Things Break Down
As I stated in the opening, the analytics landscape has gotten extremely complex in recent years and seemingly at an increasing pace. What this can do, as is somewhat the case with large language models and Generative AI right now, is create a lot of excitement over the latest technology or solution without a sense of how something can be used or scaled within and across an enterprise. I liken this to a rush to the “cool” versus the “useful”, and it becomes a challenge the minute it becomes a distraction from underlying realities of the analytics environment.
Those realities are:
- Business ownership and data stewardship are critical to identifying the right opportunities and unlocking the value to be derived from analytics. Technology is normally NOT the underlying issue in having an effective data strategy, though disciplined delivery can obviously be a challenge depending on the capabilities of the organization
- Not all data is created equal, and it’s important to discriminate in what data is accessed, moved, stored, curated, governed… because there is a business and technology cost for doing so
- Technologies and enabling capabilities WILL change, so the way they are integrated and orchestrated is critically important to leveraging them effectively over time
- It is easy to develop solutions that solve a specific need or use case but not to scale and integrate them as enterprise-level solutions. In an Intelligent Enterprise, this is where orders of magnitude in value and longer-term competitive advantage is created, across digitally connected ecosystems (including those with partners), starting with effective master data management and extending to newer capabilities that will be discussed below
At an overall level, while it’s relatively easy to create high-level conceptual diagrams or point solutions in relation to data and analytics, it takes discipline and thought to architect an environment that will produce value and agility at scale… that is part of what this article is intended to address.
Thoughts on “Data Centricity”
Given there is value to be unlocked through an effective data strategy, “data centricity” has become fairly common language as an anchor point in discussion. While I feel that calling attention to opportunity areas can be healthy and productive, there is also a risk that concepts without substance (the antithesis of what I refer to as “actionable strategies”) can become more of a distraction than a facilitator of progress and evolution. A similar situation arguably exists with “zero trust” right now, but that’s a topic worthy of its own article at a future date.
In the case of being “data centric”, the number of ways the language can be translated has seemed problematic to me, largely because I fundamentally believe data is only valuable to the extent it drives a meaningful action or business outcome. To that end, I would much rather be “insight-centric” or “value-focused”, “action-oriented”, or some other phrase that leans towards what we are doing with the data we acquire and analyze, not the fact that we have it, can access, store, or display it. Those things may be part of the underlying means to an end, but they aren’t the goal in itself, and place emphasis on the road versus the destination of a journey.
To the extent that “data centricity” drives a conversation on what data a business has that may, if accessed and understood, create value, fuel innovation, and provide competitive advantage, I believe there is value in pursuing it, but a robust and thoughtful data strategy requires end-to-end thinking at a deeper level than a catch phrase or tagline on its own.
What “Good” Looks Like
I would submit that there are two fundamental aspects of having a robust data strategy once you address business ownership and stewardship as a foundational requirement: asking the right questions, and architecting a resilient environment.
Asking the Right Questions
Arguably the heading is a bit misleading here, because inference-based models can suggest improvements to move from an existing to a desired state, but the point is to begin with the problem statement, opportunity, or desired outcome, and work back to the data, insights, and actions required to achieve that result. This is a business-focused activity and is, therefore, why establishing ownership and stewardship is so critical.
“We can accomplish X if we optimize inventory across Y locations while maintaining a fulfillment window of Z”
The statement above is different than something more “traditional” in the sense of producing a dashboard that shows “inventory levels across locations”, “fulfillment times by location”, etc. that then is intended to inform someone who ultimately may make a decision independent of secondary impacts or, better yet, recommends or enables actions to keep the inventory ecosystem calibrated in a dynamic way that continuously recalibrates to changing conditions, within defined business constraints.
While the example itself may not be perfect, the point is whether we think about analytics as presentment-focused or outcome-focused. To the degree we focus on enabling outcomes, the requirements of the environment we establish will likely be different, more dynamic, and more biased towards execution.
Architecting a Resilient Environment
With the goals identified, the technology challenge becomes about enabling those outcomes, but architecting an environment that can and will evolve as those needs change and as the underlying capabilities continue to advance in what we are able to do in analytics as a whole.
What that means, and the next section will explore, is having a structured and layered approach so that capabilities can be applied, removed, and evolved with minimal disruption to other aspects of the overall environment. This is, at its essence, a modular and composable architecture that enables interoperability through standards-based interaction across the layers of the solution in a way that will accelerate delivery and innovation over time.
The benefit to designing an interoperable environment is simple: speed, cost, and value. As I mentioned in where things tend to break down, in technology, there should always a bias towards rapid delivery. That being said, focusing solely on speed can tend to create a substantial amount of technical debt and monolithic solutions that don’t create cumulative or enterprise-level value. Short-term, they may produce impact, but medium- to longer-term, they make things considerably worse once they have to be maintained and supported and the costs for doing so escalate. Where a well-designed environment can help is in creating a flywheel effect over time to accelerate delivery using common infrastructure, integration standards, and frameworks so that the distance between idea and implementation is significantly reduced.
Breaking Down the Environment
The following diagram represents the logical layers of an analytics environment and some of the solutions or capabilities that can exist at each tier. While the diagram could arguably be drawn in various ways, the reason I’ve drawn it like this is to show the separation of concerns between where content and data originates and ultimately where it’s consumed, along with the layers of processing that can occur in between.
Having the separation of concerns defined and standards (and reference architecture) established, the ability to scale, integrate new solutions and capabilities over time, and retire or modernize those that don’t create the right level of value, becomes considerably easier than when analytics solutions are purpose built in an end-to-end manner.
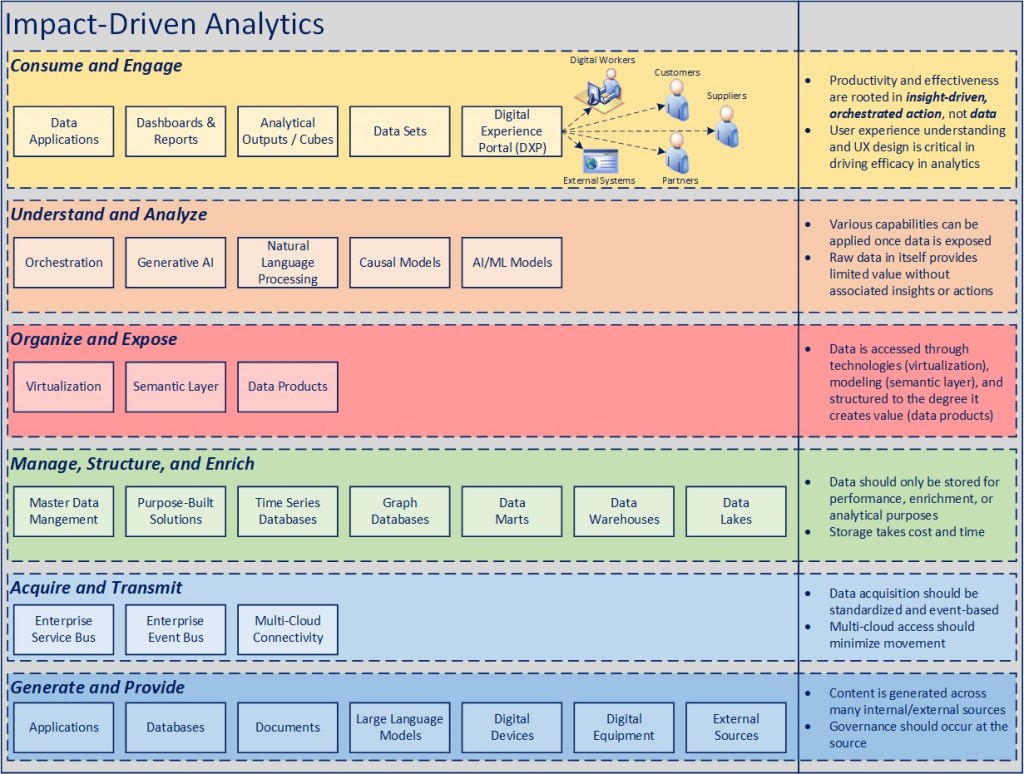
The next section will elaborate on each the layers to provide more insight on why they are organized in this manner.
Consume and Engage
The “outermost” tier of the environment is the consumption layer, where all of the underlying analytics capabilities of an organization should be brought to bear.
In the interest of transforming analytics, as was previously mentioned in the context of “data centricity”, the dialogue needs to move from “What do you want to see?” in business terms to “What do you want to accomplish and how do you want that to work from an end user standpoint?”, then employing capabilities at the lower level tiers to enable that outcome and experience (both).
The latter dimension is important, because it is possible to deliver both data and insights and not enable effective action, and the goal of a modern analytics environment is to enable outcomes, not a better presentment of a traditional dashboard. This is why I’ve explicitly called out the role of a Digital Experience Platform (DXP) or minimally an awareness of how end users are meant to consume, engage, and interact with the outcome of analytics, ideally as part of an integrated experience that enables or automates action based on the underlying goals.
As analytics continue to move from passive and static to more dynamic and near real-time solutions, the role of data apps as an integrated part of applications or a digital experience for end users (internal or external) will become critical to delivering on the value of analytics investments.
Again, the requirements at this level are defined by the business goals or outcomes to be accomplished, questions to be answered, user workflows to be enabled, etc. and NOT the technologies to be leveraged in doing so. Leading with technologies is almost certainly a way to head down a path that will fail over time and create technical debt in the process.
At an overall level, the reason for separating consumption and thinking of it independent of anything that “feeds” it, is that, regardless of how good the data or insights produced in the analytics environment are, if the end user can’t take effective action upon what’s delivered, there will be little value created in the solution.
Understand and Analyze
Once the goal is established, the capabilities to be brought to bear becomes the next level of inquiry:
- If there is a set of activities associated with this outcome that requires workflow, rules, and process automation, orchestration should be integrated into the solution
- If defined inputs are meant to be processed against the underlying data and a result dynamically produced, this may be a case where a Generative AI engine could be leveraged
- If natural language input is desired, a natural language processing engine should be integrated
- If the goal is to analyze the desired state or outcome against the current environment or operating conditions and infer the appropriate actions to be taken, causal models and inference-based analytics could be integrated. This is where causal models take a step past Generative AI in their potential to create value at an enterprise level, though the “describe-ability” of the underlying operating environment would likely play a key role in the efficacy of these technologies over time
- Finally, if the goal is simply to run data sets through “traditional” statistical models for predictive analytics purposes (as an example), AI/ML models may be leveraged in the eventual solution
Having referenced the various capabilities above there are three important points to understand in why this layer is critical and separated from the rest:
- Any or all of these capabilities may be brought to bear, regardless of how they are consumed by an end user, and regardless of how the underlying data is sourced, managed, and exposed.
- Integrating them in ways are standards-based will allow them to be applied as and when needed into various solutions to create considerable cumulative analytical capability at an enterprise level
- These capabilities definitely WILL continue to evolve and advance rapidly, so thinking about them in a plug-and-play based approach will create considerable organizational agility to respond and integrate innovations as and when they emerge over time, which translates into long-term value and competitive advantage.
Organize and Expose
There are three main concepts I outlined in this tier of the environment:
- Virtualization – how data is exposed and accessed from underlying internal and external solutions
- Semantic Layer – how data is modeled for the purpose of allowing capabilities at higher tiers to analyze, process, and present information at lower levels of the model
- Data Products – how data is packaged for the purposes of analysis and consumption
These three concepts can be implemented with one or more technologies, but the important distinction being that they offer a representation of underlying data in a logical format that enables analysis and consumption, not necessarily that they are a direct representation of the source data or content itself.
With regard to data products in particular, while there is a significant amount of attention paid to their identification and development, they represent marginal value in an overall data strategy, especially when analytical capabilities and consumption models have evolved to such a great degree. Where data products should be a focus (as a foundational step) is where the underlying organization and management of data is in such disarray that an examination of how to restructure and clean up the environment is important to reducing the chaos that exists in the current state. What that implies, however, is less distractions and potential technical debt by extension, but not the kind of competitive advantage that comes from advanced capabilities and enabled consumption. The other scenario where data products create value in themselves is when they are packaged and marketed for external consumption (e.g., credit scores, financial market data). It’s worth noting in this case, however, that the end customer is assuming the responsibility of analyzing, integrating, and consuming those products as they are not an “end” in themselves in an overall analytics value chain.
Manage, Structure, and Enrich
While I listed a number of different types of solutions that can comprise a “storage” layer in the analytics environment, the best-case scenario would be that it doesn’t exist at all. Where the storage layer creates value in analytics is providing a means to map, associate, enrich, and transform data in ways that would be too time consuming or expensive to do “on the fly” for the purposes of feeding the analytics and consumption tiers of the model. There is certainly value, for instance, in graph databases for modeling complex many-to-many relationships across data sets, marts and warehouses for dealing with structured data, and data lakes for archival, managing unstructured data, and training of analytical models, but where source data can be exposed and streamed directly to the downstream models and solutions, there will be lower complexity, cost, and latency in the overall solution.
Acquire and Transmit
As capabilities continue to advance and consumption models mature, the desire for near real-time analytics will almost certainly dominate the analytics environment. To that end, leveraging event-based processing, whether through an enterprise service or event bus, will be critical. To the degree that enterprise integration standards can be leveraged (and canonical objects, where defined), further simplification and acceleration of analytics efforts will be possible.
Given the varied capabilities across cloud platforms (AWS, Azure, and GCP), not to mention the probability that data will be distributed between enterprise systems that could be hosted in a different cloud platform than its documents (as those in Office 365), the ability to think critically about how to integrate and synthesize across platforms is also important. Without a defined strategy for managing multi-cloud in this domain in particular, costs for egress/ingress of data could be substantial depending on the scale of the analytics environment itself, not to mention the additional complexities that would be introduced into governance and compliance efforts surrounding duplicated content across cloud providers.
Generate and Provide
The lowest tier of the model is the simplest to describe, given it’s where data and content originate, which can be a combination of applications, databases, digital devices and equipment, and so forth, internal and external to an organization. Back to the original point on business ownership and stewardship of data, if the quality of data emanating from these sources isn’t managed and governed, everything downstream will bear the fruit of the poisoned tree depending on the degree of issues involved.
Given the amount of attention given to large language models and GenAI right now, I thought it was worth noting that I consider these as another form of content generation more logically associated with the other types of solutions at this tier of the analytics model. It could be the case that generated content makes its way through all the layers as a “data set” delivered directly to a consumer in the model, but by orienting and associating it with the rest of the sources of data, we create the potential to apply other capabilities at the next tiers of processing to that generated content, and thereby could enrich, analyze, and do more interesting things with it over time.
Wrapping Up
As I indicated at the opening, the modern analytics environment is complex and highly adaptive, which presents a significant challenge to capturing the value and competitive advantage that is believed to be resident in an organization’s data.
That being said, through establishing the right level of business ownership, understanding the desired outcomes, and applying disciplined thinking in how an enterprise environment is designed and constructed, there can be significant and sustainable value created for an enterprise.
I hope the ideas were thought provoking. I appreciate those taking the time to read them.
-CJG 07/27/2023

2 thoughts on “Perspective on Impact-Driven Analytics”